A select-expression defines a set of data (rows and columns) extracted from one or more tables or views.
The select-expression syntax is:
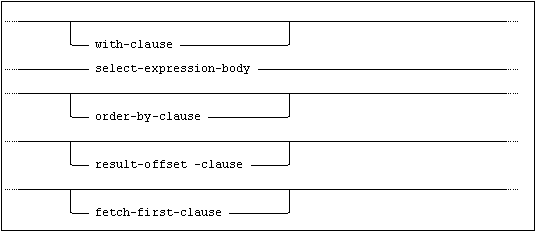
and select-expression-body is:
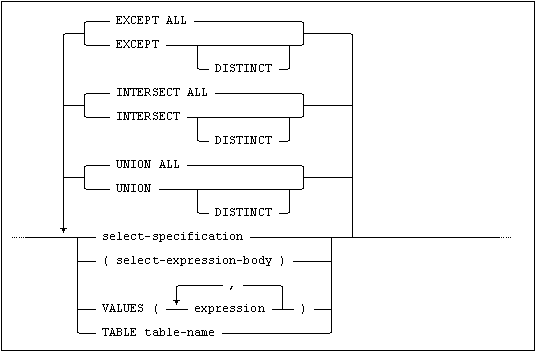
where the select-specification syntax is:
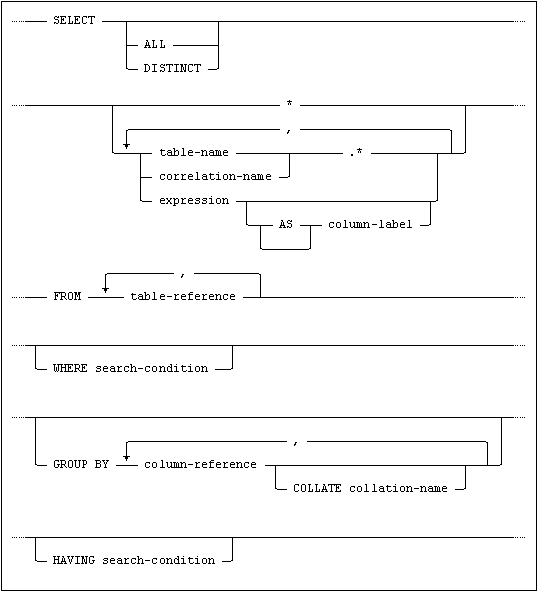

The different clauses in the specifications above are described in detail in the following sections.
The SELECT clause defines which values are to be selected. Values are specified by column references or expressions; where columns are addressed, the value selected is the content of the column.
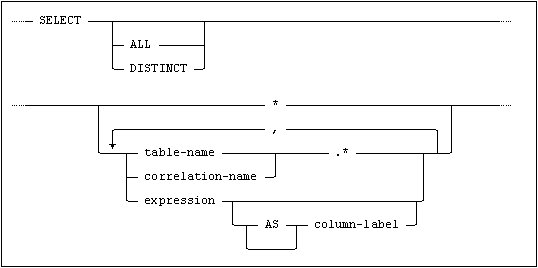
This form of the SELECT clause specifies all columns in the Cartesian product of the tables specified in the FROM clause. The single asterisk may not be combined with any other value specification.
Example
SELECT * FROM countries ...
Note:Use of SELECT * is discouraged in programs (except in EXISTS predicates) since the asterisk is expanded to a column list when the statement is compiled, and any subsequent alterations in the table or view definitions may cause the program to function incorrectly.
If a named table or view (table-name or correlation-name) is followed by an asterisk in the SELECT clause, all columns are selected from that table or view.
This formulation may be used in a list of select specifications.
If a correlation-name is used, it must be defined in the associated FROM clause, see The FROM Clause and Table-reference.
Note:Use of SELECT table.* is discouraged in programs (except in EXISTS predicates) since the asterisk is expanded to a column list when the statement is compiled, and any subsequent alterations in the table or view definitions may cause the program to function incorrectly.
Values to be selected may be specified as expressions (using column-references, set functions and literals, see Expressions).
Column names used in expressions must refer to columns in the tables addressed in the FROM clause or be an outer reference.
A column name must be qualified if more than one column in the set of table references addressed in the FROM clause has the same name.
A column-label may be added after each separate expression in the SELECT clause. column-label is an SQL identifier which becomes the name of the column in the result set.
If no name is given the original column name is used, unless the new column was created by an expression, in which case the new column has no name.
For example, SELECT COLUMN_NAME would result in a column called COLUMN_NAME in the result set, but SELECT COLUMN_NAME + 1 would result in a column in the result set with no name.
If ALL is specified or if no keyword is given, duplicate rows are not eliminated from the result of the select-specification.
If DISTINCT is specified, duplicate rows are eliminated. Null is considered to be equal to null in this context.
The FROM Clause and Table-reference
The FROM clause defines an intermediate result set for the select-specification, and may define correlation names for the table references used in the result set.

where table-reference is:
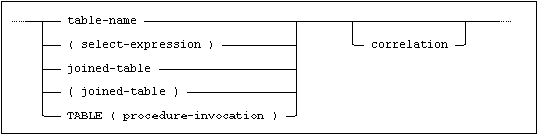
where correlation is:

and procedure-invocation is:

General Syntax
All source tables or views referenced in the SELECT clause and at the top level in the WHERE clause (but not in any subquery used in the WHERE clause) must be named in the FROM clause.
If a single table or view is named in the FROM clause, the intermediate result set is identical to the table or view.
If the FROM clause names more than one table or view, the intermediate result set may be regarded as the complete Cartesian product of the named tables or views.
Note:The intermediate result set is a conceptual entity, introduced to aid in understanding of the selection process. The complete result set does not have any direct physical existence, so that the machine resources available do not need to correspond to the (sometimes very large) Cartesian product tables implied by multiple table references in a FROM clause.
Correlation names introduced in the FROM clause redefine the form of the table name which may be used to qualify column names, see Qualified Object Names.
Correlation names may be used for several purposes:
•to shorten table names, which saves typing and makes statements easier to follow and less error-prone.
•to relate a table to a logical copy of itself.
•to rename a column when a column with the same name exists in another of the query’s tables.
A table or view name is exposed in the FROM clause if it does not have a correlation name. The same table or view name cannot be exposed more than once in the same FROM clause.
The same correlation name may not be introduced more than once in the same FROM clause, and it cannot be the same as an exposed table or view name.
The WHERE clause selects a subset of the rows in the intermediate result set on the basis of values in the columns. If no WHERE clause is specified, all rows of the intermediate result set are selected.

All column references in the search-condition must uniquely identify a column in the intermediate result set defined by the FROM clause or be an outer reference.
Column references must be qualified if more than one column in the intermediate result set has the same name, or if the column is an outer reference.
The GROUP BY clause determines grouping of the result table for the application of set functions specified in the SELECT clause.
The GROUP BY clause has the following syntax:
If a GROUP BY clause is specified, each column reference in the SELECT list must either identify a grouping column or be the argument of a set function.
The rows of the intermediate result set are (conceptually) arranged in groups, where all values in the grouping column(s) are identical within each group.
Each group is reduced to a single row in the final result of the select-specification.
If a GROUP BY clause is not specified, the SELECT list must either be a list that does not include any set functions or a list of set functions and optional literal expressions.
Collations determine the sort order of character data. If the COLLATE clause is specified, the resulting data will be grouped according to the collation specified. For more information, see the Mimer SQL User's Manual, Collations.
If no COLLATE clause is specified, the column’s implicit collation will be used.
The HAVING clause restricts selection of groups in the same way that a WHERE clause restricts selection of rows.
The HAVING clause has the following syntax:

The search condition in the HAVING clause defines restrictions on the values in the elements of the SELECT list. Column references in the search condition of the HAVING clause must identify a grouping column, or be used in set functions, or be outer references.
Most commonly, HAVING is used together with GROUP BY, in which case the search conditions relate either values in grouping columns or results of set functions to expressions.
If the HAVING clause is used without a GROUP BY clause, all rows in the result table are treated as a single group. In this case, the HAVING clause must refer to a set function (since there are no grouping columns).
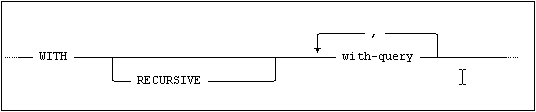
A WITH clause provides a way to write named queries for use in a larger query. (Such a named query is also known as a cte, common table expression.)
The WITH clause has the following syntax:
The WITH clause contains one or more named select expressions that can be referenced multiple times in the query following the WITH clause. These select expressions can be seen as a temporary views, which are only defined within a query.
WITH clauses can be nested, i.e. a SELECT expression in a with element or a subquery may also contain with clauses. These with elements are not in scope outside of the context in which they are defined.
If the column names are omitted from a with element, the names from the outermost select list will be used.
Example
WITH display_order (display_order, format) AS
(
SELECT CASE display_order
WHEN 10 THEN 'FIRST'
WHEN 20 THEN 'SECOND'
WHEN 30 THEN 'THIRD'
WHEN 40 THEN 'FOURTH'
ELSE 'UNKNOWN'
END,
format
FROM formats
)
SELECT display_order,
format
FROM display_order
WHERE display_order IN ('SECOND', 'THIRD')
The usage of a WITH clause in the previous example can also be expressed by using a derived table and thus this use of WITH does not add any new functionality. However, a query written in this way can be found easier to construct and to read.
Example
WITH annualsalary AS
(
select staff_id, salyear, sum(payment) as salary
from (select staff_id, payment, extract(year from paymentdate) as salyear
from payments) p
group by staff_id, salyear
)
select emp.name as emp_name, esal.salary as emp_sal,
mngr.name as mngr_name, msal.salary as mngr_sal, esal.salyear
from staff emp
join annualsalary esal
on emp.id = esal.staff_id
left join staff mngr
on emp.manager_id = mngr.id
left join annualsalary msal
on mngr.id = msal.staff_id and esal.salyear = msal.salyear
The WITH clause above specifies the named query annualsalary, which is joined twice in the main query. Writing this query only once makes coding more efficient, and future changes will be simpler and safer.
Recursive Queries
A WITH clause query that refers to its own output is recursive. Recursive queries make it possible to express things otherwise not possible using a single SQL statement.
The general form of a recursive WITH query is always a non-recursive term, the anchor member, with a UNION (or UNION ALL), followed by a query, the recursive member, which contains a reference to the with element (anchor member) itself.
A simple example is to generate the integer values from 1 to 50:
WITH RECURSIVE integer_list(n) as
(
VALUES (1) -- anchor member
UNION ALL
SELECT n + 1
FROM integer_list -- recursive member
WHERE n < 50 -- terminating condition
)
select n
from integer_list
Recursive queries are typically used to deal with hierarchical or tree-structured data, e.g. solving the bill of materials problem (see https://en.wikipedia.org/wiki/Bill_of_materials.)
Another example is to show categories with sub-categories and where a sub-category may have sub-categories by its own and so on indefinitely:
with recursive tree (name, parent, level) as
(
select name, parent, 0
from categories
where parent is null
union all
select categories.name, categories.parent, level + 1
from tree
join categories on tree.name = categories.parent
)
select *
from tree
order by level
When working with recursive queries it is important to be sure that the recursive part of the query has a terminating condition as the query otherwise will not terminate.
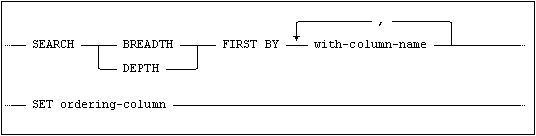
BREADTH FIRST and DEPTH FIRST
When a SEARCH clause is specified the ordering-column is added to the result set of the WITH clause. It is set to a sequence of values that reflects BREADTH or DEPTH first traversal of the recursive query. The traversal is done according the search columns specified for each level in the tree. Even though search order is specified the rows may be returned in any order, so if you want the rows actually returned in this order you must add an ORDER BY ordering-column to your query.
A SEARCH clause may only be specified with a recursive WITH clause.
Example
Return combined values, using the different traversal methods.
create table t (c varchar(1));
insert into t values ('A');
insert into t values ('B');
insert into t values ('C');
SQL>WITH tr (grp, c) AS
SQL&(
SQL& SELECT cast(c as varchar(20)), c
SQL& FROM t
SQL&
SQL& UNION ALL
SQL&
SQL& SELECT c.grp || ', ' || t.c, t.c
SQL& FROM t
SQL& INNER JOIN tr c
SQL& ON c.c < t.c
SQL&) SEARCH BREADTH FIRST BY grp SET oc
SQL&SELECT grp FROM tr;
grp
==========================
A
B
C
A, B
A, C
B, C
A, B, C
7 rows found
SQL>
SQL>WITH tr (grp, c) AS
SQL&(
SQL& SELECT cast(c as varchar(20)), c
SQL& FROM t
SQL&
SQL& UNION ALL
SQL&
SQL& SELECT c.grp || ', ' || t.c, t.c
SQL& FROM t
SQL& INNER JOIN tr c
SQL& ON c.c < t.c
SQL&) SEARCH DEPTH FIRST BY grp SET oc
SQL&SELECT grp FROM tr;
grp
==========================
A
A, B
A, B, C
A, C
B
B, C
C
7 rows found
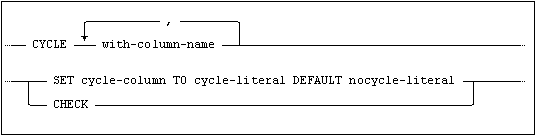
Cycle detection
A CYCLE clause can be specified when the traversal may contain cycles. If there is no cycle checking a result can return an infinite number of rows. If a cycle-column is specified, it is added to the result set of the WITH clause. When a cycle is detected, the row with the cycle is returned and the cycle-column is set to the cycle-literal. It will then continue with the next row in the tree without following the cycle. If the cycle-check is specified an error code (-12288) will be returned when a cycle is detected and execution stops.
A CYCLE clause may only be specified with a recursive WITH clause.
VALUES computes a row value specified by value expressions.
The VALUES clause has the following syntax:

To get multiple row values several VALUES clauses can be unioned together. It is most commonly used to generate a "constant table" within a larger command, but it can be used on its own.
Example
select *
from
(
values('A', 1)
union
values('B', 2)
) dt(x, y)
will return two rows with the columns named x and y.
If several SELECT statements are connected by UNION (or UNION DISTINCT), the result is derived by first merging all result tables specified by the separate SELECT statements, and then eliminating duplicate rows from the merged set. All columns in the result table are significant for the purpose of eliminating duplicates.
The UNION ALL operator on the other hand retains all duplicates. The operator can be viewed as a way to concatenate several queries.
The rules described below apply to both UNION and UNION ALL.
All separate result tables from SELECT statements connected by UNION must have the same number of columns and the data types of columns to be merged must be compatible.
The columns in the result table are named in accordance with the columns in the first SELECT statement of the UNION construction.
Separate SELECT statements may be enclosed in parentheses if desired. This does not affect the result of a UNION operation.
The names in the first select specification are used in UNION constructions.
See Result Data Types for a description of how the data type of the UNION result is determined.
If several SELECT statements are connected by EXCEPT (or EXCEPT DISTINCT), the result is derived by taking the distinct rows of the first query and return the rows that do not appear in second result query. All columns in the result table are significant for the purpose of eliminating duplicates.
The EXCEPT ALL operator on the other hand retains all duplicates.
The rules described below apply to both EXCEPT and EXCEPT ALL.
All separate result tables from SELECT statements connected by EXCEPT must have the same number of columns and the data types of columns to be merged must be compatible.
The columns in the result table are named in accordance with the columns in the first SELECT statement of the EXCEPT construction.
Separate SELECT statements may be enclosed in parentheses if desired. This does not affect the result of a EXCEPT operation.
The names in the first select specification are used in EXCEPT constructions.
See Result Data Types for a description of how the data type of the EXCEPT result is determined.
If several SELECT statements are connected by INTERSECT (or INTERSECT DISTINCT), the result is derived by taking the results of two queries and return only rows that appear in both result sets, and then eliminating duplicate rows from the merged set. All columns in the result table are significant for the purpose of eliminating duplicates.
The INTERSECT ALL operator on the other hand retains all duplicates.
The rules described below apply to both INTERSECT and INTERSECT ALL.
All separate result tables from SELECT statements connected by INTERSECT must have the same number of columns and the data types of columns to be merged must be compatible.
The columns in the result table are named in accordance with the columns in the first SELECT statement of the INTERSECT construction.
Separate SELECT statements may be enclosed in parentheses if desired. This does not affect the result of a INTERSECT operation.
The names in the first select specification are used in INTERSECT constructions.
See Result Data Types for a description of how the data type of the INTERSECT result is determined.
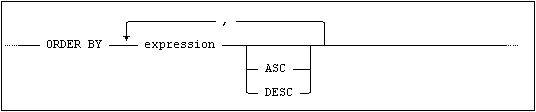
The result table may be ordered according to an order-by-clause.
The ORDER BY clause has the following syntax:
Every expression in the order-by-clause must contain a reference to a column in a table specified in the FROM clause.
Column labels, created with SELECT AS, may not be part of a complex ORDER BY expression, (i.e. if column label is used, the expression must contain nothing but the column label).
The ORDER BY expressions must not include set functions (i.e. MAX, MIN, AVG, SUM and COUNT), subqueries or NEXT VALUE FOR sequence.
If DISTINCT, GROUP BY, UNION, EXCEPT or INTERSECT is specified, only columns from the result set may be specified as ORDER BY expressions.
The default collation for sorting data is the collation defined for the column being sorted. If you include a COLLATE clause, you can override the default collation by explicitly specifying a different collation. For more information, see the Mimer SQL User's Manual, Collations.
Ascending/Descending
For each column in the order-by-clause, the sort order may be specified as ASC (ascending) – the default, or DESC (descending). If more than one column is specified, the result table is ordered first by values in the first specified column, then by values in the second, and so on.
The result-offset-clause is used to limit the result set by removing a specified number of rows from its beginning.
The result-offset-clause clause has the following syntax:
If a statement contains both an order-by-clause and a result-offset-clause, the result set is first sorted according to the ORDER BY clause, and then the number of rows specified in the result-offset-clause are removed.
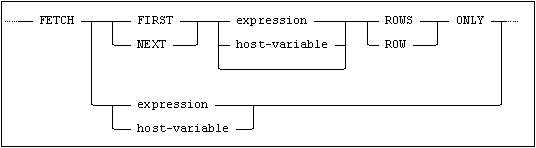
The fetch-first-clause is used to limit the result set by specifying the number of rows to be returned.
The fetch-first-clause has the following syntax:
If a statement contains both an order-by-clause and a fetch-first-clause, the result set is first sorted according to the order-by-clause and then limited to the number of rows specified in the fetch-first-clause.
If both a result-offset-clause and a fetch-first-clause are specified, the result-offset-clause is applied first, then the fetch-first-clause.
SELECT access is required on all tables and views specified in a FROM clause.
If the SELECT statement is used without the ORDER BY clause, the sort order is undefined. This means that the sort order may change if new indexes are created, indexes are dropped, new statistics are gathered or if a new version of the SQL optimizer is installed.
This section summarizes standard compliance for select-specifications.
|
Standard |
Compliance |
Comments |
|---|---|---|
|
SQL-2016 |
Core |
Fully compliant. |
|
SQL-2016 |
Features outside core |
Feature F302, “INTERSECT table operator”. Feature F304, “EXCEPT ALL table operator”. Feature T551, “Optional keywords for default syntax” support for the keyword DISTINCT. Feature F591, “Derived tables”. Feature F661, “Simple tables” Feature F851, “<order by clause> in subqueries”. Feature F855, “Nested <order by clause> in <query expression>”. Feature F856,” Nested <fetch first clause> in <query expression>”. Feature F857, “Top-level <fetch first clause> in <query expression>” Feature F858, “<fetch first clause> in subqueries”. Feature F860, “dynamic <fetch first row count> in <fetch first clause>”. Feature F861, “Top-level <result offset clause> in <query expression>”. Feature F862, “<result offset clause> in subqueries”. Feature F863, “Nested <result offset clause> in <query expression>”. Feature F865, “dynamic <offset row count> in <result offset clause>”. Feature T121, “WITH (excluding RECURSIVE ) in query expression” Feature T122, “WITH (excluding RECURSIVE ) in subquery” Feature T131, “Recursive query” Feature T132, “Recursive query in subquery” Feature T551, “Optional key words for default syntax”. |
|
|
Mimer SQL Extension |
Support for host variable in <fetch first clause> and <result offset clause> is a Mimer SQL extension. <cycle literal> and <nocycle literal> must be data type CHAR(1) according to the SQL standard. Mimer SQL requires both literals to be of compatible types and can be boolean, numeric, or character. The option to perform CYCLE CHECK with an error code is a Mimer SQL extension. |