This chapter describes the SQL statements for creating and managing the database structure. Examples are based on the database listed in The Example Environment.
In addition, Mimer BSQL provides specific commands for listing and describing database objects, see Mimer BSQL.
SQL includes statements for creating and modifying the database structure:
•create idents, schemas, databanks, shadows, domains, sequences, tables, triggers, functions, procedures, modules, views, indexes and synonyms
•saving documentary comments on objects
•altering the definition of idents, databanks, shadows and tables
•dropping objects from the database.
All information describing the database structure is stored in the data dictionary.
Before the database is defined, it is extremely important to design the database model. Well-functioning and efficient databases cannot be created without a model as the foundation.
Without careful design, much of the flexibility and efficiency inherent in a relational database structure may be lost.
Idents are authorized users of the system or groups of users defined for easier ident management, see Idents.
A schema defines a local environment within which private database objects can be created. The ident creating the schema has the right to create objects in it and to drop objects from it.
The statement for creating idents has the general form:
CREATE IDENT username
AS ident-type
[USING 'password']
[WITH | WITHOUT SCHEMA];
The case of letters is insignificant for an ident name and it must be composed of a unique sequence of case-less characters (e.g. the idents ABC and aBc cannot both exist in the database because they are identical when case is ignored).
Passwords are composed of case-significant characters and must be entered exactly as they are defined.
Passwords are optional for USER idents. A USER ident with an OS_USER login may connect to Mimer SQL without providing a password. Passwords are required for PROGRAM idents. Passwords are not used for GROUP idents.
When a USER or PROGRAM ident is created, a schema with the same name can also be created automatically and the created ident becomes the creator of the schema. This happens by default unless WITHOUT SCHEMA is specified in the CREATE IDENT statement. For idents who are not supposed to create database objects, it’s good practice to specify WITHOUT SCHEMA.
All private database objects created by an ident must belong to a schema which, by default, is the schema with the same name as the ident. When any private database object is created, its name can be specified in the fully qualified form that explicitly identifies which schema the object is to belong to. An ident may create objects in schemas ‘owned’ by it (i.e. the schema created automatically when the ident was created and any schemas explicitly created by the ident).
An ident with IDENT or SCHEMA privilege can create additional schemas by using the CREATE SCHEMA statement. The objects belonging to the schema can be defined in the CREATE SCHEMA statement and created at the same time as the schema, refer to the Mimer SQL Reference Manual, CREATE SCHEMA for details.
Creating Idents and Schemas, Examples
Create a user ident MIMER_ADM with the password 'adm':
Note:Schema MIMER_ADM will also be automatically created.
CREATE IDENT mimer_adm AS USER USING 'adm';
Create a program ident AUDIT with the password 'economy' without creating a schema:
CREATE IDENT audit AS PROGRAM USING 'economy' WITHOUT SCHEMA;
Create a group ident:
CREATE IDENT mimer_admin_group AS GROUP;
Create a schema called MIMER_STORE:
CREATE SCHEMA mimer_store;
Create table CURRENCIES in the schema MIMER_STORE:
CREATE TABLE mimer_store.currencies (
code CHARACTER(3) PRIMARY KEY,
...
Create schema called MIMER_STORE_NEW that contains sequence Z:
CREATE SCHEMA mimer_store_new
CREATE SEQUENCE z;
A databank is the file where tables and sequences are stored. A Mimer SQL database may contain any number of databanks.
The statement for creating a databank has the general form:
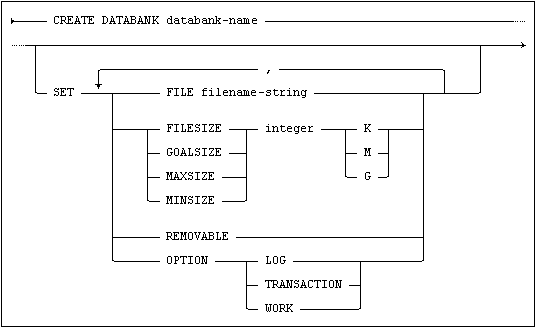
•The CREATE DATABANK clause defines the databank name.
•The optional FILESIZE clause is used to specify the initial file size (it will be dynamically extended as space is required). If the clause is omitted, an initial file size of 2000 kB is assumed. The optional GOALSIZE, MAXSIZE and MINSIZE attributes are used to manage the file size, see Mimer SQL Reference Manual, CREATE DATABANK.
•The optional FILE clause defines the file where the databank is to be stored (the form of the filename follows the operating system file naming conventions). If the FILE clause is omitted, the file is created in the database home directory with the same name as databank-name.
•The optional OPTION clause defines the transaction handling and logging option, see Logging Transactions. If the OPTION clause is omitted, the TRANSACTION option is assumed.
Examples
Create a databank called mimer_blobs with the default parameters:
Note:The default parameters are with TRANSACTION option and size 2000 kB. This databank is created in a file called “mimer_blobs.dbf”
CREATE DATABANK mimer_blobs;
Create the mimer_store databank with LOG option, allocate 1200 MB for it, and store it in a file called 'mstore.dbf':
CREATE DATABANK mimer_store SET FILESIZE 1200 M,
FILE 'mstore.dbf',
OPTION LOG;
At this point, the databank is empty.
After the physical file space has been allocated on a disk for the databank, (CREATE DATABANK), you can create the tables. The basic CREATE TABLE statement defines the columns in the table, the primary key, any unique or foreign keys and which databank the table is to be stored in. Table names and column names may be up to 128 characters long.
As a convention, we have defined primary key column(s) as the first column(s) in the example definitions. However, this is not a necessity; primary key columns may be defined anywhere in the column list. Primary keys are always NOT NULL, so there is no need to explicitly state that in the table definition.
Create Table Statement
Example
Create the table CURRENCIES with three columns in the MIMER_STORE schema.
The table shall be as follows:
•Name the first column CODE, make it of the CHARACTER data type with a maximum of three characters.
•Name the second column CURRENCY, make it of the CHARACTER data type with a maximum of 32 characters and don't allow null values to be stored in the column.
•Name the third column EXCHANGE_RATE and make it of the data type DECIMAL with a total of twelve digits, four of which can be decimal values.
•Declare the CODE column as the primary key and place this table in the MIMER_STORE databank.
CREATE TABLE mimer_store.currencies (
code CHARACTER(3),
currency CHARACTER(32) NOT NULL,
exchange_rate DECIMAL(12, 4),
PRIMARY KEY(code))
IN mimer_store;
The CREATE TABLE clause defines the name of the table followed by a column list, which includes the names of the columns in the table, their data type, if they should allow the null indicator and the primary key declaration. Each item in the column-list is separated from the next by a comma, and the entire list is enclosed in parentheses.
A table definition may only include one primary key clause. The primary key can be made up of more than one column.
The IN clause states which databank the table is to be stored in. This clause may be omitted; if the IN clause is not specified, Mimer SQL will select the ‘best’ databank in which to place the table.
The empty table now exists in the databank. Data is inserted into the table with the INSERT statement, see Inserting Data.
The preceding example shows the simplest form of column list. The following variants may also be used:
•columns belonging to domains
•columns defined with collations
•default values (overriding any domain default for the column)
•columns not belonging to the primary key defined as NOT NULL
•unique constraints (in addition to the primary key)
•foreign key constraints
•check constraints.
The ITEMS Table
The ITEMS table in the example database is defined with many of the options that can be used in creating tables. See the Mimer SQL Reference Manual, CREATE TABLE, for more information.
The ITEMS table is defined as follows:
CREATE TABLE items (
item_id internal_id DEFAULT NEXT VALUE FOR item_id_seq,
product_id internal_id CONSTRAINT itm_product_id_not_null NOT NULL,
format_id format_id CONSTRAINT itm_format_id_not_null NOT NULL,
release_date DATE,
status CHAR DEFAULT 'A' CONSTRAINT itm_status_not_null NOT NULL
CONSTRAINT itm_status_valid
-- Available, Deleted
CHECK (status IN ('A', 'X')),
price euros CONSTRAINT itm_price_valid
CHECK (price >= 4.99 AND price <= 366.00),
stock SMALLINT CONSTRAINT itm_stock_not_null NOT NULL
CONSTRAINT itm_stock_valid CHECK (stock >= 0),
reorder_level SMALLINT CONSTRAINT itm_reorder_level_not_null NOT NULL,
ean_code BIGINT CONSTRAINT itm_ean_code_not_null NOT NULL,
producer_id internal_id DEFAULT NULL,
image_id internal_id DEFAULT NULL,
CONSTRAINT itm_primary_key PRIMARY KEY(item_id),
CONSTRAINT itm_ean_code_exists UNIQUE (ean_code),
CONSTRAINT itm_products
FOREIGN KEY (product_id) REFERENCES products(product_id)
ON DELETE CASCADE ON UPDATE NO ACTION,
CONSTRAINT itm_formats FOREIGN KEY (format_id) REFERENCES formats
ON DELETE CASCADE ON UPDATE NO ACTION,
CONSTRAINT itm_producers FOREIGN KEY (producer_id) REFERENCES producers
ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT itm_images FOREIGN KEY (image_id) REFERENCES images
ON DELETE SET DEFAULT ON UPDATE NO ACTION) IN mimer_store;
The ordering of column specifications, key clauses and check conditions is not fixed. If desired, the key and check clauses can be written in association with the respective column specifications.
Each constraint is given a name which allows it to be dropped and modified separately. The constraint name is also useful if a program wants to find out which constraint failed for a particular statement.
Columns should in general be defined as NOT NULL unless there is a specific reason for using the null value in the column (e.g. is the value not known, not applicable or given some other meaning). The presence of null values can often complicate the formulation of queries, see Handling Null Values.
Note:Take particular care to exclude null from numerical columns which are to be used for mathematical operations.
Domains are used for many columns to help in maintaining database integrity. By using the same domain for columns in different tables, the column data types are guaranteed to be consistent. See Creating Domains for more information
The purpose of a primary key is to define a key value that uniquely identifies each table row, therefore the primary key value for each row in the table must be unique.
The primary key constraint can consist of more than one column in the table. The choice of columns to use as the primary key is determined by the relational model for the database, which is outside the scope of this manual.
A unique constraint can be defined for one or more columns in the table. The list of columns that make up the unique constraint are specified in the UNIQUE clause for the table when it is created.
Specifying UNIQUE in the definition of a column in the table is equivalent to supplying a list of one column in the UNIQUE clause for the table and effectively specifies a one-column unique constraint.
Foreign Keys – Referential Constraints
Use foreign keys to maintain integrity between the contents of related tables.
The effect of a foreign key is to constrain table data in a way that only allows a row in the referencing table which has a foreign key value that matches the specified key value of a row in the referenced table.
A referencing table row which has a foreign key value with the null value in at least one of the columns will always fulfil the referential constraint and therefore be acceptable as a row in the referencing table.
A foreign key constraint can be defined with a foreign key clause at CREATE TABLE or added afterwards using ALTER TABLE.
The table referenced in a foreign key clause can be an existing table or a table defined in the current statement (allowing self-referencing foreign keys at CREATE TABLE and circular foreign keys at CREATE SCHEMA).
The number of columns listed as FOREIGN KEY must be the same as the number of columns in the primary key or unique key of the REFERENCES table. See the CREATE TABLE syntax in the Mimer SQL Reference Manual for details.
The nth FOREIGN KEY column corresponds to the nth column in the primary key of the REFERENCES table, and the data types and lengths of corresponding columns must be identical.
A table definition may contain several FOREIGN KEY references. Each column in the table may be used in many FOREIGN KEY clauses, but only once per FOREIGN KEY clause.
Note:A table containing a foreign key reference or referenced in a foreign key must be stored in a databank with either the TRANSACTION or LOG option.
Foreign Key Example
The ITEMS table has four foreign key references:
CREATE TABLE items (
item_id internal_id DEFAULT NEXT VALUE FOR item_id_seq,
product_id internal_id CONSTRAINT itm_product_id_not_null NOT NULL,
format_id format_id CONSTRAINT itm_format_id_not_null NOT NULL,
.
.
producer_id internal_id DEFAULT NULL,
image_id internal_id DEFAULT NULL,
.
.
CONSTRAINT itm_products
FOREIGN KEY (product_id) REFERENCES products(product_id)
ON DELETE CASCADE ON UPDATE NO ACTION,
CONSTRAINT itm_formats FOREIGN KEY (format_id) REFERENCES formats
ON DELETE CASCADE ON UPDATE NO ACTION,
CONSTRAINT itm_producers FOREIGN KEY (producer_id) REFERENCES producers
ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT itm_images FOREIGN KEY (image_id) REFERENCES images
ON DELETE SET DEFAULT ON UPDATE NO ACTION)
.
.
These maintain referential integrity as follows:
•FOREIGN KEY (product_id) REFERENCES products(product_id)
Data that is not present in the PRODUCT_ID column of the PRODUCTS table will not be accepted in the PRODUCT_ID column in the ITEMS table.
•FOREIGN KEY (format_id) REFERENCES formats
Data that is not present in the FORMAT_ID column of the FORMATS table will not be accepted in the FORMAT_ID column in the ITEMS table.
•FOREIGN KEY (producer_id) REFERENCES producers
Data that is not present in the PRODUCER_ID column of the PRODUCERS table will not be accepted in the PRODUCER_ID column in the ITEMS table.
•FOREIGN KEY (image_id) REFERENCES images
Data that is not present in the IMAGE_ID column of the IMAGES table will not be accepted in the IMAGE_ID column in the ITEMS table.
Specifying ON DELETE
When defining a foreign key constraint it is possible to specify in an ON DELETE clause what action that shall take place if the corresponding record in the referenced table is deleted.
The possible actions are
•NO ACTION
Any attempt to delete a key value that is referenced by a foreign key will fail. This action is the default behavior.
•SET NULL
If a key value in the referenced table is deleted the corresponding values in the foreign key table is set to the null value
•SET DEFAULT
If a key value in the referenced table is deleted the corresponding values in the foreign key table is set to the default value for the columns in the foreign key
•CASCADE
If a key value in the referenced table is deleted the corresponding records in the foreign key table are also deleted
Check constraints in table definitions are used to make sure that data in a column (or row) in the table fits certain conditions.
CREATE TABLE items (
.
.
status CHAR (1) DEFAULT 'A' CONSTRAINT itm_status_not_null NOT NULL
CONSTRAINT itm_status_valid
-- Available, Deleted
CHECK (status IN ('A', 'X')),
price euros CONSTRAINT itm_price_valid
CHECK (price >= 4.99 AND price <= 366.00),
stock SMALLINT CONSTRAINT itm_stock_not_null NOT NULL
CONSTRAINT itm_stock_valid CHECK (stock >= 0),
.
.
The check clause defined on the PRICE column extends any limitations imposed by the EUROS domain definition. The extension applies only to this table, and does not affect other columns in the database that belong to the EUROS domain:
CREATE DOMAIN euros AS NUMERIC(7, 2)
CONSTRAINT euros_value_not_null CHECK (VALUE IS NOT NULL)
CONSTRAINT euros_value_valid CHECK (VALUE > 0.0);
The constraint names, e.g. ITM_PRICE_VALID in the ITEMS table, can be used in an ALTER TABLE statement to drop the check constraint. All constraints, primary key, unique, not null and foreign key constraints can be named in this manner.
If no constraint name is given, a unique name is generated by the system. This name can be seen by using the describe statement in BSQL. See Mimer BSQL.
Ensure that either the customer's e-mail address and password are both defined or that neither is defined:
CREATE TABLE customers (
.
.
email VARCHAR(128) COLLATE english CHECK (char_length(trim(email)) > 0),
password VARCHAR(18) CHECK (char_length(trim(password)) > 0),
.
.
CONSTRAINT cst_email_password_cross_check
CHECK ( (email IS NULL AND password IS NULL)
OR (email IS NOT NULL AND password IS NOT NULL))
.
.
A sequence can be used to provide the default value for a table column or a domain, etc.
A sequence returns a series of integer values which is defined by a start value, a minimum value, a maximum value, an increment value, and whether the sequence is to be cyclic or not.
A sequence that has been initialized has a current value, which is returned from the function CURRENT VALUE. The function NEXT VALUE is used to initialize a sequence and to subsequently advance the current value of the sequence through its defined series of values.
A no cycle sequence will never return the same value twice.
Examples of Sequences
Create a sequence that returns odd numbers:
CREATE SEQUENCE seq_1 START WITH 1 INCREMENT BY 2 IN userdb;
Create a sequence that defines the following series of values: 1, 4, 7, 10:
CREATE SEQUENCE seq_2
START WITH 1
INCREMENT 3
MAXVALUE 10
NO CYCLE
IN DATABANK userdb;
Create a table that uses a sequence to set a column default value:
CREATE TABLE objinfo (objid INTEGER DEFAULT NEXT VALUE FOR obj_seq,
description NCHAR VARYING(1000));
Domains are used as data types in column definitions when creating tables in order to:
•assist in keeping the database consistent
•validate the data (particular values or data type) accepted in the columns
•define default values for columns.
Create Domain Statement
The statement for creating domains has the general form:
CREATE DOMAIN domain-name
AS data-type
[DEFAULT default-value]
[{[CONSTRAINT constraint_name] CHECK (check-condition)}...];
•The CREATE DOMAIN clause defines the domain name.
•The AS clause defines the domain data type.
•The DEFAULT clause defines a default value for the domain
•The CHECK clause defines the domain limits.
It is a good practice for maintaining the integrity of the database to define domains for as many columns as possible.
The default clause defines values that are inserted into the column when an explicit value is not specified or the keyword DEFAULT is used in an INSERT statement.
Examples
Define the default value '000000' for the domain SIXDIGITS:
CREATE DOMAIN sixdigits AS CHAR(6) DEFAULT '000000';
Define the session user's name as the default value for the domain USER_NAME:
CREATE DOMAIN user_name AS NVARCHAR(128) COLLATE SQL_IDENTIFIER
DEFAULT SESSION_USER;
Domains defining default values can also include check clauses. You could define the SOUNDEX domain as:
CREATE DOMAIN sixdigits AS CHAR(6) DEFAULT '000000'
CHECK (VALUE IS NOT NULL)
CHECK (CHAR_LENGTH(TRIM(VALUE)) = 6
AND VALUE BETWEEN '000000' AND '999999');
This means that the null indicator will not be accepted into columns belonging to this domain and that the value must be a character string of six digits.
If the default value is defined as being outside the check constraint this ensures that an explicit value must always be inserted into the column.
Specification of a CHECK clause means that only values for which the specified search condition evaluates to true may be assigned to a column belonging to the domain.
The search condition, see the Mimer SQL Reference Manual, Search Conditions, in the CHECK clause may only reference the domain values (by using the keyword VALUE), constants, or the keywords CURRENT_USER, SESSION_USER and NULL.
Creating Functions, Procedures, Triggers and Modules
Functions and procedures are SQL routines that are stored in the data dictionary.
A module is a collection of SQL routines.
Triggers contain the same constructs as routines but are created on tables or views (depending on the type of trigger) and execute before, after or instead of a specified data manipulation operation.
Refer to the Mimer SQL Reference Manual, SQL Statements for the syntax definitions for CREATE FUNCTION, CREATE MODULE, CREATE PROCEDURE and CREATE TRIGGER, and the Mimer SQL Programmer's Manual, Mimer SQL Stored Procedures for a general discussion of the stored procedure functionality in Mimer SQL.
Creating Functions and Procedures
The CREATE FUNCTION statement is used to create a function that does not belong to a module and the CREATE PROCEDURE statement is used to create a procedure that does not belong to a module.
The format of the routine definition is the same in the CREATE FUNCTION and CREATE PROCEDURE statements as it is in a function or procedure declaration in a module.
A module is created by using the CREATE MODULE statement and all the routines that belong to the module are defined by declaring them within the CREATE MODULE statement.
Routines cannot be added to a module after the module has been created and a routine cannot be removed from the module it belongs to. The routines in a module behave in all respects as single objects (e.g. EXECUTE privilege is applied on individual routines in a module, not the module). If the module is dropped, all the routines in it are dropped.
The CREATE TRIGGER statement is used to define a trigger on a table or view.
Note:The examples that follow show the ‘@’ character which is used in Mimer BSQL to delimit SQL statements whose syntax involves use of the normal end-of-statement character ‘;’ before the actual end of the statement.
This is the case for many of the SQL/PSM statements. See Mimer BSQL for details.
The ‘@’ character may be used to delimit any statement. This is useful when dealing with large statement as the error reporting facility in BSQL shows more information in such cases.
Create a standalone function FUNC_1 with one input parameter of data type VARCHAR(20) that returns a value of data type INTEGER:
@
CREATE FUNCTION func_1(p1 VARCHAR(20)) RETURNS INTEGER
BEGIN
...
END
@
Create a standalone procedure PROC_1 with one input parameter of data type INTEGER and one output parameter of VARCHAR(20):
@
CREATE PROCEDURE proc_1(IN p_value1 INTEGER,
OUT p_value2 VARCHAR(20))
BEGIN
...
END
@
Create a module M1 containing 2 procedures, PROC_1 (with no parameters), PROC_2 (one input parameter, X, of data type INTEGER) and 1 function, FUNC_1 (with no parameters, returning an INTEGER):
@
CREATE MODULE m1
DECLARE PROCEDURE proc_1()
READS SQL DATA
BEGIN
...
END;
DECLARE PROCEDURE proc_2(IN p_x INTEGER)
MODIFIES SQL DATA
BEGIN
...
END;
DECLARE FUNCTION func_1() RETURNS INTEGER
READS SQL DATA
BEGIN
...
END;
END MODULE
@
Create a trigger that will execute after INSERT operations on table PRODUCTS:
@
CREATE TRIGGER products_after_insert AFTER INSERT ON products
REFERENCING NEW TABLE AS pdt
FOR EACH STATEMENT
BEGIN ATOMIC
...
END
@
Note:It is recommended that all functions, procedures and triggers are created by executing a command file so that they may be easily re-created in the event of being unintentionally dropped because of CASCADE effects following a drop.
The effect of CASCADE can be quite far-reaching where routines and modules are concerned, see the Mimer SQL Programmer’s Manual.
The use of a command file also facilitates module re-definition by dropping an existing module, altering the CREATE MODULE statement in the command file and creating the new, redefined module.
A view is a logical subset of one or more base tables or views where columns are chosen by naming them and rows are chosen through specified conditions relating to column values.
Views are created, for example, so that users who need not see all the data in a single table are shown only the parts of the table that interest them (restriction views). Views can also be created as a combination of a number of columns from several different tables (join views).
Operations on views are actually performed on the underlying base tables. Certain view definitions do not allow data to be changed in the view (read-only views). See Updatable Views for further details.
View names can be up to 128 characters long. Views are defined in terms of a SELECT statement; the result of the SELECT statement forms the contents of the view. There are no restrictions on which select statements that can be used in a view definition.
Creating a View
Create a restriction view on the CUSTOMERS table called CUSTOMER_DETAILS containing limited information:
CREATE VIEW customer_details
AS SELECT surname, forename, address_1, address_2, town, postcode,
title, date_of_birth, country_code, customer_id
FROM customers;
In this case the columns in the view are named after the columns listed in the SELECT clause, since the view definition does not include a list of column names.
Create a join view, including an outer join:
CREATE VIEW product_details
AS SELECT product, COALESCE(producer, ' ') AS producer, format,
price, stock, reorder_level, release_date, ean_code,
status, product_search, item_id, category_id, product_id,
display_order, image_id
FROM products JOIN items ON products.product_id = items.product_id
JOIN formats ON items.format_id = formats.format_id
LEFT OUTER JOIN producers ON items.producer_id = producers.producer_id;
The check option can be used in updatable view definitions to limit the data that can be inserted into the view. If a check option is specified, data which does not fulfill the definition of the view cannot be inserted into the view.
CREATE VIEW swedish_customers
AS SELECT *
FROM customer_details
WHERE country_code = 'SE'
WITH CHECK OPTION;
The check option in the view definition (WITH CHECK OPTION) means that the COUNTRY_CODE column must be set to SE if new rows are inserted into the view or rows are updated using the view.
If there is an instead of trigger defined for the view, the WITH CHECK OPTION does not have any effect.
Creating Views Based on Other Views
Views can be based on other views. When a view is created based upon another view or views, the original view’s limitations are carried over to the new view.
CREATE VIEW customer_addresses (surname, forename, recipient,
address_1, address_2, town, postcode, country,
salutation, customer_id)
AS SELECT surname, forename,
UPPER(recipient(title, forename, surname)), address_1,
COALESCE(address_2, ' '), UPPER(town), UPPER(postcode), UPPER(country),
salutation(title, forename, surname, date_of_birth, country_code),
customer_id
FROM customer_details
JOIN countries ON code = country_code;
A secondary index is automatically used during searching when it improves the efficiency of the search.
Secondary indexes are maintained by the system and are invisible to the user.
Any column(s) may be specified as a secondary index, except columns declared using a LOB data type.
Columns in the PRIMARY KEY, the columns of a FOREIGN KEY and columns defined as UNIQUE are automatically indexed, (in the order in which they are defined in the key), and therefore creation of an index on these columns will not improve performance.
Secondary index tables are purely for Mimer SQL’s internal use – you create the index, and Mimer SQL handles the rest.
If, for instance, you want to know which products were released on a specific date, Mimer SQL would have to search successively through the entire ITEMS table to find all items that matched the date you specified. If, however, you create a secondary index on release date, Mimer SQL would locate that date directly in the secondary index, which would save time.
Secondary indexes can improve the efficiency of data retrieval; but introduces an overhead for write operations (UPDATE, INSERT, DELETE). In general, you should create indexes only for columns that are frequently searched.
Indexes cannot be created directly on columns in views. However, since searching in a view is actually implemented as searching in the base table, an index on the base table will also be used in view operations.
Examples of Secondary Index
Create a secondary index called ITM_RELEASE_DATE on the RELEASE_DATE column in the ITEMS table:
CREATE INDEX itm_release_date ON items(release_date);
Primary key columns may also be included in a secondary index. If a table has the primary key columns A, B and C, the primary index would cover all three columns of the primary key.
The following combinations of the columns in the primary key are automatically indexed: A, AB and ABC. In addition, you could create secondary indexes on columns B, C, BC, AC etc.
An index may also be defined as UNIQUE, which means that the index value may only occur once in the table. (For this purpose, null is treated as equal to null). However, it is preferable to use unique constraints.
Create a UNIQUE secondary index called ITM_EAN_CODE on the EAN_CODE column in the ITEMS table:
CREATE UNIQUE INDEX itm_ean_code ON ITEMS(ean_code);
Sorting Indexes
The sorting order for indexes may be defined as ascending or descending. However, this makes no difference to the efficiency of the index, since Mimer SQL searches indexes forwards or backwards depending on the circumstances. I.e. the following two indexes are compatible, and only one of them is required.
CREATE INDEX idx_asc ON t1 (c1 ASC)
CREATE INDEX idx_desc ON t1 (c1 DESC)
In some cases specifying the sort order makes sense. For example when ordering the result set by mixed orders, e.g:
SELECT * FROM t1
ORDER BY c1 ASC, c2 DESC;
In this case the index below is appropriate:
CREATE INDEX idx_mix ON t1 (c1 ASC, c2 DESC);
Synonyms, or alternative names can be created for tables, views or other synonyms. You can create synonyms to personalize tables or just for your own convenience. Synonym names can be made up of a maximum of 128 characters.
Table names are ‘qualified’ by the name of the schema to which they belong. The qualified form of the table name is the schema name followed by the table name and the two are separated by a period.
Synonyms are particularly useful when several users refer to a common table, such as MIMER_STORE.ITEMS, MIMER_STORE.CURRENCIES, etc. With synonyms, several users can work in the same apparent environment without needing to refer to the tables by their qualified names.
Synonym Examples
The table ITEMS in the schema MIMER_STORE has the qualified name:
MIMER_STORE.ITEMS
The ident called MIMER_STORE need only refer to it as:
ITEMS
If other users wish to use this table, they must refer to it by its fully qualified name since they do not have the same name as the schema to which the table belongs.
If a user named JAMES, who wishes to refer to the ITEMS table, belonging to the schema MIMER_STORE, as simply ITEMS, he can create a synonym.
In the following example, the schema name JAMES is implied by default (which must also have been created by user JAMES if the CREATE is to succeed) because the synonym name is specified in its unqualified form (and the default schema name is the name of the current ident):
CREATE SYNONYM items FOR mimer_store.items;
Another user can then create his own synonym for the ITEMS synonym that now exists in schema 'JAMES', which has the fully qualified name:
JAMES.ITEMS
Comments may be stored against any of the following objects:
|
COLUMN |
IDENT |
PROCEDURE |
SHADOW |
TRIGGER |
|
DATABANK |
INDEX |
SCHEMA |
SYNONYM |
TYPE |
|
DOMAIN |
METHOD |
SEQUENCE |
TABLE |
VIEW |
|
FUNCTION |
MODULE |
|
|
|
Comments cannot be deleted – they can only be replaced by a new comment. A blank string may be provided as a comment if you want to suppress an existing comment.
Only the creator of the object may store a comment for it.
Comments are for information only and do not affect data retrieval or manipulation in any way.
Comments may be read with the DESCRIBE command, see DESCRIBE, or by retrieving the appropriate columns from the INFORMATION_SCHEMA views, see the Mimer SQL Reference Manual.
Comment Example
Store the comment 'Holds currency details' on the CURRENCIES table:
COMMENT ON TABLE currencies IS 'Holds currency details';
Altering Databanks, Tables and Idents
The following sections explain how to alter databanks, tables and idents. you can also read about which objects you cannot alter.
Databanks can only be altered by their creator.
There are three uses for the ALTER statement:
•to change the physical file location for a databank
•to change the transaction and logging options on the databank
•to manage the file size allocated for the databank.
Examples
Change which file the MIMER_ORDERS databank is stored in from its previous file to file 'DISK2:MIMER_ORDERS.DBF':
Note:The file specification is in Alpha/OpenVMS format.
ALTER DATABANK mimer_orders SET FILE 'DISK2:[DBD]MIMER_ORDERS.DBF';
Note:This statement changes the filename stored for the databank in the data dictionary. It does not actually move the databank to the new location.
To move a databank, begin by copying or renaming the file in the operating system and then use ALTER DATABANK… SET FILE to change the file specification in the data dictionary.
Change the option on the MIMER_BLOBS databank from TRANSACTION to LOG:
ALTER DATABANK mimer_blobs SET OPTION LOG;
Set the size of the MIMER_BLOBS database to 2000 MB:
ALTER DATABANK mimer_blobs SET FILESIZE 2000 M;
Note:Use of the ALTER DATABANK… SET FILESIZE statement is not strictly necessary because databank files are extended dynamically. However, increasing the file allocation by a relatively large figure can help to minimize file fragmentation and improve response times.
The ALTER TABLE statement changes the definition of the specified table and may only be used by the creator of the schema to which the table belongs.
There are the following uses for the ALTER TABLE statement:
•to add a new column or table constraint definition to an existing table
•to drop a column or table constraint from an existing table
•to change the default value for a column in an existing table
•to drop the default value for a column in a table
•to change a column in an existing table to have a specified data type, provided the old and new data types are assignment-compatible, see the Mimer SQL Reference Manual and the column is not referenced by any constraints or views
A new column created with the ALTER TABLE… ADD statement is appended to end of the existing column list. The new column will include the default value defined for the column or defined for the domain to which it belongs or, if no default value exists, the null value.
Note:If a column added to a table is defined as NOT NULL, then it must have a default value defined or belong to a domain which has a default value, because the NOT NULL column cannot be given null values.
Examples
Add a column called CREDIT_RATING with a data type of CHAR(1) to the CUSTOMERS table:
ALTER TABLE customers ADD credit_rating CHAR(1);
This creates a column containing the null value in each row in the table.
If a constraint is added to a table, the data in the table is checked to ensure it fulfills the restriction in the constraint.
Drop the column DATE_OF_BIRTH from the table CUSTOMERS, subject to the condition that there are no other objects dependent on this column:
ALTER TABLE customers DROP date_of_birth RESTRICT;
Drop the column DATE_OF_BIRTH from the table CUSTOMERS, if dependent objects exist, these are dropped as well:
ALTER TABLE customers DROP date_of_birth CASCADE;
Change the length of the column FORMAT in the table FORMATS:
ALTER TABLE formats ALTER COLUMN format VARCHAR(32);
Change the default value for the column REORDER_LEVEL, the new default value is one:
ALTER TABLE items ALTER reorder_level SET DEFAULT 1;
Drop the check constraint ITM_PRICE_ILLEGAL from the ITEMS table:
ALTER TABLE items DROP CONSTRAINT itm_price_valid;
Redefine a foreign key constraint for the CUSTOMERS table:
ALTER TABLE customers DROP CONSTRAINT cst_countries;
ALTER TABLE customers ADD CONSTRAINT cst_countries
FOREIGN KEY (country_code) REFERENCES countries
ON DELETE CASCADE ON UPDATE NO ACTION;
Drop the default value for the column REGISTERED:
ALTER TABLE customers ALTER registered DROP DEFAULT;
Note on Dropping
When dropping a column from a table, the CASCADE and RESTRICT keywords can be used to specify the action that will be taken on objects that are dependent on the dropped column.
If CASCADE is specified, dependent objects are also dropped. For instance if a dropped column is part of a primary key, the primary key will also be dropped.
If RESTRICT (the default) is specified and there are other objects affected, the statement will be aborted, with an error condition. See also, Dropping Objects from the Database.
Only passwords can be altered with the ALTER IDENT statement. Ident names cannot be altered.
USER and PROGRAM idents can change their own password if they so wish.
Passwords can also be changed by the creator of the ident. Also, an ident without a password is not allowed to set the password, only the creator of the ident may do this.
Change the ident MIMER_ADM's password to 'evjkl9u'.
ALTER IDENT mimer_adm SET PASSWORD 'evjkl9u';
Objects Which May Not Be Altered
Domains, functions, procedures, modules, triggers, views and indexes cannot be altered. It is therefore important that you think through your domains and views thoroughly and carefully before you create them to make sure that they suit the needs of your database.
The functions and procedures contained in a module are created when the module is created and thereafter no alterations can be made to the module (the module and all the routines contained in it can, of course, be dropped).
The next section will discuss dropping objects and the results of this on the database.
Dropping Objects from the Database
The DROP statement is used to drop the following objects from the database:
|
COLLATION |
INDEX |
SEQUENCE |
TABLE |
|
DATABANK |
METHOD |
SHADOW |
TRIGGER |
|
DOMAIN |
MODULE |
STATEMENT |
TYPE |
|
FUNCTION |
PROCEDURE |
SYNONYM |
VIEW |
|
IDENT |
SCHEMA |
|
|
The CASCADE or RESTRICT keywords may be used to specify the action to be taken if other objects exist that are dependent on the object being dropped:
•If RESTRICT (the default) is specified, an error is returned if other objects are affected and the drop operation is aborted.
•If CASCADE is specified, dependent objects are dropped as well.
System database objects can only be dropped by their creator. Private database objects can only be dropped by the creator of the schema to which they belong.
Therefore use caution when using the DROP statement with CASCADE, as the operation may have a recursive effect on all objects relating to it. For example, when a table is dropped, all views, synonyms, routines and triggers created on or referencing that table are also dropped.
The DROP statement removes whole objects from the database. It cannot be used to remove columns from tables, this is done by the ALTER TABLE statement, see Altering Tables.
Drop the CURRENCIES table:
DROP TABLE currencies RESTRICT;
If the keyword CASCADE is specified, all views, synonyms and indexes based on CURRENCIES are also dropped as well as any functions, procedures and triggers referencing the table.
Drop the MIMER_STORE databank:
DROP DATABANK mimer_store RESTRICT;
If the keyword CASCADE is specified, all tables in the MIMER_STORE databank are also dropped and any views, synonyms, triggers and indexes based on those tables are also dropped as well as any functions, procedures and triggers referencing any of the dropped objects.
An attempt is automatically made to delete the physical databank file when a databank is dropped.
There may be occasions, because of access rights issues in the file system, when the database server’s attempt to delete the physical databank file might fail. If recommended procedures for databank file management are followed, see the Mimer SQL System Management Handbook, the databank file should be deleted correctly.
Dropping Sequences
When a sequence is dropped, all the objects (i.e. constraints, domains, functions, procedures, default values, triggers and views) referencing the sequence are also dropped.
Drop the CUSTOMER_ID_SEQ sequence:
DROP SEQUENCE customer_id_seq CASCADE;
The specification of CASCADE ensures that the sequence is dropped even if it is being referenced by other objects in the database.
When a domain is dropped, columns using the domain retain the properties of the domain through the creation of column constraints.
Drop the EUROS domain:
DROP DOMAIN euros CASCADE;
Note:If you re-create a domain that has been dropped, the domain will be seen as a completely new domain and it will not be associated with any columns that belonged to the old domain.
To change the restrictions on the columns that were defined with a domain that has been dropped, use the ALTER TABLE statement.
When an ident is dropped, everything that the ident has created (including other idents and everything created by those idents) as well as all privileges granted by the ident are dropped. For this reason, physical users should never own objects, except for synonyms and personal views.
Drop the MIMER_ADM ident:
DROP IDENT mimer_adm RESTRICT;
Dropping Functions, Modules, Procedures and Triggers
The effect of using the keyword CASCADE can be rather dramatic when modules, routines and triggers are dropped. For this reason it is recommended that all those objects are created by running a command file so they can be easily reconstructed in case of being dropped by mistake.
Drop the function called MIMER_STORE_BOOK.FORMAT_ISBN:
DROP FUNCTION mimer_store_book.format_isbn CASCADE;
Drop the procedure called COMING_SOON:
DROP PROCEDURE coming_soon CASCADE;
Drop the module called MIMER_STORE_MUSIC.ROUTINES:
DROP MODULE mimer_store_music.routines CASCADE;
Drop the trigger called PRODUCTS_AFTER_INSERT:
DROP TRIGGER products_after_insert CASCADE;
About Dropping Modules and Routines
The following points should be noted when dropping modules and routines:
•When a module is dropped, all the routines contained in it will be dropped.
•If a routine is dropped and it is referenced from another object, the referencing object will also be dropped.
•If a routine belonging to a module is to be dropped as a consequence of a cascade, only that routine is dropped (the other routines in the module and the module itself will remain unaffected).