Loading and Unloading Data and Definitions
Mimer SQL provides you with flexible methods for loading information to and from databases using the LOAD and UNLOAD commands and the MIMLOAD program.
LOAD and UNLOAD can be used with Mimer SQL from any ODBC based SQL command interpreter.
Using the LOAD command, you can:
•load information from one or more files into a Mimer SQL database
•optimize loading for best performance
•select exactly the information you want and place it precisely where you want it using an SQL statement
•log the load operation.
Using the UNLOAD command, you can:
•customize the information – unload whole databanks or select specific information using an SQL statement
•log the unloading operation.
Using the MIMLOAD program, you can use LOAD and UNLOAD directly from your operating system command prompt. Using the STDIN, STDOUT and STDERR options in the LOAD/UNLOAD syntax, you can enable command line file redirection for input, output and logging.
MIMLOAD - Data Load and Unload
MIMLOAD enable you to use the LOAD and UNLOAD commands at your operating system’s command prompt.
You control MIMLOAD using flagged information specified on the command-line.
The overall syntax for MIMLOAD (expressed in short form Unix-style) is:
mimload [-s] [-u user] [-p pass] [-e prog] [-i pass]] command [database]
mimload [--single] [--username=user] [--password=pass]
[--program=prog] [--using=pass]] command [database]
mimload [-v|--version] | [-?|--help]
Note:If you are using double quotes in the LOAD/UNLOAD statement, they must be escaped using the back-slash character \ when Unix-style switches are used. For VMS-style switches, a double quote " is used as escape character.
You can use the following arguments with MIMLOAD.
|
Unix/Windows-style |
VMS-style |
Function |
|---|---|---|
|
-e program --program=program |
/PROGRAM=program |
Specifies an optional program ident, to be entered in the connection phase. This can be specified more than once and thus allows entering deeper entry levels. |
|
-i password --using=password |
/USING=password |
Password for the program ident specified by the preceding --program switch. |
|
-p password --password=password |
/PASSWORD=password |
Specifies the password for the user. When connecting using an OS_USER login, no password is needed. Note that in an Open VMS environment it might be necessary to enclose the password in quotation marks as the value otherwise is translated to lower case. |
|
-u user --username=username |
/USERNAME=username |
Specifies the username used when connecting to Mimer. If not specified, OS_USER login is assumed. |
|
command |
command |
The LOAD/UNLOAD statement to be used for data management. Enclose in double quotes. See LOAD - Loading Data and UNLOAD - Unloading Data for details. |
|
database |
database |
Specifies the name of the database to access. If specified, it must be the last argument. If you do not specify a database name, the default database will be used. |
|
-? --help |
/HELP |
Show help text. |
The following error codes are used:
|
Linux/Windows |
OpenVMS |
Usage |
|---|---|---|
|
0 (success) |
1 (success) |
This code is used when MIMLOAD has executed successfully. |
|
> 1 (error) |
2 (error) |
This error code is used when MIMLOAD failed to execute successfully. |
Loading Data
The following example loads the file store.sql into the default database.
Unix/Windows-style
mimload --username=user1 --password=UsrPwd "load from 'store.sql' log stderr"
VMS-style
MIMLOAD /USERNAME=USER1 /PASSWORD="UsrPwd" "LOAD FROM 'STORE.SQL' LOG STDERR"
Unloading Data
'The following example unloads all the definitions and data owned by the user store_adm from the database store to the file store.sql.
Unix/Windows-style
mimload -u store_adm -p StrPwd "unload to 'store.sql' from current user" store
VMS-style
MIMLOAD /USERNAME=STORE_ADM /PASSWORD="StrPwd" "UNLOAD TO 'STORE.SQL' FROM CURRENT USER" STORE
STDIN, STDOUT and STDERR are short names for the standard input, standard output and standard error streams, respectively.
Windows/Unix-style Examples
In the commands below, STDIN is denoted by '<' (this is short for '0<', equal to reading from file descriptor number 0 which is the standard input). STOUT is denoted by '>' (this is short for '1>', equal to writing to file descriptor number 1 which is the standard output) and STDERR is denoted by '2>' (equal to writing to file descriptor number 2 which is the standard error).
In the following example, the generated output from UNLOAD is written to standard output, which in this case is redirected to the file store_db.unl. The log information is written to standard error, which is redirected to the file store_db.log.
mimload -u store_adm -p StrPwd "unload to stdout log stderr from databank store_db" store > store_db.unl 2> store_db.log
In the following example, input to LOAD is taken from standard input, i.e. from the file store_db.unl, and log information is written to standard error, in this case to the file store_db_load.log.
mimload -u store_adm -p StrPwd "load from stdin log stderr" store < store_db.unl 2> store_db_load.log
VMS-style Examples
In the OpenVMS environment, you can use STDIN, STDOUT and STDERR in two ways, either by defining SYS$INPUT, SYS$OUTPUT and SYS$ERROR or by using pipe mode which gives the Linux behavior for use of file redirection. Both methods are shown below.
In the following example, the generated output from UNLOAD is written to standard output, which in this case is redirected to the file D1:<DATA>STORE_DB.UNL. The log information is written to standard error, which is redirected to the file D1:<LOG>STORE_DB.LOG.
Example using SYS$OUTPUT and SYS$ERROR:
DEFINE/USER SYS$ERROR D1:<LOG>STORE_DB.LOG
DEFINE/USER SYS$OUTPUT D1:<DATA>STORE_DB.UNL
MIMLOAD /USERNAME=STORE_ADM /PASSWORD="StrPwd" "UNLOAD TO STDOUT LOG STDERR FROM DATABANK STORE_DB" STORE
Example using pipe mode:
PIPE MIMLOAD /USERNAME=STORE_ADM /PASSWORD="StrPwd" "UNLOAD TO STDOUT LOG STDERR FROM DATABANK STORE_DB" STORE > D1:<DATA>STORE_DB.UNL 2> D1:<LOG>STORE_DB.LOG
In the following example, input to LOAD is taken from standard input, i.e. from the file D1:<DATA>STORE_DB.UNL, and log information is written to standard error, in this case to the file D1:<LOG>STORE_DB_LOAD.LOG.
Example using SYS$OUTPUT and SYS$ERROR:
DEFINE/USER SYS$ERROR D1:<LOG>STORE_DB_LOAD.LOG
DEFINE/USER SYS$INPUT D1:<DATA>STORE_DB.UNL
MIMLOAD /USERNAME=STORE_ADM /PASSWORD="StrPwd" "LOAD FROM STDIN LOG STDERR" STORE
Example using pipe mode:
PIPE MIMLOAD /USERNAME=STORE_ADM /PASSWORD="StrPwd" "LOAD FROM STDIN LOG STDERR" STORE < D1:<DATA>STORE_DB.UNL 2> D1:<LOG>STORE_DB_LOAD.LOG
You load definitions and/or data into a Mimer SQL database using the LOAD statement.
The LOAD command has the following syntax:
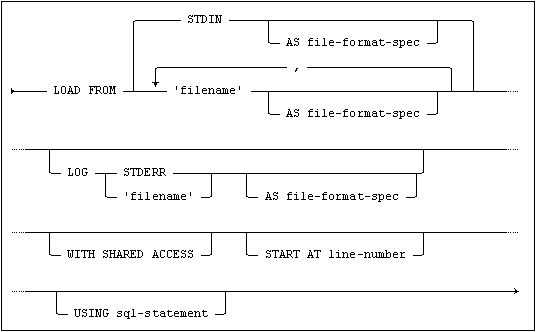
where file-format-spec is:
Usage
MIMLOAD, or with any ODBC-based SQL interpreter.
For information on MIMLOAD, see MIMLOAD - Data Load and Unload.
Description
The LOAD command copies definitions and/or data from one or more files. When loading information from more than one file, the files are read in the order defined. The input file(s) are expected to form a valid sequence of definitions, data descriptions and data.
Triggers defined against the affected tables are applied when the data is loaded.
When a file contains data for more than one table, the data for each table must be contained in a section that is introduced by a data description header. For more information, see Data Description Headers and Files.
If the data in the file does not have a data description header, there must be a data description file that contains the header information.
This means that the file can only contain data from one table. Data description files and data files can of course be concatenated into a single file containing data for several tables.
A definition file contains definition statements to create objects. A definition file can, for example, be divided into two files where one file is place first in the file list; i.e. executed before any data is loaded, and the other file is placed at the end of the file list, i.e. executed after the data is loaded.
An example file sequence can be as follows: first in the file list, a file that contains object definitions; second, a file that describes the data to be loaded (the information in this file is equal to the corresponding information that can be given as a header in the data file); third, the data file; and fourth, a second definition file including referential constraints and triggers.
You can specify the name of the table into which the information shall be loaded in the data file header(s) or the data description file. The default is the table name from which the data was unloaded.
When LOAD scans a file, it detects if a field uses a text qualifier by checking if the first character in the field is a text qualifier. If a text qualifier character is found in the field data, the character is doubled, i.e if the text qualifier is a double quote, the data ab'c is equal to the data 'ab''c'.
The STDIN Option
When you use the STDIN option, input is read from the standard input stream. See Using STDIN/STDOUT/STDERR.
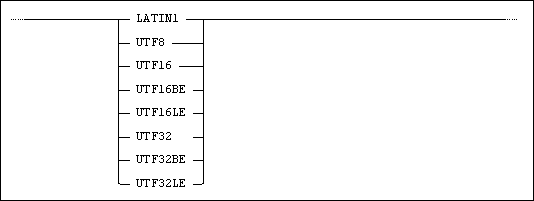
By using the AS option together with a filename specification, you can specify the character set used by the file to be loaded.
The character sets available are: LATIN1, UTF8, UTF16, UTF16BE, UTF16LE, UTF32, UTF32BE and UTF32LE.
UTFxxBE and UTFxxLE means UTFxx format with big or little endian byte order. UTFxx without endian notion means that the common endian for the current platform is assumed.
The default character set used, if you do not use the AS option, is the default used in your host operating system.
For more information, see File Format Specifications.
You can specify the log file using LOG. This log file will include warnings and progress information about the load operation. If you do not use the LOG option, logging will be written to the standard error stream.
The STDERR Option
When you specify LOG STDERR, informational messages are written to the standard error stream. See Using STDIN/STDOUT/STDERR.
LOAD’s default behavior implies that you have exclusive access to the databank being loaded with data. If you need shared access, you can use the WITH SHARED ACCESS option. In most cases, this will lead to a slower data load using row-wise insert.
By default, LOAD uses a fast data load facility to increase performance. The alternative is to insert data row-wise as if using an SQL INSERT statement.
LOAD uses the fast data load facility in most cases, but there are some situations that need row-wise insertion due to certain referential constraints. In such cases, a warning message will tell you that fast data load cannot be used and the operation will continue using row-wise insertions.
When row-wise insertions are performed, loads are recorded in LOGDB (assuming the databank is defined with the LOG option).
You can use the START AT option to restart a failed load operation.
The START AT value can be set to a line where a data definition statement is located or a data descriptor header starts (#data).
The USING option enables you to use an SQL statement to specify the information to be loaded and the target for the information.
The SQL statements you can use are: INSERT, UPDATE, DELETE or CALL to a procedure with input parameter markers only.
The following example is a straightforward import of the input file, using default options:
LOAD FROM 'table_t.data' LOG 'table_t.log';
The following example imports a data file, preceded by a data description file, using the default options:
LOAD FROM 'table_t.desc', 'table_t.data' LOG 'table_t.log';
The following example imports the first four columns of data in the file to the table named details from a file in UTF16 format:
LOAD FROM 'table_t.data' AS UTF16
LOG 'table_t_dataload.log'
USING INSERT INTO details VALUES (?,?,?,?);
The following example uses an UPDATE statement where the first column C1 and the second column C2 of the data input file are used:
LOAD FROM 'table_t.data' AS UTF16
LOG 'table_t_dataload.log'
USING UPDATE details SET c1=? WHERE c2=?;
The following example uses a DELETE statement where the input data is used to qualify records to delete:
LOAD FROM 'table_t.data' AS UTF16
LOG 'table_t_dataload.log'
USING DELETE FROM details WHERE c2=? AND c3=?;
You use the UNLOAD command to unload data and/or definitions from a Mimer SQL database to a file.
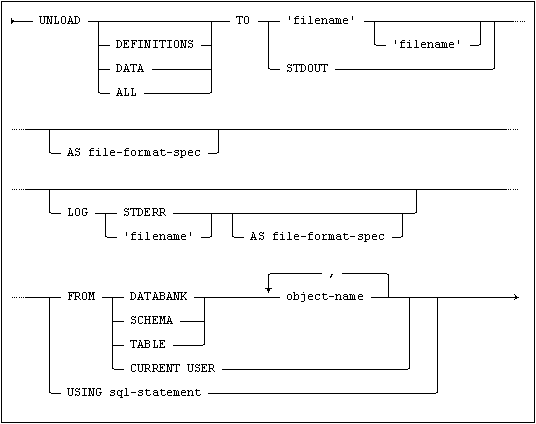
where file-format-spec is:
Usage
Any ODBC-based SQL interpreter or with the MIMLOAD program.
For information on MIMLOAD, see MIMLOAD - Data Load and Unload.
Description
The UNLOAD command generates data and/or definitions and places the result in a file.
If one file is specified in the UNLOAD command, both data and definitions will be placed in that file. If two files are specified, definitions will be placed in the first file, and data in the second file. (This makes it easier to change the table name before creating and loading the table.)
You can use the options ALL (default), DEFINITIONS or DATA to specify the information you want.
When generating the data and definitions, a data description header is created before information is written to the file. If information from several tables is generated, a data description header for each data section is created.
A data description header contains escaping information and column separator information. For more information, see Data Description Headers and Files.
Data Escape Mode
UNLOAD generates data in escaped mode. This means that the data description header includes the data escape mode option.
When using data escape mode, the following characteristics are enabled, from the UNLOAD perspective:
•Data from a specific table is ended by the escape sequence '\_' to mark end-of-table.
•Null values are indicated by the escape sequence '\-'.
•BLOB and BINARY columns are unloaded in HEX code with a leading '\x' escape sequence for each byte.
•BLOB, CLOB and NCLOB columns are unloaded so that the value length is given in front of the value as in the following CLOB example: '11:Abracadabra'
•For CHAR, NCHAR, CLOB and NCLOB columns, the escape sequence '\x' is used only when there is binary data, such as ISO control codes, new-line characters, etc. in the data.
•The '\u' escape sequence is used only when Unicode data is to be written to Latin1 files.
For information on escape sequences, see Escape Character Sequences.
The STDOUT Option
When you use the STDOUT option, generated output is written to the standard output stream. See Using STDIN/STDOUT/STDERR.
By using the AS option together with a filename specification, you can select the character set of the generated file. You can choose: LATIN1, UTF8, UTF16, UTF16BE, UTF16LE, UTF32, UTF32BE or UTF32LE.
UTFxxBE and UTFxxLE means UTFxx format with big or little endian byte order. UTFxx without endian notion means that the common endian for the current platform is assumed.
The character set used, if you do not use the AS option, is UTF8 with BOM.
For more information, see File Format Specifications.
You can generate a log of the operation using the LOG option. The log file will include warnings and progress information about the operation. If you do not use the LOG option, logging will be written to the standard error stream.
The STDERR Option
When you use the LOG STDERR option, informational messages are written to the standard error stream. See Using STDIN/STDOUT/STDERR.
To specify the information to be unloaded, you use the USING or FROM options.
With the USING option, an SQL statement, such as SELECT * FROM T1; or a CALL to a procedure with parameter markers (?) for output parameters only, can be used to specify the source.
By using an SQL statement to form the source for the export operation, there are many possibilities available to format and customize the output.
With the FROM option, one or several databanks, tables or schemas can be used to form the source for the export operation. If using the FROM CURRENT USER option, the current ident is exported.
If tables are joined in the SQL statement used, and definitions are generated, a new table that is a reflection of the result of the join is defined. The default name of the new table is table1.
Error Management
The UNLOAD command runs until a major error is encountered. Minor problems are reported as warnings if LOG is enabled. If a fatal error occurs, an error message is displayed and the operation is aborted.
The following example will export the table details, with all related definitions, to a file:
UNLOAD DEFINITIONS TO 'table_t.def' FROM TABLE details;
The following example will export the CREATE statement for table details together with all data in the table to a file in UTF16 format. A log file is used:
UNLOAD TO 'table_t.all' AS UTF16
LOG 'table_t.log'
USING SELECT * FROM details;
The following example will export the CREATE statement for table details to the definitions file createtable.dat, and its data to another file tabledata.dat:
UNLOAD ALL TO 'createtable.dat', 'tabledata.dat' FROM TABLE details;
Data Description Headers and Files
Data description headers and files are used to describe the data that follows.
The following table describes data description header elements:
|
Element |
Usage |
Description |
|---|---|---|
|
#data |
Required |
Data description header start identifier. |
|
escape mode |
Optional |
Indicates that the data is escaped, i.e. that some elements of the data are tagged for secure recognition at LOAD. See the table below. When using UNLOAD, data escape mode is always used. |
|
column separator 'x' |
Optional |
Indicates which character is the column separator when reading the data. The default is the comma character (,). If this option is not used, LOAD assumes that the comma character is the column separator. |
|
text qualifier 'x' |
Optional |
Indicates which character is the qualifier for text strings in the data. The default is the double quote character ("). If this option is not used, LOAD assumes the double quote character as the text qualifier or unqualified data. |
|
null indicator 'x' |
Optional |
Indicates which character is the null value if found in a data field. If this option is not stated, LOAD assumes the empty string, i.e. two consecutive column separators, as a null value. In data escape mode, '\-' is treated as the null value. |
|
using insert-statement |
Optional |
The SQL INSERT statement that indicates where, and in what way, data should be loaded. This statement is used in the situation where the LOAD statement itself does not include a USING clause. |
|
; |
Required |
Data description header end identifier. |
As shown in the table above, the characters used to specify column separators, text qualifiers and null indicators must be enclosed in single quotes. If you use a single quote to specify a column separator, text qualifier or null indicator, you must enter it twice, for example, you would specify a single quote as a column separator as ''''.
Data Description Header Examples
For data unloaded from a Mimer SQL database using UNLOAD, the data description header generated could look as follows:
#data escape mode using insert into t (c) values (?);
The example above implies the following for LOAD:
•The column separator is the comma character (default).
•Text strings are presumed to be unqualified or qualified with the double quote character.
•Data escaping is assumed (see the table below).
•The USING statement in the header will be used if no USING clause is given in the LOAD statement.
The following is another example of a data description header where all optional elements mentioned above, except data escape mode, are used:
#data
column separator ':'
text qualifier '!'
null indicator '§'
using insert into t1 (c1,c2,c3) values (?,?,?);
In the example above, the table t1 and the columns c1, c2 and c3 are supposed to exist when starting the data load. Specific characters for column separator, text qualifier and null indicator are defined.
If data escape mode is specified, the back-slash character (\) is used as the escape character. The character following the escape character can be one of 'x', 'u', '-' or '_'. See the following table for a description of valid escape character sequences:
|
Escape character sequence |
Usage Description |
Example |
|---|---|---|
|
\x (lower case letter 'x') |
Preceding a hexadecimal byte value. A HEX value is assumed to be two HEX value digits, i.e. 0-F. |
\x1A |
|
\u (lower case letter 'u') |
Preceding a unicode value. A Unicode value is assumed to be eight HEX value digits, i.e. 0-F. |
\u12345678 |
|
\- (dash) |
Null value |
\- |
|
\_ (underscore) |
End of table, including end of stream or file |
\_ |
Note:If you do not use data escape mode, end of file is treated as end of table. This means that such a data file only can contain data for one table.
The default UNLOAD file format is utf8, which LOAD handles without having to specify it. This means that in most cases you don't need to specify the file format, if you don't do it at UNLOAD you don't have to do it at LOAD either.
The various file formats that can be used are briefly described in the following table:
|
File Format |
Description |
|---|---|
|
latin1 |
ISO 8859-1, i.e. ISO's 8-bit single-byte coded graphic character set for Western languages. |
|
utf8 |
Unicode Transformation Formats, standard character encoding schemes in accordance with ISO 10646. For more information, see https://www.unicode.org |
|
utf16be |
UTF16 format with big endian byte order. |
|
utf16le |
UTF16 format with little endian byte order. |
|
utf32be |
UTF32 format with big endian byte order. |
|
utf32le |
UTF32 format with little endian byte order. |