This chapter discusses the scope, principles, processing and structure of Module SQL (MSQL).
MSQL enables you to call SQL statements in a host program written in C/C++, COBOL, Fortran or Pascal, without embedding the actual SQL statements in the host program. The SQL statements are explicitly put into a separate SQL module, that is written in the Module language and maintained separately from the host program.
The Mimer MSQL files are pre-processed through the Mimer Module SQL pre-processor into Embedded C code. The resulting Embedded C code can then be processed through the Mimer Embedded SQL pre-processor into C code which can be compiled, and then linked together with the host application.
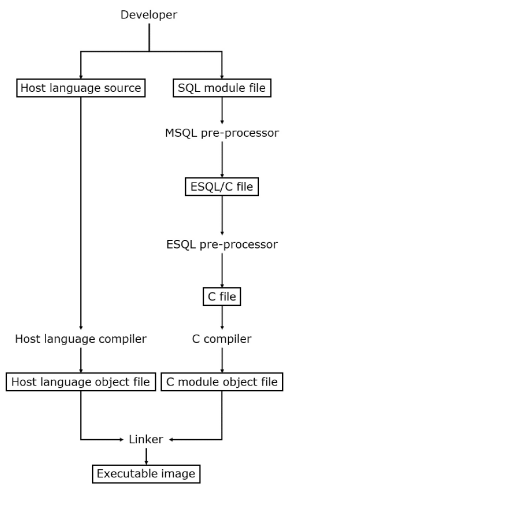
The SQL statements supported are therefore limited to the SQL statements supported by Embedded SQL, which are described in Embedded SQL.
General Principles for SQL Modules
The following sections discuss host languages, pre-processors, identifying SQL statements, code, comments and recommendations.
Host languages
You can call the C code that comes out of the MSQL pre-processor from any host language that supports the used data types. Mimer MSQL supports C/C++, COBOL, Fortran and Pascal.
Information given in this manual applies to all languages unless otherwise explicitly stated. Language-specific information is detailed in Host Language Dependent Aspects.
Writing an SQL module
An SQL module is a list of SQL statements, where each SQL statement is included in a procedure. Each procedure contains only one SQL statement. The MSQL syntax is case insensitive. Routine, cursor and parameter names (except SQLCODE and SQLSTATE) are case sensitive, as they will follow to the generated C code which is case sensitive.
The syntax for declaring an SQL module is as follows:
MODULE module-name
LANGUAGE (C|COBOL|FORTRAN|PASCAL)
The LANGUAGE clause tells the module which host language it will be called from and adapts some data types to the given host language. For a full list of how a host application should handle all Mimer SQL data types, see Host Language Dependent Aspects.
LANGAUGE C
•The CHARACTER, VARCHAR, BOOLEAN, DATETIME and INTERVAL SQL data types are handled like a null-terminated C char array in the generated MSQL C code. When calling module procedures, all host languages need to make room for and apply null-termination. The Fortran CHARACTER data type cannot be used. This includes SQLSTATE.
•The CLOB SQL data type is handled like a C struct specified according to the SQL standard in the generated MSQL C code. When calling module procedures, all host languages need to use corresponding data structures.
•The DECIMAL SQL data type is handled like a C double in the generated MSQL C code. When calling module procedures, all host languages need to use corresponding data types. The COBOL PACKED DECIMAL (COMP-3) data type cannot be used.
LANGUAGE FORTRAN
•The CHARACTER, VARCHAR, BOOLEAN, DATETIME and INTERVAL SQL data types are handled like a fixed length Fortran CHARACTER array in the generated MSQL C code, without null termination. This includes SQLSTATE.
•The CLOB SQL data type is handled like a fixed length Fortran CHARACTER array in the generated MSQL C code, without null termination.
•The DECIMAL SQL data type is handled like a C double in the generated MSQL C code. When calling module procedures, the Fortran application needs to use the corresponding data type.
LANGUAGE COBOL
•The CHARACTER, VARCHAR, BOOLEAN, DATETIME and INTERVAL SQL data types are handled like a fixed length COBOL PICTURE X array in the generated MSQL C code, without null termination. This includes SQLSTATE.
•The CLOB SQL data type is handled like a fixed length COBOL PICTURE X array in the generated MSQL C code, without null termination.
•The DECIMAL SQL data type is handled like a COBOL PACKED DECIMAL (COMP-3) data type of the expected precision and scale in the generated MSQL C code.
LANGUAGE PASCAL
•The CHARACTER, VARCHAR, BOOLEAN, DATETIME and INTERVAL SQL data types are handled like a fixed length Pascal PACKED ARRAY OF CHAR in the generated MSQL C code, without null termination. This includes SQLSTATE.
•The CLOB SQL data type is handled like a fixed length COBOL Pascal PACKED ARRAY OF CHAR in the generated MSQL C code, without null termination.
•The DECIMAL SQL data type is handled like a C double in the generated MSQL C code. When calling module procedures, the Pascal application needs to use the corresponding data type.
The SQLCODE parameter is always translated to a pointer to an integer, no matter the chosen module language.
Cursor declarations
All cursors that are to be used in the module's procedures need to be declared before any procedure is declared. A cursor is declared using the corresponding SQL syntax as follows:
DECLARE cursor-name CURSOR FOR cursor-statement
A module can contain multiple cursor declarations. They all need to be declared before the module procedures, and they are delimited by new rows. The cursor declaration can be split on more than one row wherever a white-space is permitted.
DECLARE cursor-name1 CURSOR FOR
cursor-statement1
DECLARE cursor-name2
CURSOR FOR
cursor-statement2
Module procedures
Following the module and cursor declarations, the procedures that execute SQL statements are declared. An SQL module language procedure has a name, parameter declarations, and an executable SQL statement.
The syntax for declaring an SQL module procedure is as follows:
PROCEDURE procedure-name
[parameter-declaration
[, parameter-declaration];
SQL statement;
The syntax for the parameter declaration is as follows:
:parameter-name datatype
or
SQLSTATE
or
SQLCODE
Example:
PROCEDURE fetch_data
:param_1 INTEGER
:param_2 SMALLINT
SQLSTATE;
FETCH data_cursor INTO
:param_1,
:param_2;
The parameters may be input parameters, output parameters or both.
Parameters are separated by commas or whites paces and ended with semicolon.
SQLSTATE and SQLCODE parameters are status parameters through which errors are passed. Use either, not both, in the same SQL module. Using both in the same SQL module causes undefined behavior.
Comments
You can comment your SQL module file with double dashes, as follows:
-- A very useful cursor.
DECLARE cursor-name CURSOR FOR cursor-statement
Comments are not forwarded to the embedded C and C code.
Recommendations
We recommend the following when writing MSQL:
•Avoid variable names beginning with the letters SQL (except for SQLSTATE and SQLCODE, which should be used when appropriate).
•Avoid procedure names ending with a number.
•Avoid separating identifiers (e.g. procedure or parameter names) with casing only. Even though the generated C code might be valid, the calling host language might be case insensitive.
Calling an SQL module
In the host program, you call an SQL procedure at whatever point in the host program you want to execute the SQL statement in that procedure. You call the SQL procedure as if it was a subprogram in C.
The following SQL module procedure:
PROCEDURE fetch_data
:param_1 INTEGER
:param_2 SMALLINT
SQLSTATE;
FETCH data_cursor INTO
:param_1,
:param_2;
will be processed into the following C function:
void fetch_data(int* param_1, short* param_2, char sqlstate[6])
When calling this function from your host program, the parameters you send need to be compatible with the C data types in the C function. Input char arrays might need to be null-terminated, as per C standard, see Writing an SQL module - Module declaration and Host Language Dependent Aspects for more details.
The following sections discuss pre-processing and processing MSQL.
Pre-processing - the MSQL command
An SQL module file must first be pre-processed using the MSQL command, then pre-processed using the ESQL command (see Processing ESQL), before it is compiled with the C compiler.
The input to the pre-processor is thus an SQL module written in Module language.
The output from the preprocessor is always an Embedded C source code file, containing both C and ESQL statements. If the host language is C, an Embedded C header file is also generated.
The default file extensions for preprocessor input and output files are shown in the table below:
|
Input file extension |
Output file extension |
Header file extension |
|---|---|---|
|
.msq |
.ec |
.eh |
Invoking the MSQL Preprocessor
The MSQL preprocessor has the following command line syntax:
msql [-n] [-i enc] [-o enc] [-b yes|no] [-u yes|no] infile [outfile [headerfile]]
msql [--nologo] [--inencoding=enc] [--outencoding=enc] [--inbom=yes|no]
[--outbom=yes|no] infile [outfile [headerfile]]
msql [-v|--version] | [-?|--help]
Options
|
Unix-style |
VMS-style |
Function |
|---|---|---|
|
-n --nologo |
/NOLOGO |
Suppresses the display of the copyright message on the screen (warnings and errors are always displayed on the screen.) |
|
-i encoding --inencoding=encoding |
/INENCODING=encoding |
The encoding to read the input file in. Valid options are: The default encoding is platform and locale dependent. Sets to default if omitted. |
|
-o encoding --outencoding=encoding |
/OUTENCODING=encoding |
The encoding to write the output file in. Valid options are: The default encoding is platform and locale dependent. Equals the input file encoding if omitted. |
|
-b yes/no --inbom=yes/no |
/INBOM=yes/no |
If BOM should explicitly be used/not used when reading from the input file. Valid options are: Uses the inencoding's default if omitted. |
|
-u yes/no --outbom=yes/no |
/OUTBOM=yes/no |
If BOM should explicitly be used/not used when writing to the output file. Valid options are: Uses the outencoding's default if omitted. |
|
infile |
infile |
The input-file containing the SQL module source code to be pre-processed. If no file extension is specified, the .msq file extension is assumed (previously described in this section.) |
|
[outfile] |
[outfile] |
The output-file which will contain the Embedded C code generated by the preprocessor. If not specified, the output file will have the same name as the input file, but with the .ec file extension (previously described in this section.) |
|
[headerfile] |
[headerfile] |
The header-file which will contain the Embedded C header generated by the preprocessor. If not specified, the header file will have the same name as the output file, but with the .eh file extension (previously described in this section.) If the input file has a target host language other than C, this argument will not be used. |
Note:As an application programmer, you should never attempt to directly modify the output from the preprocessor.
Any changes that may be required in an SQL module should be introduced into the original SQL module code. Mimer Information Technology AB cannot accept any responsibility for the consequences of modifications to the pre-processed code.
What Does the Preprocessor Do?
The preprocessor checks the syntax (See Handling errors and exceptions for a more detailed discussion of how errors are handled.) Syntactically invalid statements cannot be pre-processed and the source code must be corrected.
Processing MSQL
Compiling
The output from the MSQL and ESQL preprocessors is compiled in the usual way using the appropriate C compiler and linked with the appropriate routine libraries.
|
Linux:On Linux platforms, the gcc compiler is supported. |
|
VMS:The VSI C compiler and the HP C compiler are supported on the OpenVMS platform. |
|
Win:On Windows platforms, the C compiler identified by the cc symbol in the file .\dev\samples\makefile_msql.mak below the installation directory is supported. |
Note:Other compilers, from other software distributors, may or may not be able to compile the MSQL and ESQL preprocessor output. Mimer Information Technology cannot guarantee the result of using a compiler that is not supported.
Linking
Linking the processed SQL module with a host application is done in the same way as user-written embedded C code, see Linking Applications.
The SQL Compiler
At run-time, database management requests are passed to the SQL compiler responsible for implementing the SQL functions in the application program.
The SQL compiler performs two functions:
•It checks SQL statements semantically against the data dictionary.
•It optimizes operations performed against the database (i.e. internal routines determine the most efficient way to execute the SQL request, with regard to the existence of secondary indexes and the number of rows in the tables addressed by the statement). You, as a programmer, do not need to worry, for instance, about the order in which tables are addressed in a complex selection condition. This optimization process is completely transparent.
Note:Since all SQL statements are compiled at run-time, there can be no conflict between the state of the database at the times of compilation and execution. Moreover, the execution of SQL statements is always optimized with reference to the current state of the database.
Connecting to a Database
Connecting to a database is done much in the same way as in embedded programs, see Connecting to a Database. Every connect attempt is a separate SQL statement that needs its own module procedure.
Examples
Example SQL module:
PROCEDURE connect_ident
:ident VARCHAR(100)
:pswd VARCHAR(100)
SQLSTATE;
CONNECT TO 'the_database' USER :ident USING :pswd;
Example host application in C:
#include "module_name.h"
int main()
{
char sqlstate[6];
char ident[101] = "SYSADM";
char pswd[101] = "SYSADM";
connect_ident(ident, pswd, &sqlcode);
Example host application in Fortran:
CHARACTER*5 SQLSTATE
CHARACTER*100 IDENT
CHARACTER*100 PSWD
IDENT = 'SYSADM'
PSWD = 'SYSADM'
CALL CONNECT_IDENT(IDENT, PSWD, SQLSTATE)
Example host application in Cobol:
DATA DIVISION.
WORKING-STORAGE SECTION.
01 SQLSTATE PIC X(5).
01 IDENT PIC X(100).
01 PSWD PIC X(100).
PROCEDURE DIVISION.
HEAD SECTION.
MAIN.
MOVE "SYSADM" TO IDENT.
MOVE "SYSADM" TO PSWD.
CALL "CONNECT_IDENT" USING IDENT, PSWD, SQLSTATE.
Example host application in Pascal:
type chararray = packed array [1..100] of char;
type sqlstatearray = packed array [1..5] of char;
var
sqlstate : sqlstatearray;
ident : chararray;
pswd : chararray;
procedure connect_ident(var ident : chararray, var pswd : chararray,
var sqlstate: sqlstatearray); external;
begin
ident := 'SYSADM';
pswd := 'SYSADM';
connect_ident(ident, pswd, sqlstate);
Communicating with the Application Program
Information is transferred between the host application program and the Mimer SQL database manager through an SQL module much in the same way as in embedded SQL programs, see Communicating with the Application Program.
Indicator variables
In MSQL, as in ESQL, indicator variables associated with main variables are used to handle null values in database tables. Indicator variables are declared in the parameter list to a module procedure like the main parameters, with the SQL data type SMALLINT. It is translated to the C type short. The host language then provides the variable in the parameter list in the same way as the main variables.
PROCEDURE fetch_name
:name VARCHAR(20)
:name_indicator SMALLINT
SQLSTATE;
FETCH name_cursor INTO :name:name_indicator;
Accessing data
This section explains how SQL modules retrieve data.
Retrieving data using cursors
Data is retrieved much in the same way as in ESQL, see Accessing Data. The host application will have to check the value of SQLCODE or SQLSTATE in order to find out when the cursor has reached the end of the result set.
Examples
Example SQL module:
DECLARE currencies_cursor CURSOR FOR
SELECT code FROM mimer_store.currencies
PROCEDURE open_currencies_cursor
SQLSTATE;
OPEN currencies_cursor;
PROCEDURE fetch_currency_code
:code CHARACTER(3)
SQLSTATE;
FETCH currencies_cursor INTO :code;
PROCEDURE close_currencies_cursor
SQLSTATE;
CLOSE currencies_cursor;
Example host application in C:
#include "module_name.h"
int main()
{
int sqlcode;
char code[4];
open_currencies_cursor(&sqlcode);
while (sqlcode == 0)
{
fetch_currency_code(code, &sqlcode);
}
close_currencies_cursor(&sqlcode);
Example host application in Fortran:
INTEGER*4 SQLCODE
CHARACTER*3 CODE
CALL OPEN_CURRENCIES_CURSOR(SQLCODE)
DO WHILE (SQLCODE .EQ. 0) THEN
CALL FETCH_CURRENCY_CODE(CODE, SQLCODE)
END DO
CALL CLOSE_CURRENCIES_CURSOR(SQLCODE)
Example host application in Cobol:
DATA DIVISION.
WORKING-STORAGE SECTION.
01 SQLCODE PIC S9(9) USAGE IS BINARY.
01 CODE PIC X(3).
PROCEDURE DIVISION.
HEAD SECTION.
MAIN.
CALL "OPEN_CURRENCIES_CURSOR" USING SQLCODE.
PERFORM UNTIL SQLCODE IS NOT ZERO
CALL "FETCH_CURRENCY_CODE" USING NAME, SQLCODE.
END-PERFORM.
CALL "CLOSE_CURRENCIES_CURSOR" USING SQLCODE.
Example host application in Pascal:
type currency_code_type = packed array [1..3] of char;
var
sqlcode : integer;
code : currency_code_type;
procedure open_currencies_cursor(var sqlcode : integer); external;
procedure fetch_currency_code(var code : currency_code_type,
var sqlcode : integer); external;
procedure close_currencies_cursor(var sqlcode : integer); external;
begin
open_currencies_cursor(sqlcode);
while sqlcode = 0 do
begin
fetch_currency_code(code, sqlcode);
end
close_currencies_cursor(sqlcode);
Retrieving single rows
See Accessing Data for detailed information on how retrieving single rows work. It is done in an SQL module by declaring a procedure for the specific statement.
Dynamic SQL can be used in the same way as in ESQL, see Dynamic SQL. The PREPARE and EXECUTE operations are performed through module procedures.
PROCEDURE prepare_stmnt
:stmnt VARCHAR(300)
SQLCODE;
PREPARE statement1 FROM :stmnt;
PROCEDURE execute_prepared
SQLCODE;
EXECUTE statement1;
Handling errors and exceptions
Errors may arise at three general levels in an SQL module. These are syntax, semantic and run-time errors.
Syntax Errors
Syntax errors are constructions that break the rules for formulating SQL statements. For example:
•Spelling errors in keywords:
SLEECT instead of SELECT
•Incorrect or missing delimiters:
DELETEFROM instead of DELETE FROM
SELECT column1;column2 instead of SELECT column1,column2
•Incorrect clause ordering
UPDATE … WHERE … SET instead of UPDATE … SET … WHERE
The preprocessor does not accept syntactically incorrect statements. The error must be corrected before the program can be successfully preprocessed.
Semantic Errors
Semantic errors arise when SQL statements are formulated in full accordance with the syntax rules, but do not reflect the programmer's intentions correctly. Semantic errors are not detected by the MSQL preprocessor.
Run-time Errors
Run-time errors and exception conditions (for example warnings) arising during execution of SQL module procedures are signaled in the same was as in ESQL, see Handling Errors and Exceptions.
The errors cannot be caught with WHENEVER statements that are used in ESQL, the host application has to rely on the values of SQLCODE and SQLSTATE.
Examples
Example SQL module:
PROCEDURE connect_sysadm
SQLCODE;
CONNECT TO '' USER 'SYSADM' USING 'SYSADM';
PROCEDURE get_diagn
:errcode INT
:errmsg VARCHAR(300)
SQLCODE;
GET DIAGNOSTICS EXCEPTION 1
:errcode = native_error,
:errmsg = message_text;
Example host application in C:
void connect_sysadm(int* sqlcode);
void get_diagn(int* errcode, char errmsg[301], int* sqlcode);
int main()
{
int sqlcode;
int errcode;
char errmsg[301];
connect_sysadm(&sqlcode);
if (sqlcode != 0)
{
printf("Failed to connect SYSADM.\n");
get_diagn(&errcode, errmsg, &sqlcode);
if (sqlcode != 0)
{
printf("Failed to get diagnostics message.\n");
}
else
{
printf("errcode: %d\n", errcode);
printf("errmsg: %s\n", errmsg);
}
}
Example host application in Fortran:
INTEGER*4 SQLCODE
INTEGER*4 ERRCODE
CHARACTER*300 ERRMSG
CALL CONNECT_SYSADM(SQLCODE)
IF (SQLCODE .NE. 0) THEN
PRINT *, 'Failed to connect SYSADM.'
IF (SQLCODE .NE. 0) THEN
PRINT *, 'Failed to get diagnostics message.'
ELSE
PRINT *, 'errcode: ', ERRCODE
WRITE(*, '(X,72A)') 'errmsg: ', ERRMSG
END IF
END IF
Example host application in Cobol:
DATA DIVISION.
WORKING-STORAGE SECTION.
01 SQLCODE PIC S9(9) USAGE IS BINARY.
01 ERRCODE PIC S9(9) USAGE IS BINARY.
01 ERRMSG PICTURE X(300).
PROCEDURE DIVISION.
HEAD SECTION.
MAIN.
CALL "CONNECT_SYSADM" USING SQLCODE.
IF SQLCODE IS NOT ZERO
DISPLAY "Failed to connect SYSADM."
CALL "GET_DIAGN" USING ERRCODE, ERRMSG, SQLCODE.
IF SQLCODE IS NOT ZERO
DISPLAY "Failed to get diagnostics message."
ELSE
DISPLAY "errcode: " ERRCODE
DISPLAY "errmsg: " ERRMSG
END-IF.
END-IF.
Example host application in Pascal:
type message = packed array [1..300] of char;
var
sqlcode : integer;
errcode : integer;
errmsg : message;
procedure connect_sysadm(var sqlcode : integer); external;
procedure get_diagn(var errcode : integer, var errmsg : message,
var sqlcode : integer); external;
begin
connect_sysadm(sqlcode);
if sqlcode <> 0 then
begin
writeln('Failed to connect SYSADM.');
get_diagn(errcode, errmsg, sqlcode);
if sqlcode <> 0 then
begin
writeln('Failed to get diagnostics message.');
end;
else
begin
writeln('errcode: ', errcode)
writeln('errmsg: ', errmsg);
end;
Host Language Dependent Aspects
You can call SQL modules (MSQL) in any host language that supports the C data types generated by the MSQL preprocessor. The following host languages are supported:
•C/C++
•COBOL
•Fortran
•Pascal
Note:This is not a complete description of the rules for writing SQL modules. The programmer should use the main body of this manual as a guide to writing programs and refer to this appendix for language-specific details.
This section describes the recommended data types to use in each of the above mentioned host languages when calling an SQL module procedure.
The SQL data types INT(n>18), FLOAT, BINARY and VARBINARY are handled by Module SQL as null-terminated C char arrays, no matter the calling host language. The host application needs to apply null termination to any input, and take precautions to null termination appearing in any output.
The SQL data types DATE, TIME, TIMESTAMP, INTERVAL, CHAR, VARCHAR, CLOB and BOOLEAN are handled by Module SQL as character arrays of the given host language, see Module declaration for more details.
C header files
When the LANGUAGE clause in an SQL module is set to C, a C header file containing embedded SQL statements will be generated by the MSQL preprocessor, by default with the .eh file extension. The embedded SQL header file needs to be pre-processed using the ESQL command into a pure C header file (the header file name and extension has to be specified to ESQL.) It can then be included in the C host application to provide the routine headers for the routines generated in the source code file.
Example
The SQL module currencies.msq has the LANGUAGE clause set to C. It is pre-processed using the MSQL command.
msql currencies.msq
The embedded SQL files currencies.ec and currencies.eh are generated. They are pre-processed using the ESQL commands.
esql --c currencies.ec
esql --header currencies.eh
or
esql /C currencies.ec
esql /HEADER currencies.eh
The C source file currencies.c is generated, containing the source code that calls the Mimer database. The C header file currencies.h is generated for inclusion in the C host application program.
#include "currencies.h"
int main
{
int sqlcode;
open_currencies_cursor(&sqlcode);
C data types
|
SQL data type |
C data type |
|---|---|
|
BIGINT |
long long* int64_t* |
|
BINARY(n) |
unsigned char[n+1] |
|
BLOB(size) |
struct { long hvn_reserved; unsigned long hvn_length; char hvn_data[size]; } hvn; |
|
BOOLEAN |
char[6] |
|
CHAR(n) |
char[n+1] |
|
CLOB(size) |
struct { long hvn_reserved; unsigned long hvn_length; char hvn_data[size]; } hvn; |
|
DATE |
char[100] |
|
DECIMAL(p) DECIMAL(p,s) |
double* |
|
DOUBLE PRECISION |
double* |
|
FLOAT |
double* |
|
FLOAT(n) |
char[n+8] |
|
INTEGER |
int* int32_t* |
|
INTEGER(n) |
n <= 4: short*, int16_t* 5 <= n<= 9: int*, int32_t* 10 <= n <= 18: long long*, int64_t* 19 <= n <= 45: char[n+2] |
|
INTERVAL data types |
char[100] |
|
NCHAR(n) |
wchar_t[n+1] |
|
NCLOB(size) |
struct { long hvn_reserved; unsigned long hvn_length; wchar_t hvn_data[size]; } hvn; |
|
NVARCHAR(n) |
wchar_t[n+1] |
|
REAL |
float* |
|
SMALLINT |
short* int16_t* |
|
SQLCODE |
int* int32_t* |
|
SQLSTATE |
char[6] |
|
TIME data types |
char[100] |
|
TIMESTAMP data types |
char[100] |
|
VARBINARY(n) |
unsigned char[n+1] |
|
VARCHAR(n) |
char[n+1] |
Note:The stdint types int16_t, int32_t and int64_t can be used in the host application if desired. The SQL module does not use them.
COBOL data types
|
SQL data type |
COBOL data type |
|---|---|
|
BIGINT |
PIC S9(18) USAGE IS BINARY |
|
BINARY(n) |
PICTURE X(n+1) |
|
BLOB(size) |
01 hvn. 49 hvn-RESERVED PIC S9(18) USAGE IS BINARY. 49 hvn-LENGTH PIC S9(18) USAGE IS BINARY. 49 hvn-DATA PIC X(size). |
|
BOOLEAN |
PICTURE X(5) |
|
CHAR(n) |
PICTURE X(n) |
|
CLOB(size) |
PICTURE X(size) |
|
DATE |
PICTURE X(100) |
|
DECIMAL(p) DECIMAL(p,0) |
PIC S9(p) COMP-3 |
|
DECIMAL(p,s) |
PIC S9(p)V9(s) COMP-3 |
|
DOUBLE PRECISION |
COMP-2 |
|
FLOAT |
COMP-2 |
|
FLOAT(n) |
PICTURE X(n+8) |
|
INTEGER |
PIC S9(9) USAGE IS BINARY |
|
INTEGER(n) |
1 <= n <= 4: PIC S9(4) USAGE IS BINARY 5 <= n <= 9: PIC S9(9) USAGE IS BINARY 10 <= n <= 18: PIC S9(18) USAGE IS BINARY 19 <= n <= 45: PICTURE X(n+2) |
|
INTERVAL data types |
PICTURE X(100) |
|
REAL |
COMP-1 |
|
SMALLINT |
PIC S9(4) USAGE IS BINARY |
|
SQLCODE |
PIC S9(9) USAGE IS BINARY |
|
SQLSTATE |
PIC X(5) |
|
TIME data types |
PICTURE X(100) |
|
TIMESTAMP data types |
PICTURE X(100) |
|
VARBINARY(n) |
PICTURE X(n+1) |
|
VARCHAR(n) |
PICTURE X(n) |
Fortran data types
|
SQL data type |
Fortran data type |
|---|---|
|
BIGINT |
INTEGER*8 |
|
BINARY(n) |
INTEGER*1(n+1) |
|
BLOB(size) |
INTEGER*1 hvn(size + 8) INTEGER*8 hvn_RESERVED INTEGER*8 hvn_LENGTH INTEGER*1 hvn_DATA(size) EQUIVALENCE(hvn(1), hvn_RESERVED) EQUIVALENCE(hvn(9), hvn_LENGTH) EQUIVALENCE(hvn(17), hvn_DATA) |
|
BOOLEAN |
CHARACTER*5 |
|
CHARACTER(n) |
CHARACTER*n |
|
CLOB(size) |
CHARACTER*size |
|
DATE |
CHARACTER*100 |
|
DECIMAL(p) DECIMAL(p,s) |
DOUBLE PRECISION |
|
DOUBLE PRECISION |
DOUBLE PRECISION |
|
FLOAT |
DOUBLE PRECISION |
|
FLOAT(n) |
INTEGER*1(n+8) |
|
INTEGER |
INTEGER*4 |
|
INTEGER(n) |
1 <= n <= 4: INTEGER*2 5 <= n <= 9: INTEGER*4 10 <= n <= 18: INTEGER*8 19 <= n <= 45: INTEGER*1(n+2) |
|
INTERVAL data types |
CHARACTER*100 |
|
REAL |
REAL |
|
SMALLINT |
INTEGER*2 |
|
SQLCODE |
INTEGER*4 |
|
SQLSTATE |
CHARACTER*5 |
|
TIME data types |
CHARACTER*100 |
|
TIMESTAMP data types |
CHARACTER*100 |
|
VARBINARY(n) |
INTEGER*1(n+1) |
|
VARCHAR(n) |
CHARACTER*n |
Pascal data types
|
SQL data type |
Pascal data type |
|---|---|
|
BIGINT |
integer64 |
|
BINARY(n) |
packed array [1..n+1] of char |
|
BLOB(size) |
TYPE X = RECORD hvn_RESERVED : INTEGER64; hvn_LENGTH : INTEGER64; hvn_DATA : PACKED ARRAY [1..size] OF CHAR; END; |
|
BOOLEAN |
packed array [1..5] of char |
|
CHARACTER(n) |
packed array [1..n] of char |
|
CLOB(size) |
packed array [1..size] of char |
|
DATE |
packed array [1..100] of char |
|
DECIMAL(p) DECIMAL(p,s) |
double |
|
DOUBLE PRECISION |
double |
|
FLOAT |
double |
|
FLOAT(n) |
packed array [1..n+8] of char |
|
INTEGER |
integer32 |
|
INTEGER(n) |
1 <= n <= 4: integer16 5 <= n <= 9: integer32 10 <= n <= 18: integer64 19 <= n <= 45: packed array [1..n+2] of char |
|
INTERVAL data types |
packed array [1..100] of char |
|
NCHAR(n) |
packed array [1..n] of char |
|
NCLOB(size) |
TYPE X = RECORD hvn_RESERVED : INTEGER64; hvn_LENGTH : INTEGER64; hvn_DATA : PACKED ARRAY [1..size] OF CHAR; END; |
|
NVARCHAR(n) |
packed array [1..n] of char |
|
REAL |
single |
|
SMALLINT |
integer16 |
|
SQLCODE |
integer32 |
|
SQLSTATE |
packed array [1..5] of char |
|
TIME data types |
packed array [1..100] of char |
|
TIMESTAMP data types |
packed array [1..100] of char |
|
VARBINARY(n) |
packed array [1..n+1] of char |
|
VARCHAR(n) |
packed array [1..n] of char |