Creates a new table.
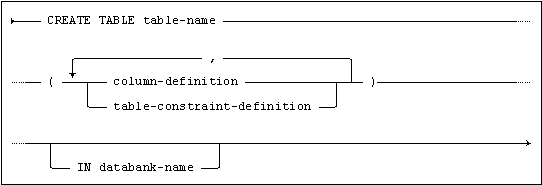
where column-definition is:
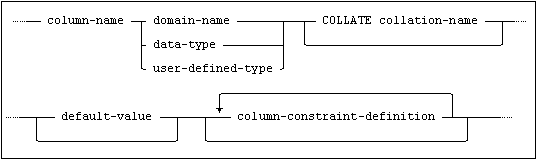
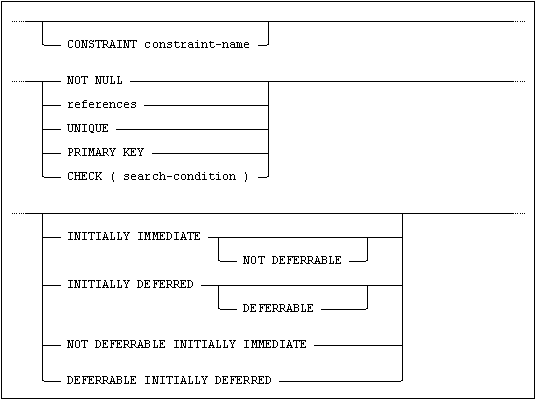
and column-constraint-definition is:
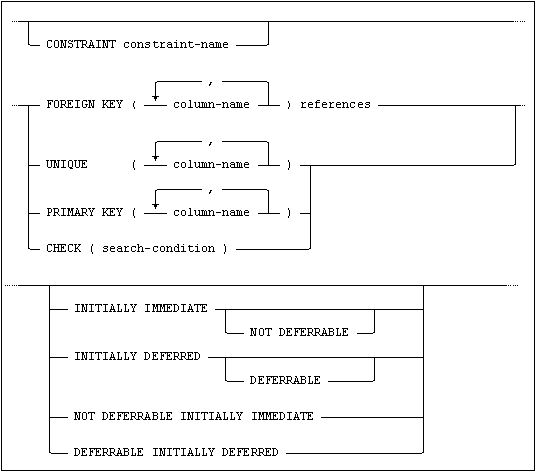
and table-constraint-definition is:
and references is:
and update-rule is:
and delete-rule is:
Usage
Embedded, Interactive, Module, ODBC, JDBC.
Description
A new table is created as specified.
If table-name is specified in its unqualified form, the table will be created in the schema which has the same name as the current ident.
If table-name is specified in its fully qualified form (i.e. schema-name.table-name) the table will be created in the named schema (in this case, the current ident must be the creator of the specified schema).
The table definition includes a list of column-definition’s and table-constraint-definition’s.
The table must be created in a databank on which the current ident has TABLE privilege.
If IN databank-name is not specified, the system will choose a databank on which the user has TABLE privilege. If more than one such databank exists, databanks created by the current ident are chosen in preference to others and the databank with the most secure transaction option is chosen (i.e. a databank with LOG option would be chosen in preference to one with TRANSACTION option and one with TRANSACTION option in preference to one with WORK option).
The new table is empty until data is inserted.
Column Definitions
The columns will appear in the table in the order specified. Each column name must be unique within the table. Column formats may be specified either by explicit data type, see Data Types in SQL Statements, or by specifying the name of a domain to which the column will belong. In the latter case, all the properties of the domain apply to the column.
A default value can be defined for the column by specifying default-value in column-definition or by having the column belong to a domain for which a default value is defined. A default value specified in default-value will take precedence over a domain default value and the data type of the value specified in default-value must conform to the data type of the column.
The default value will be assigned to a column whenever an INSERT is performed with no explicit value supplied. If the defined default value does not conform to other constraints, e.g. a CHECK constraint, then an INSERT must supply a value. The default value will also be assigned by an UPDATE statement with DEFAULT specified as update value.
The COLLATE Clause
In order to enable string data comparison and ordering, you can specify a COLLATE clause for a column.
A collation specified in the column-definition will take precedence over a domain collation.
By doing so, the collation defined will always considered in clauses such as WHERE, ORDER BY and GROUP BY, as well as when using relational and comparison operators. For more information, see the Mimer SQL User's Manual, Collations.
One or more constraints may be defined on the table, either by specifying a column-constraint-definition in a column-definition or by the specifying a table-constraint-definition in the table element list.
All table constraints may be named by specifying a constraint-name in the column-constraint-definition or table-constraint-definition. If a constraint is defined without specifying an explicit name, an automatically generated name will be assigned to it.
Note:Automatically generated constraint names start with SQL_, so it is recommended that this initial character sequence be avoided when explicitly specifying a constraint name.
Constraint names are shown in the appropriate INFORMATION_SCHEMA views, see INFORMATION_SCHEMA dictionary views.
The constraint name is used to identify a constraint when it is dropped using the ALTER TABLE statement. For more information, see ALTER TABLE.
NOT NULL Constraints
If this constraint is specified in a column-constraint-definition in the column-definition for a column, the column will not accept an attempt to insert the null value.
PRIMARY KEY Constraint
One PRIMARY KEY can be defined for the table, composed of one or more of the table columns.
The same column must not occur more than once in the primary key.
A column that is a part of the primary key will implicitly be constrained as NOT NULL, regardless of any NOT NULL constraints explicitly defined on the table. The null value cannot, therefore, occur in a primary key column.
The purpose of a primary key is to define a key value that uniquely identifies each table row, therefore the primary key value for each row in the table must be unique.
The primary key value for a table row is the combined value of the column(s) making up the primary key. The column(s) of the primary key (and their order in the key) can be defined using the PRIMARY KEY clause in a table-constraint-definition.
If the primary key for the table is to be composed of only a single column, then it can be defined by specifying PRIMARY KEY in a column-constraint-definition in the column-definition for that column.
UNIQUE Constraints
One or more UNIQUE constraints can be defined on the table. A UNIQUE constraint defines a unique key for the table. A unique key is composed of one or more table columns, just like the primary key. A column must not occur more than once in the same unique key.
A unique key defines a key value that uniquely identifies each row in the table, therefore a table cannot contain two rows which have the same value for a unique key unless one or more of the columns are null.
A unique key must not be composed of the same set of column(s) (occurring in any order) as either the primary key or an existing unique key defined for the table.
A unique key value for a table row is the combined value of the column(s) making up the unique key. The column(s) of the unique key (and their order in the key) can be defined using the UNIQUE clause in a table-constraint-definition.
If a unique key is to be composed of only a single column, then it can be defined by specifying UNIQUE in a column-constraint-definition in the column-definition for that column.
Note:Multiple occurrences of the null-value do not violate a UNIQUE constraint. (However, a UNIQUE INDEX allows just one null-value. See CREATE INDEX.)
REFERENTIAL Constraints
A referential constraint defines a foreign key relationship between the table being created (the referencing table) and another table in the database (the referenced table).
A foreign key relationship exists between a key (the foreign key) in the referencing table and the primary key or one of the unique keys of the referenced table.
The foreign key in the referencing table is defined by using the FOREIGN KEY clause in table-constraint-definition and is composed of one or more columns of the referencing table. The same referencing table column cannot occur more than once in the foreign key.
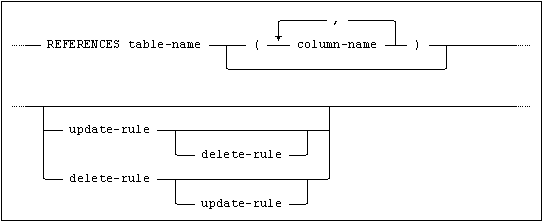
The corresponding key in the referenced table is specified by using the REFERENCES clause in references. If a list of column names is not specified after the name of the referenced table, then the primary key of the referenced table is assumed.
More than one foreign key can be defined for a table and the same table column can occur in more than one of the foreign keys.
The name of the referenced table must be specified in its fully qualified form if the name of the schema to which it belongs is not the same as the current ident.
The i-th column in the referencing table foreign key corresponds to the i-th column in the specified key of the referenced table and both keys must be composed of the same number of columns.
The data type and data length of each column in the referencing table foreign key must be identical to the data type and data length of the corresponding column in the specified key of the referenced table.
The effect of a referential constraint is to constrain table data in a way that only allows a row in the referencing table which has a foreign key value that matches the specified key value of a row in the referenced table.
One or more of the columns in a foreign key may permit the null value (this will be the case if there is no NOT NULL constraint or equivalent CHECK constraint in effect for the column).
A referencing table row which has a foreign key value with the null value in at least one of the columns will always fulfil the referential constraint and therefore be acceptable as a row in the referencing table.
If all of the columns in a foreign key are constrained not to accept the null value, then the only rows that will be accepted in the referencing table are those with a foreign key value that already exists in the corresponding key of the referenced table.
A referential constraint can be defined by specifying a FOREIGN KEY clause in table-constraint-definition. If a referencing table foreign key is to be composed of only a single column, then the referential constraint can be defined by specifying references in a column-constraint-definition in the column-definition for that column.
Rules can be defined in references that specify an action to be performed on the affected row(s) of the referencing table when a delete or update operation in the referenced table causes a referential constraint to be violated (because rows would consequently exist in the referencing table those foreign key value did not match the corresponding key value of a row in the referenced table).
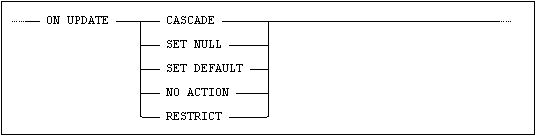
One of the following actions can be specified for a referential constraint for update operations:
•ON UPDATE CASCADE - referencing columns in affected rows in the referencing table will be set to the updated value of the referenced columns in the referenced table.
•ON UPDATE SET NULL - referencing columns in affected rows in the referencing table will be set to the null value.
•ON UPDATE SET DEFAULT - referencing columns in affected rows in the referencing table will be set to the default value for that column.
•ON UPDATE RESTRICT - this implies that the checking of the constraint will be done once for each row affected by the update statement.
•ON UPDATE NO ACTION - this implies that the checking of the constraint is done either when the update statement is completed or at commit, depending on the deferrability of the constraint.
If no update-rule is specified, ON UPDATE NO ACTION is default.
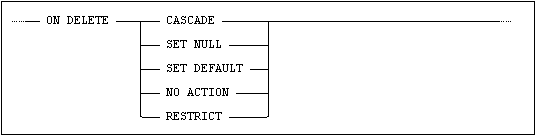
One of the following actions can be specified for a referential constraint for delete operations:
•ON DELETE CASCADE - the affected rows in the referencing table are deleted
•ON DELETE SET NULL - the relevant foreign key columns of the affected rows in the referencing table will be set to the null value.
•ON DELETE SET DEFAULT - the relevant foreign key columns of the affected rows in the referencing table will be set to the default value for that column.
•ON DELETE RESTRICT - this implies that the checking of the constraint will be done once for each row affected by the delete statement.
•ON DELETE NO ACTION - this implies that the checking of the constraint is done either when the delete statement is completed or at commit, depending on the deferrability of the constraint.
If a delete-rule is not specified, then ON DELETE NO ACTION is default.
CHECK Constraints
One or more check constraints can be defined on the table, which will determine whether the changes resulting from an INSERT or UPDATE operation will be accepted or rejected.
The search-condition which defines the check constraint must not contain a select-specification, an invocation of a set function, a reference to a host variable, or a non-deterministic expression. (However, as a work-around invoked functions may contain such functionality.)
If the search-condition of a check constraint specified in a table-constraint-definition contains column references, they must be columns in the table being created.
If the search-condition of a check constraint specified in a column-constraint-definition in a column-definition contains a column reference, it must be the column identified by column-name of the column-definition.
The search-condition of a check constraint defined on the table will be evaluated whenever a new row is inserted into the table and whenever an existing row is updated.
The values for any column reference(s) contained in the search-condition will be taken from the row being inserted or updated.
The data change operation will only be accepted if the search condition does not evaluate to false.
Constraint Characteristics
When defining a constraint it is possible to specify that the constraint should either be INITIALLY IMMEDIATE or INITIALLY DEFERRED. This attribute defines when the constraint is checked.
A constraint that is specified as INITIALLY IMMEDIATE is checked when a statement is executed. Constraints are INITIALLY IMMEDIATE by default.
A constraint that is specified as INITIALLY DEFERRED is checked at commit.
Note that for a foreign key constraint, it is only the checking that is deferred to commit time. I.e. referential actions such as CASCADE, SET DEFAULT, SET NULL and RESTRICT are all performed when the statement is executed.
Language Elements
default-value, see Default Values.
search-condition, see Search Conditions.
Restrictions
CREATE TABLE requires TABLE privilege on the databank in which the table is to be created.
The table name must not be the same as the name of any other table, view, synonym, index or constraint belonging to the same schema.
If a domain name is specified for column-definition, USAGE privilege must be held on the domain.
Each table-constraint-definition can only be specified once in the CREATE TABLE statement.
If a UNIQUE constraint is defined on the table, it must be stored in a databank with the TRANSACTION or LOG option.
If a REFERENTIAL constraint is defined, both the referencing table and the referenced table must be stored in a databank with the TRANSACTION or LOG option.
A constraint name must not be the same as the name of any other table, view, synonym, index or constraint belonging to the same schema.
The creator of the table must hold REFERENCES privilege on all the columns specified in references.
The name of a view cannot be specified for table-name in references.
When creating a table with a foreign key, you, the creator, must have exclusive access to the referenced table.
A column of LARGE OBJECT data type is not allowed in any type of table constraint but NOT NULL.
The constraint mode INITIALLY DEFERRED can only be specified for referential constraints.
Notes
The creator of the table is granted all access privileges to the table WITH GRANT OPTION.
In a REFERENTIAL constraint, the referenced table can be the same as referencing table. In this situation, the table data is constrained in a way that only allows the foreign key columns to contain key values that are already present in the referenced (primary or unique) key.
If a name is not specified for a table or column constraint, a system generated name is applied to it. System generated names will begin with SQL_ so it is recommended that this starting character sequence be avoided for explicitly specified constraint names.
The primary key and the unique keys for a table are not dissimilar in their function and they constrain data in the same way apart from the fact that primary key columns are always defined as not null, however a unique key should not be used instead of a primary key. One reason for this is that the primary key is handled more efficiently than the unique keys, so there is a performance advantage. See Relational Databases – Selected Writings by C. J. Date for a discussion of primary and unique keys.
Example
CREATE TABLE eng_table (col_1 INTEGER,
col_2 NCHAR(2000) COLLATE english_1,
PRIMARY KEY (col_1));
For many more examples, see the Mimer SQL User's Manual, Creating Tables.
Standard Compliance
|
Standard |
Compliance |
Comments |
|---|---|---|
|
SQL-2016 |
Core |
Fully compliant. |
|
SQL-2016 |
Features outside core |
Feature F191, “Referential delete actions”. Feature F251, “Domain support”. Feature F491, “Constraint management”, support for named constraints. Feature F690, “Collation support”. Feature F701, “Referential update actions”. Feature F721, “Deferrable constraints”, only for referential constraints. Feature T591, “UNIQUE constraints of possibly null columns”. |
|
|
Mimer SQL extension |
Support for the IN databank-name clause is a Mimer SQL extension. |