In previous chapters, we discussed the ODBC and JDBC APIs. This chapter discusses the scope, principles, processing and structure of embedded SQL (ESQL).
ESQL enables you to code SQL statements in a host program written in C/C++, COBOL or Fortran. You can specify SQL statements directly in the host program's source code. However, because the host language's compiler won't recognize the SQL statements as valid, a preprocessor is required.
The Scope of Embedded Mimer SQL
The following groups of SQL statements are common to ESQL and interactive SQL:
•Data manipulation statements for reading or changing the contents of the database and invoking stored routines. These are basically similar between interactive SQL and ESQL, but differ in certain details as a result of the different environments in which the statements are used.
•Transaction control statements for grouping database operations in transactions (indivisible units of work).
•Access control statements for allocating privileges and access rights to users of the system. These are identical between interactive SQL and ESQL.
•Data definition statements for creating and altering objects in the database. These are identical between interactive SQL and ESQL.
•Connection statements for identifying the current user of the system.
•System administration statements for controlling the availability of the database and its physical components, managing backups and updating database statistics.
There are a number of commands provided for use with BSQL which are not included in the Mimer SQL interface, these are described in the Mimer SQL User's Manual, Mimer BSQL.
Note:In the Mimer SQL Reference Manual, Usage Modes, Mimer SQL statements are identified as valid for use in ESQL, for interactive use or both.
General Principles for Embedding SQL Statements
The following sections discuss host languages, preprocessors, identifying SQL statements, code, comments and recommendations.
You can embed Mimer SQL statements in application programs written in C/C++, COBOL or Fortran. The basic principles for writing ESQL programs are the same in all languages and all ESQL statements are embedded in the same way.
Information given in this manual applies to all languages unless otherwise explicitly stated. Language-specific information is detailed in Host Language Dependent Aspects.
ESQL Preprocessors
Because host language compilers do not recognize ESQL statements as valid, an ESQL preprocessor is required. An ESQL preprocessor processes the SQL statements embedded in a host language.
|
Linux:Mimer SQL supports an ESQL preprocessor for the C/C++ host language on Linux platforms. In addition Fortran is supported on Linux platforms. |
|
VMS:Mimer SQL supports an ESQL preprocessor for the C/C++, COBOL and Fortran host languages on OpenVMS platforms. |
|
Win:Mimer SQL supports an ESQL preprocessor for the C/C++ host language on Windows platforms. |
SQL statements are included in the host language source code exactly as though they were ordinary host language statements (i.e. they follow the same rules of conditional execution, etc., which apply to the host language).
SQL statements are identified by the leading keywords EXEC SQL (in all host languages) and are terminated by a language-specific delimiter. Every separate SQL statement must be delimited in this way.
Blocks of several statements may not be written together within one set of delimiters. For instance, in COBOL, two consecutive DELETE statements must be written as:
EXEC SQL DELETE FROM countries END-EXEC.
EXEC SQL DELETE FROM producers END-EXEC.
and not
EXEC SQL DELETE FROM countries
DELETE FROM producers END-EXEC.
Single SQL statements can however be split over several lines, following the host language rules for line continuation.
The following embedded statement is thus acceptable in a Fortran program (the continuation mark is a + in column 6 on the second line):
EXEC SQL DELETE FROM countries
+ WHERE code = 'BA' END-EXEC.
The keywords EXEC SQL may not be split over more than one line.
Included Code
Any code which is included in the program by the host language compiler (as directed by host language INCLUDE statements) is not recognized by the ESQL preprocessor.
If external source code modules containing SQL statements are to be included in the program, the non-standard SQL INCLUDE statement must be used, for example:
EXEC SQL INCLUDE 'filename'
Files included in this way are physically integrated into the output from the preprocessor.
Comments
Comments may be written in the ESQL program according to the rules for writing comments in the host language. Thus comments may be written within an SQL statement if the host language accepts comments within host language statements.
The following statement is valid in C/C++:
exec sql DELETE FROM countries /* Remove Bosnia and Herzegovina */
WHERE code = 'BA';
Note:The keywords EXEC and SQL may not be separated by a comment.
Recommendations
We recommend the following, when using ESQL:
•Avoid variable names beginning with the letters SQL (except for SQLSTATE and SQLCODE, which should be used when appropriate).
•Avoid subroutine or subprogram names ending with a number.
Language-specific restrictions are described in Host Language Dependent Aspects.
The following sections discuss preprocessing and processing ESQL.
Preprocessing – the ESQL Command
An application program containing ESQL statements must first be preprocessed using the ESQL command before it can be passed through the host language compiler, since the host language itself does not recognize the ESQL syntax.
Preprocessors are available for the host languages supported on each platform, see Host Languages.
The input to the preprocessor is thus a source code file containing host language statements and ESQL statements.
The output from the preprocessor is a source code file in the same host language, with the ESQL statements converted to source code data assignment statements and subroutine calls that pass the SQL statements to the Mimer SQL database manager.
The original ESQL statements are retained as comments in the output file, to help in understanding the program if a source code debugger is used.
The output from the preprocessor is human-readable source code, still retaining a large part of the structure and layout of the original program, which is used as input to the appropriate host language compiler to produce object code.
The default file extensions for preprocessor input and output files depend on the host language used and are shown in the table below:
|
Language |
Input file extension |
Output file extension |
|---|---|---|
|
C |
.ec |
.c |
|
C header |
.eh |
.h |
|
COBOL |
.eco |
.cob |
|
Fortran |
.efo |
.for |
Invoking the ESQL Preprocessor
The ESQL preprocessor has the following syntax:
esql [-c|-h|-b|-f] [-l] [-n] infile [outfile]
esql [--c|--header|--cobol|--fortran] [--line] [--nologo] infile [outfile]
esql [-v|--version] | [-?|--help]
Language
|
Unix-style |
VMS-style |
Function |
|---|---|---|
|
-c --c |
/C |
Indicates that the input file is written using the C/C++ host language. |
|
-h --header |
/HEADER |
Indicates that the input is a C/C++ host language header file. |
|
-b --cobol |
/COBOL |
Indicates that the input file is written using the COBOL host language. |
|
-f --fortran |
/FORTRAN |
Indicates that the input file is written using the Fortran host language. |
Options
|
Unix-style |
VMS-style |
Function |
|---|---|---|
|
-? --help |
/HELP |
Display usage information. |
|
-l --line |
/LINE |
Generates #line preprocessing directives for source written in the C language. These force the C compiler to produce diagnostic messages with line numbers relating to the input C source code rather than the code generated by the preprocessor (and thus compiled by the C compiler.) |
|
-n --nologo |
/NOLOGO |
Suppresses the display of the copyright message and input file name on the screen (warnings and errors are always displayed on the screen.) |
|
-v --version |
/VERSION |
Display version information. |
Input-file and Output-file
|
Unix-style |
VMS-style |
Function |
|---|---|---|
|
infile |
infile |
The input-file containing the source code to be preprocessed. If no file extension is specified, the appropriate file extension for the source language is assumed (previously described in this section.) |
|
[outfile] |
[outfile] |
The output-file which will contain the compiler source code generated by the preprocessor. If not specified, the output file will have the same name as the input file, but with the appropriate default output file extension (previously described in this section.) |
Note:As an application programmer, you should never attempt to directly modify the output from the preprocessor.
Any changes that may be required in a program should be introduced into the original ESQL source code. Mimer Information Technology AB cannot accept any responsibility for the consequences of modifications to the preprocessed code.
File Format Handling
When the ESQL preprocessor reads the input file it needs to make decisions about what kind of file format that is used. If the input file has a leading BOM (Byte Order Mark), which is especially common on the Windows platform, the file format is assumed to be according to this information. For example, this can indicate that the file is UTF-8 or UTF-16.
If no BOM is located, which usually is the case on other platforms than Windows, the file format is presumed to be in line with the current locale setting.
If the input file is written in plain ASCII, without using a BOM, the file format is not an issue. All steps in the build process for the source file will likely work without problems. In other cases, if a specific encoding is used, the file format must be considered in the translation and execution environments used.
The output file produced by ESQL is of the same format as the input file.
Example
The following example, on OpenVMS, shows how to preprocess the DSQLSAMP program:
$ ESQL/C MIMER$EXAMPLES:DSQL
What Does the Preprocessor Do?
The preprocessor checks the syntax and to some extent the semantics of the ESQL statements. (See Handling Errors and Exceptions for a more detailed discussion of how errors are handled). Syntactically invalid statements cannot be preprocessed and the source code must be corrected.
Processing ESQL – the Compiler
The output from the ESQL preprocessor is compiled in the usual way using the appropriate host language compiler, and linked with the appropriate routine libraries.
|
Linux:On Linux platforms, the gcc and gfortran compilers are supported. |
|
VMS:The following compilers are supported on the OpenVMS platform: –DEC C, VSI C –DEC Fortran, VSI Fortran –DEC COBOL, VSI COBOL Note:For COBOL, the source program must be formatted according to the ANSI rules. Use the /ANSI option when compiling the resulting COBOL program. |
|
Win:On Windows platforms, the C compiler identified by the cc symbol in the file .\dev\samples\makefile.mak below the installation directory is supported. |
Note:Other compilers, from other software distributors, may or may not be able to compile the ESQL preprocessor output. Mimer Information Technology cannot guarantee the result of using a compiler that is not supported.
The SQL Compiler
At run-time, database management requests are passed to the SQL compiler responsible for implementing the SQL functions in the application program.
The SQL compiler performs two functions:
•It checks SQL statements semantically against the data dictionary.
•It optimizes operations performed against the database (i.e. internal routines determine the most efficient way to execute the SQL request, with regard to the existence of secondary indexes and the number of rows in the tables addressed by the statement). You, as a programmer, do not need to worry, for instance, about the order in which tables are addressed in a complex selection condition. This optimization process is completely transparent.
Note:Since all SQL statements are compiled at run-time, there can be no conflict between the state of the database at the times of compilation and execution. Moreover, the execution of SQL statements is always optimized with reference to the current state of the database.
All application programs using embedded Mimer SQL must include certain basic components, summarized below in the order in which they appear in a program.
1Host Variable Declarations
A host variable is a variable used in the embedded program for entering data to the database or retrieving data from the database. Host variables must be declared inside the SQL DECLARE SECTION to be recognized. Host variables can be used in embedded statements where an expression can be used.
See the section Using Host Variables for more details.
2The Status Information Variable: SQLSTATE
The status information variable SQLSTATE, if used, must be declared inside the SQL DECLARE SECTION. This variable provides the application with status information for the most recently executed SQL statement.
3Executable SQL Statements
This is the body of the program, and performs the required operations on the database. Normally, these begin with connecting to Mimer SQL and performing the required transactions before finally disconnecting from Mimer SQL.
Summary of Functions for Manipulating Data
The following table summarizes the functions for data manipulation in interactive SQL and ESQL.
|
Operation |
Interactive SQL |
ESQL |
|---|---|---|
|
Retrieve data |
SELECT generates a result table directly. |
Declare a cursor for the SELECT statement. The cursor must be opened and positioned. Data is retrieved into host variables one row at a time with FETCH. |
|
Update data |
UPDATE operates on a set of rows or columns. |
UPDATE operates on a set of rows. |
|
Insert data |
INSERT inserts one or many rows at a time. |
INSERT inserts one or many rows at a time. |
|
Delete data |
DELETE operates on a set of rows. |
DELETE operates on a set of rows. |
|
Invoke routine |
CALL is used to execute all stored procedures, i.e. both result set and non-result set procedures are handled the same way. Functions can be specified where an expression could be used and are invoked when an expression used in the same context would be evaluated. |
Result set procedures are called by using the CALL clause in a cursor declaration and then using FETCH. Functions can be specified where an expression could be used and are invoked when an expression used in the same context would be evaluated. |
|
Assignment |
SET |
The set statement can be used to assign values to a host variable. E.g. if you want to invoke a user defined function or method and assign the result to a host variable, a statement such as SET :hv = Capitalize('john brown'), can be used. |
Many SQL statements (e.g. data definition statements) are simply embedded in their logical place in the application program and are executed without direct reference to other parts of the program.
Some features of ESQL however require special consideration, and are dealt with in detail in the chapters that follow:
•Access authorization through the use of user and program idents.
•Data manipulation statements which require the use of cursors (FETCH, UPDATE CURRENT, DELETE CURRENT). These together with cursor handling statements are probably the most commonly used statements in ESQL.
•Transaction control, which is essential for a consistent database.
•Dynamic SQL, which is a special set of statements allowing an application program to process SQL statements entered by the user at run-time.
•Exception handling, which controls the action taken when, for instance, the end of a result set is reached.
|
Linux:The example makefile ex_makefile, found in the installation examples directory, provides a verified example of the recommended way to build C applications on Linux platforms. For Fortran, see the ex_makefile_f example makefile. Applications built using the procedure contained in this makefile will reference the Mimer SQL shared library called libmimer. |
|
VMS:All Mimer SQL applications should be linked with the options file MIMER$SQL.OPT, as shown in the following example: $ LINK main,MIMER$LIB:MIMER$SQL/OPT
The MIMER$SQL.OPT file includes the following: –MIMER$LIB:MIMER$SQL.EXE (shareable library) If an image linked in this fashion is activated, it will translate the logical name MIMER$SQL to get the name of the Mimer SQL shareable library to be used. The logical name is defined by the SYS$MANAGER:MIMER$SETUP_xxxxx command procedure. |
|
Win:The example makefile .\dev\samples\makefile.mak in the installation directory should be copied and used in the recommended way to build applications on Windows platforms. |
If applications are linked as recommended above to reference the Mimer SQL shared library, they will automatically use a new version of Mimer SQL when it is installed, without having to be re-linked.
A database in Mimer SQL refers to the complete collection of databanks that may be accessed from one Mimer SQL system.
Mimer ESQL supports the ability to change between different connections (i.e. access different databases) from within the same application program. An application program may have several database connections open simultaneously, although only one is active at any one time.
Only idents of type USER are allowed to log on to Mimer SQL.
The CONNECT Statement
Logging on is requested from an application program with the CONNECT statement, see the Mimer SQL Reference Manual, CONNECT, for the syntax description.
The CONNECT statement establishes a connection between a USER ident and a database
exec sql CONNECT TO 'db' AS 'con1' USER 'ident' USING 'pswd';
To connect using an OS_USER login with the same name as the current operating system user, provide an empty ident name string. E.g.
exec sql CONNECT TO 'db' AS 'con2' USER ' ' USING ' ';
Local and Remote Databases
A connection may be established to any local or remote database, which has been made accessible from the current machine, see the System Management Manual, Creating a Mimer SQL Database, for details, by specifying the database by name or by using the keyword DEFAULT.
Default or Named Database
If the keyword DEFAULT is used, an OS_USER login is used for the connection attempt.
exec sql CONNECT TO DEFAULT;
If the database name is given as an empty string, the DEFAULT database is used.
exec sql CONNECT TO ' ' AS 'con1' USER 'ident' USING 'pswd';
The database may be given an explicit connection name for use in DISCONNECT and SET CONNECTION statements. If no explicit name is given, the database name is used as the connection name.
exec sql CONNECT TO 'db' USER 'ident' USING 'pswd';
Implicit Connection
Normally, CONNECT should be the first SQL statement executed in an application program using ESQL. However, if another SQL statement is issued before any connection has been established in the current application, an implicit connection will be attempted.
An implicit connection is made to the DEFAULT database using the current operating system user.
In order for the implicit connect attempt to be successful, the current operating system user must be defined as an OS_USER login in Mimer SQL and the DEFAULT database must be defined as a local database on the machine on which the current operating system user is defined.
If an implicit connection has previously been established in the application and there is no current connection, issuing an executable statement will result in a new attempt to make the same implicit connection. However, if an explicit connection has previously been established in the application and there is no current connection, issuing an executable statement will cause an error.
Changing Connection
A connection established by a successful CONNECT statement is automatically active.
An application program may make multiple connections to the same or different databases using the same or different idents, provided that each connection is identified by a unique connection name.
Only the most recent connection is active. Other connections are dormant, and may be made active by the SET CONNECTION statement. Resources such as cursors used by a connection are saved when the connection becomes dormant, and are restored by the appropriate SET CONNECTION statement.
The statement sequence below connects to a user-specific database as a specified ident name and to the DEFAULT database using an OS_USER login. The user-specific connection is initially active. Then the DEFAULT connection is activated. Finally the user-specific connection is activated again using SET CONNECTION.
EXEC SQL CONNECT TO 'db' AS 'con1' USER 'ident' USING 'pswd';
...
EXEC SQL CONNECT TO DEFAULT;
...
-- Set activate connection to CON1
EXEC SQL SET CONNECTION 'con1';
Note:If different connections are made with different idents, the apparent access rights of the application program may change when the current connection is changed.
Disconnecting
The DISCONNECT statement breaks the connection between a user and a database and frees all resources allocated to that user for the specified connection (all cursors are closed and all compiled statements are dropped). The connection to be broken is specified as the connection name or as one of the keywords ALL, CURRENT or DEFAULT. (If a transaction is active when the DISCONNECT is executed, an error is raised and the connection remains open).
A connection does not have to be active in order to be disconnected. If an inactive connection is broken, the application still has uninterrupted access to the database through the current (active) connection, but the broken connection is no longer available for activation with SET CONNECTION.
If the active connection is broken, the application program cannot access the database until a new CONNECT or SET CONNECTION statement is issued.
Note:The distinction between breaking a connection with DISCONNECT and making a connection inactive by issuing a CONNECT or SET CONNECTION for a different connection is, a broken connection has no saved resources and cannot be reactivated by SET CONNECTION.
The table below summarizes the effect on the connection con1 of CONNECT, DISCONNECT and SET CONNECTION statements depending on the state of the connection.
|
Statement |
con1 non-existent |
con1 current |
con1 inactive |
|---|---|---|---|
|
CONNECT TO db1 AS con1 |
con1 current |
error – connection already exists |
error – connection already exists |
|
DISCONNECT con1 |
error – connection does not exist |
con1 disconnected |
con1 disconnected |
|
SET CONNECTION con1 |
error – connection does not exist |
ignored |
con1 made current |
|
CONNECT TO db2 AS con2 |
– |
con1 made inactive |
con1 unaffected |
|
DISCONNECT con2 |
– |
con1 unaffected |
con1 unaffected |
|
SET CONNECTION con2 |
– |
con1 made inactive |
con1 unaffected |
PROGRAM Idents – ENTER and LEAVE
PROGRAM idents may be entered from within an application program by using the ENTER statement, see the Mimer SQL Reference Manual, ENTER for the syntax description. This statement must be issued in a context where a user is already connected as PROGRAM idents cannot connect directly to the system.
When a PROGRAM ident is entered, any privileges granted to that ident become current and privileges belonging to the previous ident (i.e. the ident issuing the ENTER statement) are suspended. However, any cursors opened by the previous ident remain open.
PROGRAM idents are disconnected with the LEAVE statement. If LEAVE is requested with the optional keyword RETAIN, the full environment of the PROGRAM ident being left is kept.
Cursors left open by the PROGRAM ident are deactivated but not closed, and retain their positions in the respective result tables. The environment is restored if the PROGRAM ident is re-entered.
If LEAVE is requested without RETAIN, the environment of the PROGRAM ident being left is dropped. This means that all cursors and compiled statements are destroyed.
Note:The distinction between leaving a PROGRAM ident with the option RETAIN and entering a new PROGRAM ident is, while both operations save the environment of the PROGRAM ident, cursors left open at ENTER may still be used but those left open at LEAVE RETAIN are inaccessible until the program ident is re-entered.
The statements ENTER and LEAVE may not be issued within transactions, see Transaction Handling and Database Security.
Communicating with the Application Program
Information is transferred between the embedded SQL (ESQL) application program and the Mimer SQL database manager in four ways:
•through host variables used in SQL statements
•through the status variable SQLSTATE
•through the diagnostics area, accessed by the SQL statement GET DIAGNOSTICS
•through an SQL descriptor area.
Host variables are used in SQL statements to pass values between the database and the application program.
All variables used in SQL statements must be declared for the preprocessor. This is done by enclosing the variable declarations between the SQL statements BEGIN DECLARE SECTION and END DECLARE SECTION.
The following example in C declares the character variables user and passw for use in SQL statements:
int rc, pf, cnt;
exec sql BEGIN DECLARE SECTION;
char user[129],
passw[129]; /* 128 character column, and a null byte */
exec sql END DECLARE SECTION;
Any variables declared outside the DECLARE SECTION will not be recognized by the preprocessor.
Variables are declared within the section using the normal host language syntax.
Variables which are not used in SQL statements may also be declared in the SQL DECLARE SECTION. (This will however extend the symbol table established by the preprocessor more than is necessary.)
The use of array variables is currently not supported in embedded Mimer SQL (except for character string variables).
Using Variables in Statements
•to receive information from the database (SELECT INTO, FETCH, CALL and SET statements)
•to assign values to columns in the database (CALL, INSERT and UPDATE statements)
•to manipulate information taken from the database or contained in other variables (in expressions)
•to get descriptor and diagnostics information (GET DESCRIPTOR, SET DESCRIPTOR and GET DIAGNOSTICS)
•in dynamic SQL statements.
In all these contexts, the data type of the host variable or database column must be compatible with the data type of the corresponding database value or host variable. General considerations of data type compatibility may be found in the Mimer SQL Reference Manual. Host language specific aspects are described in Host Language Dependent Aspects of this manual.
If you have an INTEGER column containing values that do not fit into the largest integer variable allowed on your machine (remember that Mimer SQL supports INTEGER values with a precision of up to 45 digits), you can, for example, use a character string or float host variable for that column. In this case, Mimer SQL automatically performs the necessary conversions.
Host variables are preceded by a colon when used in SQL statements, see the Mimer SQL Reference Manual, Host Identifiers.
Note:The colon is not part of the host variable, and should not be used when the variable is referenced in host language statements.
Example
EXEC SQL SELECT COUNT(*)
INTO :VAR
FROM table
WHERE condition;
if VAR < LIMIT then ...
In ESQL, indicator variables associated with main variables are used to handle null values in database tables.
Indicator variables should be an exact numeric data type with scale zero and are declared in the same way as main variables in the SQL DECLARE SECTION.
See Declarations for a description of how main and indicator variables should be declared in the specific host languages.
Indicator variables are used in SQL statements by either specifying the name of the indicator variable, preceded by a colon, after the main variable name or by using the keyword INDICATOR, for example:
:main_variable :indicator_variable
or
:main_variable INDICATOR :indicator_variable
Transfer from Tables to Host Variables
When a null value is retrieved into a host variable by a FETCH, SELECT INTO, EXECUTE, SET or CALL statement, the value of the main variable is undefined and the value of the indicator variable is set to -1.
An error occurs if the main variable is not associated with an indicator variable in the SQL statement. It is therefore recommended as a precaution that indicator variables are used for all columns which are not defined as NOT NULL in the database.
An indicator variable should always be used when a host variable is used for a routine parameter with mode OUT or INOUT because a null value can always be returned via a routine parameter.
When a non-null value is assigned to a main variable associated with an indicator variable, the indicator variable is set to zero or a positive value. A positive value indicates that the value assigned to a main character variable was truncated, and gives the length of the original value before truncation.
Transfer from Host Variables to Tables
When the host variable associated with an indicator variable is used to assign a value to a column, the value assigned is null if the value of the indicator variable is set to -1.
In such a case, the value of the main variable is irrelevant. If the indicator variable has a value of zero or a positive value, or if the main variable is not associated with an indicator variable, the value of the main variable itself is assigned to the column.
External Character Set Support
The handling of the single byte character data types follows the current locale setting on the machine to determine what characters are stored/retrieved when an embedded SQL application passes single-byte character strings to the Mimer client.
When character data is stored in Mimer SQL it can be stored in CHAR, VARCHAR or CLOB columns, or in NCHAR, NVARCHAR or NCLOB columns. Data in CHAR, VARCHAR and CLOB columns use the Latin-1 character representation (also called ISO 8859-1). This character set can only be used to store 256 different characters. For the exact characters that can be stored see Mimer SQL Reference Manual, Character Sets. To store any other characters the data type NCHAR, NVARCHAR or NCLOB must be used. These column types can store any character.
If a locale is used by the application that has characters that are not included in Latin-1, it means that the columns in the database data must use an NCHAR, NVARCHAR, or NCLOB column to store the correct characters. With the locale support the Mimer SQL client understands the representation of the characters in the application and maps them accordingly to its internal representation.
When retrieving data from the database, the translation work the other way. I.e. when retrieving data from a CHAR or NCHAR column to a single-byte character variable, the current locale must be able to represent all the characters returned from the database. When this is not possible, a conversion error -10401 is returned. If characters stored in the database have no representation in the chosen locale, a wide character data type must be used by the application instead (e.g. the C type wchar_t rather than char).
This means that applications using older versions of Mimer may have to be updated to work with the new version. Typically the data type used in the database is altered from CHAR to NCHAR, or from VARCHAR to NVARCHAR. This is done with the ALTER TABLE statement (see Mimer SQL Reference Manual, ALTER TABLE). Other possible changes is to switch from a character representation (e.g. char) to a Unicode representation (e.g. wchar_t) for the application variables, or to switch to a locale that can handle all relevant characters.
On Windows the setting used for the external character set is set in the Regional and Language Options in the Control Panel under the tab Advanced. This setting is used automatically by the Mimer client.
On VMS the system continues to use the Latin-1 character representation regardless of locale settings.
On other platforms (Linux, macOS, others) the application must call the runtime library routine setlocale to pick the locale to use. For example, the call setlocale(LC_CTYPE, "") sets the default locale as decided by the environment setting. The actual conversions made by the Mimer client are through the library routines mbstowcs (multibyte character set to wide char set) and wcstombs. Please note that if an application does not call setlocale a default 7-bit locale is used. This means that no 8-bit characters can be used without getting a conversion error. For applications where the source is not available it is possible to set an environment variable MIMER_LOCALE that will be used when calling the Mimer client. The value of the environment variable is used as the second argument to setlocale.
To use the default locale set MIMER_LOCALE to current. On Windows the environment variable is set to the desired code page, i.e. only numeric values may be specified (for example: 1250: ANSI Central Europe, 1251: ANSI Cyrillic, 1252: Latin1, 1253: ANSI Greek, 1254: ANSI Turkish, and so on.)
The fact that the character type is considered a multi-byte character set allows any external character representation to be used. In particular various character sets such as Traditional Chinese Big5 and Japanese Shift-JIS may be used. The character set may, of course, be a single byte character set as such as the Greek Latin-7 character set (code page 1253 on Windows). On Linux platforms the prevalent representation is UTF-8 that allows any Unicode character to be stored in a character variable.
The SQLSTATE variable provides the application, in a standardized way, with return code information about the most recently executed SQL statement.
SQLSTATE must be declared between the BEGIN DECLARE SECTION and the END DECLARE SECTION (i.e. in the SQL declare section), as a 5 character long string (excluding any terminating null byte).
The return codes provided by SQLSTATE can contain digits and capital letters.
SQLSTATE consists of two fields. The first two characters of SQLSTATE indicates a class, and the following three characters indicates a subclass. Class codes are unique, but subclass codes are not. The meaning of a subclass code depends on the associated class code.
To determine the category of the result of an SQL statement, the application can test the class of SQLSTATE according to the following:
|
SQLSTATE Class |
Result category |
|---|---|
|
00 |
Success |
|
01 |
Success with warning |
|
02 |
No data |
|
Other |
Error |
For a list of SQLSTATE values, see Return Codes.
The Diagnostics Area
The diagnostics area holds status information for the most recently executed SQL statement.
There is always one diagnostics area for an application, no matter how many connections the application holds.
Information from the diagnostics area is selected and retrieved by the GET DIAGNOSTICS statement. The syntax for GET DIAGNOSTICS (including a description of the diagnostics area) is described in Mimer SQL Reference Manual, GET DIAGNOSTICS.
The GET DIAGNOSTICS statement does not change the contents of the diagnostics area, except it does set SQLSTATE.
The SQL Descriptor Area
An SQL descriptor area is used to hold data and descriptive information required for execution of dynamic SQL statements. SQL descriptor areas are allocated and maintained by ESQL statements, described in the Mimer SQL Reference Manual.
The SQL descriptor area is discussed in detail in SQL Descriptor Area.
This section explains how embedded SQL applications retrieve data.
Data is retrieved from database tables with the FETCH statement, which fetches the values from an individual row in a result set into host variables.
The result set is defined by a SELECT construction or a result set procedure CALL, see Manipulating Data, used in a cursor declaration. A cursor may be thought of as a pointer which moves through the rows of the result set as successive FETCH statements are issued.
An exception is raised to indicate when the FETCH has reached the end of the result set.
Data retrieval involves several steps in the application program code, which are as follows:
•declaration of host variables to hold data
•declaration of a cursor with the appropriate SELECT conditions or result set procedure CALL
•opening the cursor
•performing the FETCH
•closing the cursor.
General Framework
The steps in the previous section are built into the application program as shown in the general frameworks below (only SQL statements are shown in the frameworks).
For a SELECT:
EXEC SQL BEGIN DECLARE SECTION;
... VAR1, VAR2, ... VARn ...
EXEC SQL END DECLARE SECTION;
EXEC SQL DECLARE cursor-name CURSOR FOR select-statement;
EXEC SQL OPEN cursor-name;
loop as required
EXEC SQL FETCH cursor-name
INTO :VAR1, :VAR2, ..., :VARn;
end loop;
EXEC SQL CLOSE cursor-name;
For a result set procedure CALL:
EXEC SQL BEGIN DECLARE SECTION;
... VAR1, VAR2, ... VARn ...
EXEC SQL END DECLARE SECTION;
EXEC SQL DECLARE cursor-name CURSOR FOR CALL routine-invocation;
EXEC SQL OPEN cursor-name;
loop as required
EXEC SQL FETCH cursor-name
INTO :VAR1, :VAR2, ..., :VARn;
end loop;
EXEC SQL CLOSE cursor-name;
Declaring Host Variables
All host variables used to hold data fetched from the database and used in selection conditions or as result set procedure parameters must be declared within an SQL DECLARE SECTION, see Communicating with the Application Program.
Indicator variables for columns that may contain null values must also be declared.
The same indicator variable may be associated with different main variables at different times, but declaration of a dedicated indicator variable for each main variable is recommended for clarity.
A cursor operates as a row pointer associated with a result set.
A cursor is defined by the DECLARE CURSOR statement and the set of rows addressed by the cursor is defined by the SELECT statement in the cursor declaration.
Cursors are local to the program in which they are declared. A cursor is given an identifying name when it is declared.
DECLARE CURSOR is a declarative statement that does not result in any implicit connection to a database, see Idents and Privileges for details on connecting to a database.
Preprocessing the statement generates a series of parameters used by the SQL compiler but does not generate any executable code; the select-expression or result set procedure call in the cursor declaration is not executed until the cursor is opened.
Holdable cursors can be declared using the WITH HOLD clause. An open cursor declared WITH HOLD remain open after COMMIT.
Cursors should normally be declared WITHOUT HOLD (default), because WITH HOLD cursors require more internal resources then ordinary cursors. In addition, long lasting WITH HOLD cursors can have negative performance effects just like long lasting transactions.
If the cursor declaration contains a CALL to a result set procedure, it is FETCH that actually executes the procedure.
The RETURN statement is used from within the result set procedure to return a row of the result set.
Each FETCH causes statements in the result set procedure to execute until a RETURN statement is executed, which will return the row data defined by it. Execution of the procedure is suspended at that point until the next FETCH.
If, during execution, the end of the procedure is encountered instead of a RETURN statement, the FETCH result is end-of-set. See Result Set Procedures for a detailed description of result set procedures.
Note:It is advisable to always use an explicit list of items in the SELECT statement of the cursor declaration. The shorthand notations SELECT * and SELECT table.* are useful in interactive SQL, but can cause conflicts in the variable lists of FETCH statements if the table definition is changed.
The cursor declaration can use host variables in the WHERE or HAVING clause of the SELECT statement.
The result set addressed by the cursor is then determined by the values of these host variables at the time when the cursor is opened.
The same cursor declaration can thus address different result sets depending on when the cursor is opened, for example:
EXEC SQL DECLARE C1 CURSOR..; -- cursor with host variables
set variables
EXEC SQL OPEN C1; -- open one result set
...
EXEC SQL CLOSE C1;
set variables
EXEC SQL OPEN C1; -- open different result set
Scrollable cursors can be declared using the SCROLL keyword. When a cursor is declared as scrollable, records can be fetched using an orientation specification. This makes it possible to scroll through the result set with the cursor.
Cursors which are to be used only for retrieving data may be declared with a FOR READ ONLY clause in the SELECT statement. This can improve performance slightly in comparison with cursors that permit update and delete operations.
A declared cursor must be opened with the OPEN statement before data can be retrieved from the database. The OPEN statement evaluates the cursor declaration in terms of
•the privileges the current user holds on any tables and views accessed by the cursor
•the values of any host variables used in the SELECT clause
•for a cursor calling a result set procedure, whether the current user has the required EXECUTE privilege on the procedure and also the values of any IN parameters
When the OPEN statement has been executed, the cursor is positioned before the first row in the result set.
Once a cursor has been opened, data may be retrieved from the result set with FETCH statements, see the Mimer SQL Reference Manual, FETCH, for the syntax description.
Host variables in the variable list correspond in order to the column names specified in the SELECT clause of the cursor declaration. The number of variables in the FETCH statement may not be more than the number of columns selected. The number of variables may be less than the number of columns selected, but a ‘success with warning’-code is then returned in SQLSTATE.
A suitably declared record structure may be used in place of a variable list in host languages where this is supported, see Host Language Dependent Aspects.
Each FETCH statement moves the cursor to the specified row in the result set before retrieving data. In strict relational algebra, the ordering of tuples in a relation (the formal equivalent of rows in a table) is undefined. The SELECT statement in the cursor declaration may include an ORDER BY clause if the ordering of rows in the result set is important to the application.
Note:A cursor declared with an ORDER BY clause cannot be used for updating table contents.
If no ORDER BY clause is specified, the ordering of rows in the result set is unpredictable.
Note:The variables into which data is fetched are specified in the FETCH statement, not in the cursor declaration. In other words, data from different rows in the result set may be fetched into different variables.
When there are no more rows to fetch, the exception condition NOT FOUND will be raised.
The following construction thus fetches rows successively until the result set is exhausted:
EXEC SQL DECLARE C1 CURSOR FOR select-statement;
EXEC SQL OPEN C1;
EXEC SQL WHENEVER NOT FOUND GOTO done;
LOOP
EXEC SQL FETCH C1 INTO :var1,:var2,...,:varn;
END LOOP
done:
EXEC SQL CLOSE C1;
The access rights for a user are checked when the cursor is opened and they remain unchanged for that cursor until the cursor is closed.
For example, if an application program declares and opens a cursor, then SELECT access on the table is revoked from the user running the program, data can still be fetched from the result set as long as the cursor remains open. Any subsequent attempt to open the same cursor will, however, fail.
The Embedded SQL interface tries whenever possible to fetch rows in blocks to minimize server communications. The first fetch would normally issue a request to the server for a number of rows at once. In most situations, this will improve application performance.
In some situations, this is not the desired behavior. One such situation is queries searching through a huge number of rows without the help of indexes. For example if the database server is only able to return one row a second, and the entire query takes minutes, the user can still be happy as long as he sees the first rows on screen. If this is important to the application, set the fetch size manually. An appropriate fetch size is the number of rows displayed at once. See Mimer SQL Reference Manual, SET SESSION FETCH SIZE for more information.
An opened cursor remains open until it is closed with one of the statements CLOSE, COMMIT, ROLLBACK or DISCONNECT. CLOSE closes the specified cursor. ROLLBACK and DISCONNECT close all open cursors for the connection. COMMIT closes all open cursors for the connection, except cursors declared as WITH HOLD. Once a cursor is closed, the result set is no longer accessible. However, the cursor declaration remains valid, and a new cursor may be opened with the same declaration.
Note:The result set addressed by the new cursor may not be the same if the contents of the database or the values of variables used in the declaration have changed.
Normally, resources used by the cursor remain allocated when the cursor is closed and will be used again if the cursor is re-opened. The optional form CLOSE cursor-name RELEASE deallocates cursor resources. Use of CLOSE with the RELEASE option is recommended in application programs which open a large number of cursors, particularly where system resources are limited.
Note:The use of CLOSE with the RELEASE option may slow down performance if there is a following OPEN, since it requires that new resources are allocated at the next OPEN for that cursor. For this reason it should only be used when necessary.
Cursors are local to a connection and remain open but dormant when the connection is made dormant. The state of dormant cursors is fully restored (including result set addressed and position in the result set) when the connection is reactivated. Cursors are, however, closed and cursor resources are deallocated, when a connection is disconnected.
Note:Cursors opened in a program ident context are closed and resources deallocated when LEAVE is executed within the same connection, unless LEAVE RETAIN is specified.
If the result of a SELECT statement is known to be a single row, the SELECT INTO statement may be used as an alternative to fetching data through a cursor.
This is a much simpler programming construction, since cursors are not used and the only requirement is that host variables used in the SELECT INTO statement are declared in the DECLARE SECTION.
However, there are two disadvantages associated with SELECT INTO:
•An error occurs if the result set addressed by the search condition contains more than one row. In other words, SELECT INTO can only be reliably used when there is no possibility of a multi-row result set (essentially when the search condition includes the columns that form a UNIQUE or PRIMARY KEY column or returns just the result of a set function, e.g. COUNT(*)).
•Execution of the SELECT INTO statement involves a check that the result set contains one single row, which may incur unnecessary overhead. Even if it is known that the result row is unique, a single FETCH operation through a cursor may be a more efficient implementation.
Use of a SELECT INTO statement is justified when the result set may contain several rows, but it is a condition for continued execution of the application program that the result row is unique. With a cursor, this would require a construction that checked that one and only one FETCH operation could be performed (alternatively, use a separate SELECT COUNT with the same search condition as the cursor). In such a case, a SELECT INTO statement with a check on the return code, see Handling Errors and Exceptions, is probably the preferred solution.
A CALL statement can be used to return information to the one or more host variables associated with the output parameter(s) of the procedure.
A SET statement can be used with a function or method invocation to return information to one host variable.
Retrieving Data from Multiple Tables
Data can be retrieved from multiple tables in ESQL by addressing several tables in the SELECT statement of the cursor declaration, in the same way as in interactive SQL. The preprocessor generates a SELECT statement addressing multiple tables, which is optimized by the SQL compiler when the cursor is opened.
Example
EXEC SQL DECLARE c_1 CURSOR FOR SELECT ...
FROM a JOIN b
ON a.x = b.y;
EXEC SQL OPEN c_1;
...
An alternative way to link information between tables could be to define the search condition for one cursor in terms of a variable fetched through another cursor:
EXEC SQL DECLARE c_1 CURSOR FOR SELECT x
FROM a;
EXEC SQL DECLARE c_2 CURSOR FOR SELECT ...
FROM b
WHERE y = :HOSTX;
EXEC SQL OPEN c_1;
EXEC SQL FETCH c_1
INTO :HOSTX;
EXEC SQL CLOSE c_1;
EXEC SQL OPEN c_2;
EXEC SQL FETCH c_2;
...
When considering the two alternatives, the first one is preferred. The reason for this is:
•The SQL optimizer gets the full information about the query that it is supposed to return a result set for. In this way the optimizer can make more use of statistical information and it can thereby optimize the query to execute in a more efficient way.
•The application will require less resources in the form of open cursors.
•If the application is run in a client/server environment, the second alternative will cause more communication over the network, since it will send data over the net which is only used to determine which data from the second cursor that will be selected and is of no real interest to the application.
•The application will be more compact as well as easier to understand and maintain.
A special case of data retrieval from multiple tables is the use of stacked cursors to fetch data from logical copies of the same table, in a manner that provides a solution to the so called “Parts explosion” problem.
A cursor can be defined as REOPENABLE and the same cursor may be opened several times in succession in the same application program, each previous instance of the cursor being saved on a stack and restored when the following instance is closed. A FETCH statement refers to the most recently opened instance of a cursor. Each instance of the cursor addresses an independent result set and the position of each cursor in its own result set is saved on the stack.
Note:Result sets addressed by different instances of a cursor may differ according to the conditions prevailing when the cursor instance was opened.
The state of the cursor stack needs to be controlled by the application. A counter can be used to indicate if there are more instances of the cursor remaining on the stack. See the example that follows.
Stacked cursors are typically used in application programs which traverse a tree structure stored in the database.
For example (this is a simplified variant of the “parts explosion” problem), traverse a tree structure and print out the leaf nodes:
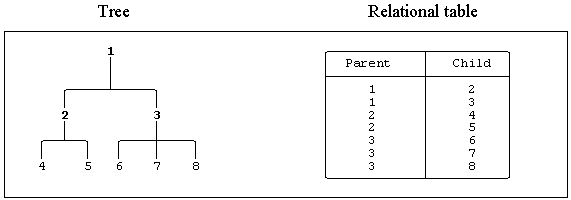
procedure TRAVERSE;
integer CSTACK, LASTC;
EXEC SQL BEGIN DECLARE SECTION;
integer PARENT, CHILD;
string SQLSTATE(5);
EXEC SQL END DECLARE SECTION;
begin
EXEC SQL DECLARE c_tree REOPENABLE CURSOR FOR
SELECT parent, child
FROM tree
WHERE parent = :PARENT;
CSTACK := 1;
LASTC := 1;
PARENT := 1; -- Start at root node
EXEC SQL OPEN CTREE;
loop
EXEC SQL FETCH c_tree
INTO :PARENT, :CHILD;
if SQLSTATE = "02000" then -- No more children
EXEC SQL CLOSE c_tree; -- Pop the parent
CSTACK := CSTACK - 1;
exit when CSTACK = 0;
if CSTACK >= LASTC then
print(PARENT); -- Write leaf node
end if;
LASTC := CSTACK;
else -- Step to next level
PARENT := CHILD;
EXEC SQL OPEN c_tree; -- Stack the current parent
and open new level
CSTACK := CSTACK + 1;
end if;
end loop;
end TRAVERSE;
The counters CSTACK and LASTC keep track of the number of stacked cursor levels and the latest level in the tree hierarchy respectively.
The following sections explain how to perform cursor-independent operations and update and delete using cursors.
Cursor-independent Operations
The SQL statements CALL, INSERT, DELETE and UPDATE, as well as user-defined functions or method invocations, embedded in application programs operate on a set of rows in a table or view in exactly the same way as in interactive SQL.
Host variables may be used in the statements to supply values or set search conditions, and host variables may be used as routine parameters.
Examples:
EXEC SQL INSERT INTO mimer_store.items(item_id,
product_id, format_id,
release_date,
price, stock, reorder_level,
ean_code,
producer_id)
VALUES (CURRENT VALUE FOR mimer_store.item_id_seq,
:product_id, :format_id,
mimer_store.cast_to_date(:book_release_date),
:book_price, :book_stock, :book_reorder_level,
(:ean * 10) + mimer_store.ean_check_digit(:ean),
producer_id);
From the standpoint of the application program, each statement is a single indivisible operation, regardless of how many columns and rows are affected.
Updating and Deleting Through Cursors
The UPDATE CURRENT and DELETE CURRENT statements (see the Mimer SQL Reference Manual, SQL Statements for the syntax description), allow update and delete operations to be controlled on a row-by-row basis from an application. These statements operate through cursors, which are declared and opened as described above for FETCH.
These statements operate on the current row of the cursor referenced in the statement. If there is no current row, e.g. the cursor has been opened but not yet positioned with a FETCH statement, an error is raised.
UPDATE CURRENT changes the contents of the current row according to the SET clause in the statement, but does not change the position of the cursor. Two consecutive UPDATE CURRENT statements will therefore update the same row twice.
DELETE CURRENT deletes the current row and does not move the cursor; after a DELETE CURRENT statement, the cursor is positioned between rows and there is no current row. The cursor must be moved to the next row with a FETCH statement before any other operation can be performed through the cursor.
For both UPDATE CURRENT and DELETE CURRENT statements, the table name as used in the statement must be exactly the same as the table name addressed in the cursor declaration. The cursor must also address an updatable result set.
UPDATE CURRENT and DELETE CURRENT changes for a particular cursor can be divided into several transactions if the cursor is a holdable cursor. A cursor declared WITH HOLD remains open when transactions are committed, which makes it possible to use the same cursor for fetch and update of additional rows after COMMIT. However, each row must still be fetched and updated (or deleted) in the same transaction.
All SELECT statements are by default read only. This means that they cannot be used with UPDATE CURRENT and DELETE CURRENT unless a FOR UPDATE clause is added to the SELECT statement. If a FOR UPDATE OF clause is used to specify which fetched columns may be updated, only the columns specified may appear in the corresponding UPDATE statement.
Cursors can not be updatable if the data retrieval statement in the cursor declaration contains any of the following features at the top level (i.e. not in a subquery) of the statement:
•reference to more than one table in the FROM clause (i.e. an explicit or implicit join)
•reference to a read-only view in the FROM clause
•the keyword DISTINCT
•set-functions in the SELECT list (AVG, COUNT, MAX, MIN, SUM)
•arithmetic or string concatenation expressions in the SELECT list
•a GROUP BY clause
•an ORDER BY clause
•the UNION keyword
•the EXCEPT keyword
•the INTERSECT keyword
•a CALL to a result set procedure
•the SELECT statement is implicitly or explicitly declared as READ ONLY. (To be updatable, the SELECT needs to be declared with the FOR UPDATE clause.)
When to Use UPDATE CURRENT, DELETE CURRENT
UPDATE CURRENT and DELETE CURRENT statements are useful for manipulating single rows in interactive applications where rows are displayed, and the user decides which rows to delete or update.
The example below illustrates the program framework for such an operation (the construction is similar for a DELETE CURRENT operation):
...
EXEC SQL DECLARE c_1 CURSOR FOR SELECT ... FOR UPDATE;
...
EXEC SQL OPEN c_1;
EXEC SQL WHENEVER NOT FOUND GOTO done;
loop
EXEC SQL FETCH c_1
INTO :VAR1, :VAR2, ..., :VARn;
display VAR1, VAR2, ..., VARn;
prompt "Update this row?";
if ANSWER = "YES" then
prompt "Give new values";
EXEC SQL UPDATE tab
SET col1 = :NEWVAL1,
col2 = :NEWVAL2, ...
WHERE CURRENT OF c_1;
display "Row updated";
end if;
prompt "Display next row?";
exit when ANSWER = "NO";
end loop;
done:
EXEC SQL CLOSE c_1;
In situations where there is no requirement to interactively choose rows and where all the rows to be updated or deleted can be specified completely in terms of a WHERE clause, it is more efficient to do so rather than use a cursor.
An operation completely specified as a WHERE clause is executed as a single statement, rather than a series of statements (i.e. one for each FETCH etc.).
This section discusses the principles of dynamic SQL, processing dynamic SQL, the descriptor area, preparing statements, extended dynamic cursors and prepared statements.
Dynamic SQL enables you to execute SQL statements placed in a string variable instead of explicitly writing the statements inside a program. This allows SQL statements to be constructed within an application program. These facilities are typically used in interactive environments, where SQL statements are submitted to the application program from the terminal.
An example of when dynamic SQL is needed would be a program for interactive SQL, where any correct SQL statement may be entered at the terminal and processed by the application. Limited dynamic facilities may however be provided by relatively simple application programs.
SQL Statements and Dynamic SQL
The following classes of SQL statements may be submitted to programs using dynamic SQL. Statements excluded from dynamic applications are declarations, diagnostic statements and dynamic SQL statements themselves.
•Access control statements:
ENTER
LEAVE
•Data definition statements:
CREATE
ALTER
COMMENT
DROP
•Security control statements:
GRANT
REVOKE
•Transaction control statements:
SET SESSION
SET TRANSACTION
START
COMMIT
ROLLBACK
•Data manipulation statements:
CALL
SELECT
SELECT INTO
INSERT
UPDATE
UPDATE CURRENT
DELETE
DELETE CURRENT
COMPOUND STATEMENT
SET
•System administration statements:
CREATE BACKUP
ALTER DATABANK RESTORE
SET DATABASE
SET DATABANK
SET SHADOW
UPDATE STATISTICS
DELETE STATISTICS
Statements may be submitted to dynamic SQL applications in two forms:
•Fully defined statements, written exactly as they would be submitted to interactive SQL. For example:
GRANT SELECT ON mimer_store_book.details TO mimer_admin_group
SELECT code, country FROM mimer_store.countries
•Statements with parameter markers, which identify positions where the value of a host variable will be inserted when the statement is executed or the cursor is opened. A parameter marker is represented by a question mark ? or using colon notation. For example:
UPDATE mimer_store.currencies
SET exchange_rate = ?
WHERE code = ?
DELETE FROM countries
WHERE code = :codeparam
SELECT currency_code
FROM mimer_store.countries
WHERE code LIKE '%' || ? || '%'
Statements submitted with parameter markers are equivalent to normal embedded statements using host variables, except that the statements are defined at run-time.
General Summary of Dynamic SQL Processing
The following statements are used when SQL statements are dynamically submitted:
|
Statement |
Description |
|---|---|
|
ALLOCATE CURSOR |
Allocate extended cursor. |
|
ALLOCATE DESCRIPTOR |
Allocate SQL descriptor area. |
|
CLOSE |
Close an open cursor. |
|
DEALLOCATE DESCRIPTOR |
Deallocate SQL descriptor area. |
|
DEALLOCATE PREPARE |
Deallocate prepared SQL statement. |
|
DECLARE CURSOR |
Declare a cursor for a statement which will be dynamically submitted. |
|
DESCRIBE |
Examine the object form of the statement and assign values to the appropriate parameters in the SQL descriptor area. |
|
EXECUTE |
Execute a prepared statement (except result set generating statements). |
|
EXECUTE IMMEDIATE |
Shorthand form for PREPARE followed by EXECUTE. This form can only be used for fully-defined non-result set statements with no parameter markers. |
|
FETCH |
Fetch rows for a dynamic cursor. |
|
GET DESCRIPTOR |
Get values from the SQL descriptor area. |
|
OPEN |
Open a prepared cursor. |
|
PREPARE |
Compile an SQL source statement into an internal object form. |
|
SET DESCRIPTOR |
Set values in the SQL descriptor area. |
All statements submitted to dynamic SQL programs must be prepared.
All prepared statements and singleton SELECT statements, where the result set contains only one row, are executed with the EXECUTE statement.
All other SELECT statements and calls to result set procedures are executed using OPEN and FETCH for a cursor declared with the prepared statement.
The declaration of a cursor for a statement, DECLARE CURSOR, must always precede the PREPARE operation for the same statement in an application using dynamic SQL.
The SQL descriptor area is used for managing input and output data in dynamically submitted SQL statements containing parameter markers, and for managing result sets (e.g. returned by a SELECT statement.)
An SQL descriptor area is allocated with the ESQL statement ALLOCATE DESCRIPTOR and deallocated with DEALLOCATE DESCRIPTOR. See the Mimer SQL Reference Manual, SQL Statements, for more information.
A program may allocate several separate descriptor areas, identified by different descriptor names. Normally one descriptor is used for input data and one for output data. The describe statement is used to populate an SQL descriptor.
The following statement types can use information from SQL descriptor areas:
•all SELECT statements and calls to result set procedures
•INSERT, DELETE, UPDATE, SET and CALL statements using parameter markers
•ENTER statements.
The following statement types do not use SQL descriptor areas:
•all data definition statements, security control statements, access control statements (except ENTER) and transaction control statements
•INSERT, DELETE, UPDATE and CALL statements using only constant expressions.
In practice, programs using dynamically submitted SQL statements are usually written as though all submitted statements use SQL descriptor areas (since the nature of the submitted statement is not known until run-time).
SQL descriptor areas can be left out of a program only if it is known in advance that they will not be needed (for instance in an application program which will handle only submitted data definition statements).
The Structure of the SQL Descriptor Area
The SQL descriptor area is a storage area holding information about the described statement. It is allocated and maintained with ESQL statements.
It consists of a descriptor header and one or more item descriptor areas. The descriptor header contains two fields, TOP_LEVEL_COUNT and COUNT.
TOP_LEVEL_COUNT is the number of parameters in the descriptor and COUNT is the number of item areas.
The individual fields of the item descriptor area can be accessed with the GET DESCRIPTOR and SET DESCRIPTOR statements. Each descriptor item contains fields for data type, size and scale. The complete list of fields can be seen at Mimer SQL Reference Manual, GET DESCRIPTOR, and Mimer SQL Reference Manual, SET DESCRIPTOR.
All statements submitted to dynamic SQL programs must be prepared. The simplest form of the operation uses a PREPARE statement, see the Mimer SQL Reference Manual, PREPARE, for the syntax description. The operation may also be combined with EXECUTE as a simple statement in the shorthand form EXECUTE IMMEDIATE.
The source form of the statement must be contained in a host variable, containing the statement string. (The statement string itself is not preceded by EXEC SQL nor terminated by the language-specific embedded delimiter.)
The prepared form of the statement is named by an SQL-identifier or a host variable, for extended statements, see Extended Dynamic Cursors.
In the following example the source form of the statement is given as a string constant for illustrative purposes, however, the statement would usually be read from some input source, e.g. the terminal, at run-time:
...
EXEC SQL BEGIN DECLARE SECTION;
string SQL_TXT(255);
...
EXEC SQL END DECLARE SECTION;
...
SQL_TXT := "CREATE INDEX pdt_product_search
ON products(product_search)";
EXEC SQL PREPARE OBJECT FROM :SQL_TXT;
...
A typical cursor is identified by an SQL identifier. An extended cursor makes it possible to represent a dynamic cursor by a host variable or a literal. An extended cursor is allocated by the application with the ALLOCATE CURSOR statement, see the Mimer SQL Reference Manual, ALLOCATE CURSOR, for the syntax description.
When the application is finished with the processing of the SQL statement, the prepared statement may be destroyed by executing the DEALLOCATE PREPARE statement, see the Mimer SQL Reference Manual, DEALLOCATE PREPARE, for the syntax description. DEALLOCATE PREPARE also destroys any extended cursor that was associated with the statement.
Example of how extended cursors are used:
...
EXEC SQL BEGIN DECLARE SECTION;
string SQL_TXT(255);
string C1(128);
string STM1(128);
integer HOSTVAR1;
string HOSTVAR2(10);
...
EXEC SQL END DECLARE SECTION;
...
SQL_TXT := "SELECT col1, col2
FROM tab1";
STM1 := "STMT_1";
EXEC SQL PREPARE :STM1 FROM :SQL_TXT;
C1 := "CUR_1";
EXEC SQL ALLOCATE :C1 CURSOR FOR :STM1;
...
EXEC SQL ALLOCATE DESCRIPTOR 'RESDESC' WITH MAX 50;
EXEC SQL DESCRIBE OUTPUT :STM1 USING SQL DESCRIPTOR 'RESDESC';
...
EXEC SQL OPEN :C1;
EXEC SQL WHENEVER NOT FOUND GOTO done;
loop
EXEC SQL FETCH :C1
INTO SQL DESCRIPTOR 'RESDESC';
EXEC SQL GET DESCRIPTOR 'RESDESC' VALUE 1 :HOSTVAR1 = DATA;
EXEC SQL GET DESCRIPTOR 'RESDESC' VALUE 2 :HOSTVAR2 = DATA;
...
display HOSTVAR1, HOSTVAR2, ...;
end loop;
done:
EXEC SQL CLOSE :C1;
EXEC SQL DEALLOCATE DESCRIPTOR 'RESDESC';
EXEC SQL DEALLOCATE PREPARE :STM1;
...
Describing Prepared Statements
Statements returning a result set and statements containing parameter markers can be described to obtain information about the number and data types of the parameters.
There are two forms of DESCRIBE:
•DESCRIBE OUTPUT for result set values
•DESCRIBE INPUT for input and output parameters.
Both forms of DESCRIBE use the object (prepared) form of the statement as an argument. The same statement may be described in both senses if necessary.
For example:
EXEC SQL BEGIN DECLARE SECTION;
string SQLA1(128);
integer MAXOCC;
string SOURCE(255);
EXEC SQL END DECLARE SECTION;
...
MAXOCC := 15;
SQLA1 := "SQL_AREA_1";
EXEC SQL ALLOCATE DESCRIPTOR :SQLA1 WITH MAX 20;
EXEC SQL ALLOCATE DESCRIPTOR 'SQLA2' WITH MAX :MAXOCC;
...
EXEC SQL PREPARE 'OBJECT' FROM :SOURCE;
EXEC SQL DESCRIBE OUTPUT 'OBJECT' USING SQL DESCRIPTOR :SQLA1;
EXEC SQL DESCRIBE INPUT 'OBJECT' USING SQL DESCRIPTOR 'SQLA2';
...
DESCRIBE places information about the prepared statement in the SQL descriptor areas. See SQL Descriptor Area for a description of the SQL descriptor area.
The contents of the SQL descriptor area is read with the GET DESCRIPTOR statement and updated with the SET DESCRIPTOR statement.
The items in the result set for a statement are described with the DESCRIBE OUTPUT statement. The keyword OUTPUT may be omitted.
The DESCRIBE OUTPUT statement shows:
•whether the statement returns a result set or not. This is indicated by the value of the COUNT field of the SQL descriptor area which is set to zero for statements that do not return a result set. Statements that return a result set are calls to result set procedures, see Result Set Procedures, and select-expressions (refer to the Mimer SQL Reference Manual, SELECT).
•dynamic SQL programs must test for this after each DESCRIBE operation because the treatment of statements that return result sets differs from the treatment of those that do not, see Handling Prepared Statements. If the statement returns a result set, the DESCRIBE statement will place information about the items in the result set in the fields of the descriptor area.
•whether the current descriptor area allocation is sufficient or not. Insufficient area is indicated by the SQLSTATE variable set to a warning state and a value of COUNT (required number of items) greater than that specified in the WITH MAX … clause of the ALLOCATE DESCRIPTOR statement, or greater than 100 if no WITH MAX … clause was specified. If the area is insufficient, no items are described.
The DESCRIBE INPUT statement is used to describe parameter markers.
The value of the COUNT field of the SQL descriptor area indicates the number of parameter markers in the statement (a value of zero indicates no input parameters). A value greater than that specified in WITH MAX … indicates that the allocated SQL descriptor area is too small and the describe operation will not be performed. This situation is handled as described above for DESCRIBE OUTPUT.
Note:If the prepared statement is a call to a stored procedure that uses parameter markers, these will be described by the DESCRIBE INPUT statement. This is regardless of how the formal parameter is specified in the procedure definition. Whether the parameter is IN, INOUT or OUT can be seen from the PARAMETER_MODE field in the descriptor area.
After PREPARE and DESCRIBE, the way in which submitted statements are handled differs according to whether the statement is executable or whether it returns a result set.
•Executable statements are executed using the EXECUTE statement, with the object (prepared) form of the submitted statement as the argument.
•Result set statements, a cursor is used for these statements, associated with the object form of the prepared statement and are executed with OPEN and FETCH.
Executable statements are identified by a value of zero in the COUNT field of the SQL descriptor area after a DESCRIBE OUTPUT statement. If the statement does not contain any parameter markers, it may be executed directly.
If, on the other hand, the statement contains parameter markers, the statement must be executed with an SQL descriptor area for input and output values.
Note:All parameter markers used in a call statement are described with the DESCRIBE INPUT statement, regardless of the mode of the formal parameter.
Parameter markers must be used for all INOUT or OUT parameters when a call statement is prepared dynamically.
The descriptor areas referenced in the EXECUTE statement may be replaced by explicit lists of host variables, provided that the number and data types of the user variables in the source statement are known when the program is written (so that variables can be declared and the appropriate variable list written into the EXECUTE statement).
This facility is of limited use, since the occasions when the user constructs freely chosen SQL statements with a predetermined number of user variables are rare.
EXECUTE IMMEDIATE
The shorthand form EXECUTE IMMEDIATE combines the functions of PREPARE and EXECUTE. This form may only be used for executable statements known to have no parameter markers and is therefore of value only in contexts where the user is restricted to this type of statement. (Data definition and security control statements fall into this category, since user variables are not permitted in the syntax of these statements. EXECUTE IMMEDIATE can therefore be useful for application programs designed specifically to handle database definition statements).
Example
sprintf(ddlstr, "drop ident %s cascade", str);
exec sql EXECUTE IMMEDIATE :ddlstr;
Result Set Statements
Statements returning a result set are identified by a non-zero value in the COUNT field of the SQL descriptor area after DESCRIBE OUTPUT.
Dynamically submitted SELECT statements and calls to result set procedures are handled through cursors. Cursors are declared or allocated for the object (prepared) form of submitted result set returning statements.
Note:A DECLARE CURSOR statement must precede the PREPARE statement in the program code. If ALLOCATE CURSOR is used instead of DECLARE CURSOR, the statement must have been prepared before the cursor can be allocated. The SQL statement must also be prepared before the cursor is opened.
If the source form of the result set returning statement contains parameter markers, these must be described before the cursor is opened and the OPEN statement must reference the relevant descriptor area. In the rare case where the number and data type of the user variables are known when the program is first written, the OPEN statement may reference an explicit variable list instead of a descriptor area.
The descriptor area used for the submitted result set returning statement is referenced when data is retrieved with the FETCH statement.
Example
...
EXEC SQL ALLOCATE DESCRIPTOR 'SQLA1' WITH MAX 30;
EXEC SQL ALLOCATE DESCRIPTOR 'SQLA2' WITH MAX 30;
...
EXEC SQL PREPARE 'OBJECT' FROM :SOURCE;
...
EXEC SQL DESCRIBE OUTPUT 'OBJECT' USING SQL DESCRIPTOR 'SQLA1';
EXEC SQL GET DESCRIPTOR 'SQLA1' :NO_OUT = COUNT;
if NO_OUT = 0 then
RESULT_SET := FALSE;
else
EXEC SQL ALLOCATE 'C1' CURSOR FOR 'OBJECT';
RESULT_SET := TRUE;
end if;
...
EXEC SQL DESCRIBE INPUT 'OBJECT' USING SQL DESCRIPTOR 'SQLA2';
EXEC SQL GET DESCRIPTOR 'SQLA2' :NO_IN = COUNT;
...
if RESULT_SET then
EXEC SQL OPEN 'C1' USING SQL DESCRIPTOR 'SQLA2';
...
EXEC SQL FETCH 'C1' INTO SQL DESCRIPTOR 'SQLA1';
...
else
...
end if;
Example Framework for Dynamic SQL Programs
This section gives a general framework (in pseudo code) for dynamic SQL programs designed to handle any valid SQL statement as input. The framework is largely a synthesis of the example fragments given earlier in this chapter.
The framework is written as a single sequential module to emphasize the order of operations.
Host variable declarations are omitted. Handling of values returned by FETCH is also omitted.
-- Allocate two SQL descriptor areas
EXEC SQL ALLOCATE DESCRIPTOR 'SQLA1' WITH MAX 50;
EXEC SQL ALLOCATE DESCRIPTOR 'SQLA2' WITH MAX 50;
-- read statement from terminal
read INPUT into SOURCE;
-- prepare statement
EXEC SQL PREPARE 'OBJECT' FROM :SOURCE;
-- describe statement and set type/parameter usage flags
EXEC SQL DESCRIBE OUTPUT 'OBJECT' USING SQL DESCRIPTOR 'SQLA1';
EXEC SQL GET DESCRIPTOR 'SQLA1' :NO_OUT = COUNT;
if NO_OUT = 0 then
RESULT_SET := FALSE;
else
-- allocate cursor for result set
EXEC SQL ALLOCATE 'C1' CURSOR FOR 'OBJECT';
RESULT_SET:= TRUE;
end if;
EXEC SQL DESCRIBE INPUT 'OBJECT' USING SQL DESCRIPTOR 'SQLA2';
EXEC SQL GET DESCRIPTOR 'SQLA2' :NO_IN = COUNT;
-- execute statement or open cursor and fetch after assigning
-- values to input variables
if RESULT_SET then
EXEC SQL OPEN 'C1' USING SQL DESCRIPTOR 'SQLA2';
loop
EXEC SQL FETCH 'C1' INTO SQL DESCRIPTOR 'SQLA1';
exit when NO_MORE_REQUIRED or SQLSTATE = "02000";
... -- process results of FETCH
end loop;
EXEC SQL CLOSE 'C1';
else
EXEC SQL EXECUTE 'OBJECT' USING SQL DESCRIPTOR 'SQLA2';
end if;
EXEC SQL DEALLOCATE PREPARE 'OBJECT';
Note:Features that are specific to real host languages are described in Host Language Dependent Aspects.
Handling Errors and Exceptions
Errors may arise at three general levels in an embedded SQL (ESQL) program (not counting errors in the SQL-independent host language code). These are syntax, semantic and run-time errors.
See Managing Exception Conditions for information about managing exception conditions in routines and triggers.
Syntax Errors
Syntax errors are constructions that break the rules for formulating SQL statements. For example:
•Spelling errors in keywords:
SLEECT instead of SELECT
•Incorrect or missing delimiters:
DELETEFROM instead of DELETE FROM
SELECT column1;column2 instead of SELECT column1,column2
•Incorrect clause ordering
UPDATE … WHERE … SET instead of UPDATE … SET … WHERE
The preprocessor does not accept syntactically incorrect statements. The error must be corrected before the program can be successfully preprocessed.
Semantic Errors
Semantic errors arise when SQL statements are formulated in full accordance with the syntax rules, but do not reflect the programmer’s intentions correctly.
Some semantic errors, e.g. incorrect references to database objects, are detected and reported by the ESQL preprocessor but other semantic errors will not become apparent until run-time.
Run-time errors and exception conditions (for example warnings) arising during execution of ESQL statements are signaled by the contents of the SQLSTATE status variable described in The SQLSTATE Variable. A list of possible SQLSTATE values is provided in SQLSTATE Return Codes.
The GET DIAGNOSTICS statement can be used to retrieve detailed information about an exception, see the Mimer SQL Reference Manual, GET DIAGNOSTICS, for the syntax description.
The NATIVE_ERROR and MESSAGE_TEXT fields of the diagnostics area retrieved by using GET DIAGNOSTICS are used to get the internal Mimer SQL return code (aka SQLCODE) and the descriptive text, respectively, relating to the exception, these are listed in Native Mimer SQL Return Codes.
Testing for Run-time Errors and Exception Conditions
The application program may test the outcome of a statement in one of two ways:
•by explicitly testing the contents of the SQLSTATE variable
•by using the SQL statement WHENEVER, see the Mimer SQL Reference Manual, WHENEVER for the syntax description, which tests the class of the SQLSTATE variable.
An application program may contain any number of WHENEVER statements, and the statements may be placed anywhere in the program. A separate WHENEVER statement must be issued for each situation (NOT FOUND, SQLEXCEPTION or SQLWARNING) which is to be tested.
When an exception condition arises, action will be taken as specified in the WHENEVER statement most recently encountered in the code, for the respective condition.
WHENEVER statements are expanded by the preprocessor into explicit tests. These tests are placed after every subsequent SQL statement in that program until a new WHENEVER statement is issued for the same condition.
Two important consequences follow:
•WHENEVER statements are preprocessed strictly in the order in which they appear in the source code, regardless of execution order or conditional execution that the source code might imply.
For instance, the WHENEVER statement in the following Fortran construction is expanded by the preprocessor, even though its execution is never actually requested:
...
GOTO 1025
EXEC SQL WHENEVER SQLEXCEPTION GOTO 1600
1025 CONTINUE
EXEC SQL DELETE FROM MYTABLE
...
•Mixing explicit tests and WHENEVER statements requires care. As a general rule, it is advisable to use either hand-written tests or WHENEVER statements in a program module, and to avoid mixing them.
The condition handling defined by a WHENEVER statement applies to the SQL statements that follow it in the source code. If a GOTO action is defined, the pre-processor inserts an exception test and action directly after each SQL statement affected by it and thus before any hand-written tests in the source code. The hand-written test in this situation would never be executed.
If CONTINUE is specified in a WHENEVER statement, the pre-processor does not insert an exception test and action, thus no exception handling is defined by the WHENEVER statement. Any hand-written tests present in the source code will then take effect.
The interchange between hand-written exception handling and the implicit exception handling inserted by the pre-processor (or not) can be confusing. It is therefore advisable to make a clear coding decision to use one method or the other.
Example using WHENEVER SQLEXCEPTION
#include <stdlib.h>
#include <wchar.h>
int main()
{
exec sql BEGIN DECLARE SECTION;
char sqlstate[6];
nchar varying dbname[129];
nchar varying dbtype[129];
exec sql END DECLARE SECTION;
exec sql WHENEVER SQLEXCEPTION GOTO get_diagn;
exec sql CONNECT TO 'db' USER 'username' USING 'password';
exec sql DECLARE c CURSOR FOR
select databank_name, databank_type
from information_schema.ext_databanks;
exec sql WHENEVER NOT FOUND GOTO end_of_table;
exec sql OPEN c;
while (1)
{
exec sql FETCH c INTO :dbname, :dbtype;
wprintf(L"Databank: %ls\nType: %ls\n\n", dbname, dbtype);
}
end_of_table:
exec sql CLOSE c;
exec sql COMMIT;
exec sql DISCONNECT ALL;
exit(0); /* Exit with success */
get_diagn:
/* print diagnostics message(s) for the most recent statement */
{
exec sql BEGIN DECLARE SECTION;
int i;
int exceptions;
int errcode;
nchar varying message[255];
exec sql END DECLARE SECTION;
exec sql WHENEVER SQLEXCEPTION CONTINUE;
exec sql GET DIAGNOSTICS :exceptions = NUMBER; /* How many exceptions? */
for (i=1; i<=exceptions; i++) {
exec sql GET DIAGNOSTICS EXCEPTION :i
:message = MESSAGE_TEXT, :errcode = NATIVE_ERROR;
wprintf(L"(%d) %ls\n", errcode, message);
}
exec sql ROLLBACK;
exec sql DISCONNECT;
exit(-1); /* Error exit */
}
}
Example using explicit return code checking
#include <stdlib.h>
#include <wchar.h>
void get_diagn();
int main()
{
exec sql BEGIN DECLARE SECTION;
int sqlcode;
nchar varying dbname[129];
nchar varying dbtype[129];
exec sql END DECLARE SECTION;
exec sql CONNECT TO 'db' USER 'username' USING 'password';
if (sqlcode != 0) get_diagn();
exec sql DECLARE c CURSOR FOR
select databank_name, databank_type
from information_schema.ext_databanks;
exec sql OPEN c;
if (sqlcode != 0) get_diagn();
while (sqlcode == 0)
{
exec sql FETCH c INTO :dbname, :dbtype;
if (sqlcode < 0) get_diagn();
if (sqlcode != 100)
wprintf(L"Databank: %ls\nType: %ls\n\n", dbname, dbtype);
}
exec sql CLOSE c;
if (sqlcode != 0) get_diagn();
exec sql COMMIT;
if (sqlcode != 0) get_diagn();
exec sql DISCONNECT ALL;
if (sqlcode != 0) get_diagn();
exit(0); /* Exit with success */
}
void get_diagn()
/* print diagnostics message(s) for the most recent statement */
{
exec sql BEGIN DECLARE SECTION;
int i;
int exceptions;
int errcode;
nchar varying message[255];
int sqlcode;
exec sql END DECLARE SECTION;
exec sql GET DIAGNOSTICS :exceptions = NUMBER; /* How many exceptions? */
for (i=1; i<=exceptions; i++) {
exec sql GET DIAGNOSTICS EXCEPTION :i
:message = MESSAGE_TEXT, :errcode = NATIVE_ERROR;
wprintf(L"(%d) %ls\n", errcode, message);
}
exec sql ROLLBACK;
exec sql DISCONNECT;
exit(-1); /* Error exit */
}