Creates a secondary index on one or more columns of a table.
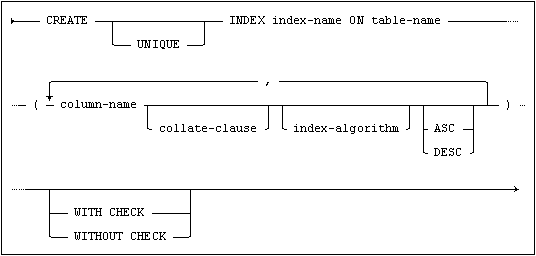
where index-algorithm is:

Usage
Embedded, Interactive, Module, ODBC, JDBC.
Description
A secondary index is created on the column(s) in the table as specified. The index is stored in the data dictionary under the given name. The secondary index is used internally by the optimizer to improve the efficiency of a search.
The UNIQUE Option
If UNIQUE is specified each index value (i.e. the value of all index columns together) is only allowed once. In this context two null values are considered equal.
Index-name
If index-name is specified in its unqualified form, the index will be created in the schema which has the same name as the current ident.
If index-name is specified in its fully qualified form (i.e. schema-name.index-name) the index will be created in the named schema (in this case, the current ident must be the creator of the specified schema).
The COLLATE Clause
If the collate-clause is specified, the index will be ordered according to the collation specified.
Otherwise, the collation is inherited from the column-definition.
For more information, see the Mimer SQL User's Manual, Collations.
Index-algorithm
If the WORD_SEARCH index algorithm is specified, the index will be optimized for “begins word” searches and “match word” searches. (See BUILTIN.BEGINS_WORD and BUILTIN.MATCH_WORD.)
Ascending/Descending
ASC and DESC indicate the sort order of the column within the index. If neither is specified, then ASC is implicit. This makes an index appropriate for queries with a matching ORDER BY specification.
WITHOUT CHECK
The WITH CHECK and WITHOUT CHECK clauses are used to control whether existing table data should be verified for uniqueness or not when a unique index is created. WITH CHECK is the default behavior.
If WITH CHECK is used but the existing data in the table is not unique, the CREATE INDEX statement will fail.
If WITHOUT CHECK is used and the existing data in the table is not unique, the CREATE INDEX statement will still succeed. (After the index has been created, all new data will be verified for uniqueness.)
Note:For a database with the AUTOUPGRADE attribute enabled, the WITHOUT CHECK option must be used when creating a unique index.
See ALTER DATABASE for more information about AUTOUPGRADE.
Restrictions
An index can not have the same name as a table, view, synonym, constraint or other index in the same schema.
An index must belong to the same schema as the table on which it is created.
Indexes may only be created on base tables, not on views.
UNIQUE indexes may only be created on tables in databanks defined with the LOG or TRANSACTION transaction option.
The WITH/WITHOUT CHECK clause is only valid for unique indexes.
Large object columns (clob, nclob and blob) are not allowed in indexes.
The WORD_SEARCH index algorithm can only be specified for character and national character columns.
The WORD_SEARCH index algorithm may not be specified for unique indexes.
Notes
Each column name must identify an existing column of the table. The same column may not be identified more than once.
Mimer SQL can make use of an index in both the forward and backward direction. It is therefore immaterial whether ASC or DESC is specified if all the index columns have the same sorting direction.
Secondary indexes are automatically maintained and are invisible to the user. The index is used automatically when it provides better efficiency.
Table columns that are in the primary key, a unique key or used in a foreign key reference are automatically indexed (in the order in which they are defined in the key). Therefore, explicitly creating an index on these columns will not improve performance at all.
Consider a table with columns A, B and C of which A and B form the primary key, in that order. An index is automatically created for the column combination (A, B). Therefore, there is no advantage in explicitly creating an index on column A or on the column combination (A, B). Secondary indexes may, however, be advantageous on column B alone or on combinations such as (B, A) or (A, C).
Also, if there is an index on the columns (C, A) there’s no need for an index on C alone.
Examples
CREATE INDEX cst_date_of_birth ON customers (date_of_birth);
CREATE INDEX cst_ename_french ON customers (ename COLLATE french_1);
CREATE INDEX tracks_track_ws ON tracks (track for word_search);
For more information, see Mimer SQL User's Manual, Creating Secondary Indexes.
Standard Compliance
|
Standard |
Compliance |
Comments |
|---|---|---|
|
|
Mimer SQL extension |
The CREATE INDEX statement is a Mimer SQL extension. |