This chapter presents the basic elements of the SQL language and the simplest relationships between them.
It covers the following units:
|
Syntax unit |
Summary |
Section |
|---|---|---|
|
Separators |
Syntax element delimiters. |
|
|
Special characters |
Syntax pattern characters. |
|
|
Identifiers |
SQL identifiers, host variable names and keywords. |
|
|
Data types |
Character, integer, decimal, floating point, date, time, timestamp, interval, binary, boolean. |
|
|
Literals |
Character, integer, decimal, floating point, date, time, timestamp, interval, binary, boolean. |
Characters having the Unicode property “White_Space” are used as separators, e.g. <TAB>, <LF>, <VT>, <FF>, <CR> and <SP>.
Certain special characters have particular meanings in SQL statements; for example: delimiters, double quotation marks, single quotation marks and arithmetic and comparative operators.
The special characters $ and # may, in some circumstances, be used in the same contexts as letters, see Identifiers.
A separator is used to separate keywords, identifiers and literals from each other.
An identifier is defined as a sequence of one or more characters forming a unique name.
Identifiers are constructed according to certain fixed rules. It is useful to distinguish between SQL identifiers, which are local to SQL statements and host identifiers, which relate to the host programming language.
Rules for constructing host identifiers may vary between host languages.
SQL identifiers consist of a sequence of one or more Unicode characters. The maximum length of an SQL identifier is 128 characters.
SQL identifiers (except for delimited identifiers) must begin with a character having the Unicode property “ID_Start” or one of the special characters $ or #, and may then contain characters having the Unicode property “ID_Continue”. For a detailed description, see https://www.unicode.org/reports/tr31.
The case of letters in SQL identifiers is not significant, not even if it is a delimited identifier.
Delimited Identifiers
Delimited identifiers means identifiers enclosed in double quotation marks: "". Such identifiers are special in two aspects:
•They can contain characters normally not supported in SQL identifiers.
•They can be identical to a reserved word.
Two consecutive double quotation marks within a delimited identifier are interpreted as one double quotation mark.
Unicode Delimited Identifiers
A Unicode delimited identifier consists of a sequence of Unicode characters enclosed in double quotation marks and preceded by the letter U and an ampersand, i.e. U&. Unicode characters can be given by four hexadecimal digits preceded by a backslash character (\), or by six hexadecimal digits preceded with a backslash character and a plus character (\+).
Two consecutive backslash characters within a Unicode delimited identifier are interpreted as a single backslash character.
A Unicode delimited identifier is typically used when an identifier contains a character difficult to type using the keyboard. For example the identifier München can be given as U&"M\00FCnchen".
Examples
The following examples illustrate the general rules for forming SQL identifiers:
|
Valid |
Invalid |
Explanation |
|---|---|---|
|
COLUMN_1 |
COLUMN+1 |
COLUMN+1 is an expression |
|
#14 |
14 |
14 is an integer literal |
|
"MODULE" |
MODULE |
MODULE is a reserved word |
|
U&"M\00FCnchen" |
|
Unicode delimited identifier for München. |
Note:Leading blanks are significant in delimited identifiers.
Objects in the database may be divided into two classes:
System Objects
System objects, such as databanks, idents, schemas and shadows, are global to the system. System object names must be unique within each object class since they are common to all users. System objects are uniquely identified by their name alone.
Private Objects
Private objects, such as domains, functions, indexes, modules, precompiled statements, procedures, sequences, synonyms, tables, triggers and views, belong to a schema and have names that are local to that schema. In a given schema, the names used for tables, synonyms, views, indexes and constraints must be unique within that group of objects, i.e. a table cannot have a name that is already being used by a synonym, view, index or constraint etc. Similarly, in a given schema, the names used for domains must be unique within that group of objects.
Functions and procedures may have the same name as long as they differ with regard to the number of parameters or the data type of the parameter. See Mimer SQL Programmer's Manual, Parameter Overloading.
The names of all other objects, modules and sequences in the schema must be unique within their respective object-type. Two different schemas may contain objects of the same type with the same name. Private objects are uniquely identified by their qualified name (see below).
Names of private objects in the database may always be qualified by the name of the schema to which they belong. The schema name is separated from the object name by a period, with the general syntax: schema.object.
If a qualified object name is specified when an object is created, it will be created in the named schema. If an object name is unqualified, a schema name with the same name as the current ident is assumed.
It is recommended that object names are always qualified with the schema name in SQL statements, to avoid confusion if the same program is run by different Mimer SQL idents.
When the name of a column is expressed in its unqualified form it is syntactically referred to as a column-name.
When the name of a column must be expressed unambiguously it is generally expressed in its fully qualified form, i.e. schema.table.column or table.column, and this is syntactically referred to as a column-reference.
It is possible for a column-reference to be the unqualified name of a column in contexts where this is sufficient to unambiguously identify the column.
When the name of a column is used to indicate the column itself, e.g. in CREATE TABLE statements, a column-name must be used, i.e. the name of the column cannot be qualified.
The exception to this is in the COMMENT ON COLUMN statement where a column-reference is required because the name of the column must be qualified by the name of the table or view to which it belongs.
The contexts where the name of a column refers to the values stored in the column are:
•in expressions
•in set functions
•in search conditions
•in GROUP BY clauses.
In these contexts a column-reference must be used to identify the column.
The column name qualifiers which may be used in a particular SQL statement are determined by the way the table is identified in the FROM clause of the SELECT statement.
Alternative names (correlation names) may be introduced in the FROM clause, and the table reference used to qualify column names must conform to the following rules:
•If no correlation names are introduced:
The column name qualifier is the table name exactly as it appears in the FROM clause.
For example:
SELECT BOOKADM.HOTEL.NAME, ROOMS.ROOMNO
FROM BOOKADM.HOTEL JOIN ROOMS ...
but not
SELECT BOOKADM.HOTEL.NAME, ROOMS.ROOMNO
FROM HOTEL JOIN BOOKADM.ROOMS ...
•If a correlation name is introduced:
The correlation name and not the original table reference, may be used to qualify a column name. The correlation name may not itself be qualified.
For example:
SELECT H.NAME, ROOMS.ROOMNO
FROM HOTEL H JOIN ROOMS ...
but not
SELECT HOTEL.NAME, ROOMS.ROOMNO
FROM HOTEL H JOIN ROOMS ...
Outer References
In some constructions where subqueries are used in search conditions, see The SELECT Expression, it may be necessary to refer in the lower level subquery to a value in the current row of a table addressed at the higher level.
A reference to a column of a table identified at a higher level is called an outer reference. The following example shows the outer reference in bold type:
SELECT NAME
FROM HOTEL
WHERE EXISTS (SELECT * FROM
FROM BOOK_GUEST
WHERE HOTELCODE = HOTEL.HOTELCODE)
The lower-level subquery is evaluated for every row in the higher level result table. The example selects the name of every hotel with at least one entry in the BOOK_GUEST table.
A qualified column name is an outer reference if, and only if, the following conditions are met:
•The qualified column name is used in a search condition of a subquery.
•The qualifying name is not introduced in the FROM clause of that subquery.
•The qualifying name is introduced at some higher level.
•The qualified column name is valid everywhere in a subquery.
Parameter Markers and Host Identifiers
Parameter markers and host identifiers are used when passing input or output data. The concepts are very similar, the major difference is that parameter markers are used in dynamic SQL, where the parameter marker data type is decided at PREPARE time, while a host identifier is declared and has a defined data type.
Parameter Markers
A parameter marker is put in the location of an input or output expression in a prepared SQL statement.
Parameter markers are assigned data types appropriate to their usage. See the Mimer SQL Programmer's Manual, Dynamic SQL, for a discussion of dynamic SQL. For parameter markers used to represent data assigned to columns, the data type is in accordance with the column definition.
Mimer SQL supports different styles of parameter markers:
•Question mark parameter marker
A question mark parameter marker (?) will be NOT NULL or NULL depending on the input or output expression.
•Colon notation parameter marker
A colon notation parameter marker is specified as a colon followed by a parameter name, e.g. :lastname. A null indicator should be provided if the input or output expression is nullable, e.g. :lastname:indic.
If the same parameter marker name is used several times in an SQL statement, it is considered to be one parameter marker. A parameter marker name can only be used several times if the implied data types of the parameter markers are compatible. (The data type with highest precision/length will be chosen.)
Parameter markers are usually referenced in order by appearance, from left to right. However, if numbers are specified as parameter marker names, these numbers will decide the parameter order.
Examples
UPDATE persons
SET last_name = :plastname
WHERE id = :pid;
DELETE FROM persons WHERE id = ?;
SELECT LastName as Name, Address
FROM staff
WHERE City = :cityname
UNION ALL
SELECT companyName, Address
FROM companies
WHERE City = :cityname;
UPDATE persons
SET last_name = :2
WHERE id = :1;
CREATE TABLE tc (x REAL, y DOUBLE PRECISION);
INSERT INTO tc VALUES (:cval, :cval); -- :cval data type is DOUBLE PRECISION
CREATE TABLE persons (first_name VARCHAR(10), last_name VARCHAR(15));
INSERT INTO persons VALUES (:name, :name); -- :name data type VARCHAR(15)
Host identifiers are used in SQL statements to identify objects associated with the host language such as variables, declared areas and program statement labels.
Host identifiers are formed in accordance with the rules for forming variable names in the particular host language, see the Mimer SQL Programmer's Manual, Host Language Dependent Aspects.
Host identifiers are never enclosed in delimiters and may coincide with SQL reserved words.
The length of host identifiers used in SQL statements may not exceed 128 characters, even if the host language accepts longer names.
Whenever the term host-variable appears in the syntax diagrams, one of the three following constructions must be used:
:host-identifier1
or
:host-identifier1 :host-identifier2
or
:host-identifier1 INDICATOR :host-identifier2
Host-identifier1 is the name of the main host variable.
Host-identifier2 is the name of the indicator variable, used to signal the assignment of a null value to the host variable. See the Mimer SQL Programmer's Manual, Indicator Variables, for a description of the use of indicator variables.
The colon preceding the host identifier serves to identify the variable to the SQL compiler and is not part of the variable name in the host language.
A target variable is an item that may be specified as the object receiving the result of an assignment or a SELECT INTO. The objects that may be specified where a target variable is expected differ depending on whether the context is Procedural usage or Embedded usage. For more information, see Usage Modes.
In the syntax diagrams, replace the term target-variable, with the following construction:

where routine-variable is:

For more information, see: DECLARE VARIABLE, CREATE FUNCTION and CREATE PROCEDURE.
Note:A routine-variable may only be specified in a procedural usage context.
Reserved Words
Reserved Words gives a list of keywords reserved in SQL statements. These words must be enclosed in double quotation marks, "", if they are used as SQL identifiers.
Example
SELECT "MODULE" FROM ...
Standard Compliance
This section summarizes standard compliance concerning identifiers.
|
Standard |
Compliance |
Comments |
|---|---|---|
|
SQL-2016 |
Core |
Fully compliant. |
|
SQL-2016 |
Features outside core |
Feature F391, “Long identifiers”. Feature F392, “Unicode escapes in identifiers”. |
|
|
Mimer SQL extension |
The use of the special characters $ and # in identifiers is a Mimer SQL extension. Parameter marker as a colon followed by an integer literal is a Mimer SQL extension. |
Mimer SQL supports the following data type categories:
•Character strings, see Character Strings
•National character strings, see National Character Strings
•Binary, see Binary
•Numerical, see Numerical
•Datetime, see Datetime
•Interval, see Interval
•Boolean, see Boolean
•Spatial, see Spatial Data Types.
•Universally unique identifier (UUID), see Universally Unique Identifier (UUID)
In SQL statements, you make explicit data type references when creating tables and domains and altering tables. You also use data types in CAST and stored procedure variable declarations.
In addition, there is also a ROW type that can be used in stored procedures only, for more information see ROW Data Type.
The character string data types store sequences of bytes that represent alphanumeric data, according to ISO 8859-1.
The character string data type category contains the following data types:
|
Data Type |
Abbreviations |
Description |
Range |
|---|---|---|---|
|
CHAR(n) |
Character string, fixed length n. |
1 <= n <= 15 000 |
|
|
CHAR VARYING(n) VARCHAR(n) |
Variable length character string, maximum length n. |
1 <= n <= 15 000 |
|
|
CHAR LARGE |
Variable length character string measured in characters. |
For information on the object length, see Specifying the CLOB Length. |
The CHARACTER (CHAR) data type stores string values of fixed length in a column.
You specify the length of the CHAR data type as the length of the column when you create a table. You can specify the length to be any value between 1 and 15 000.
When Mimer SQL stores values in a column defined as CHAR, it right-pads the values with spaces to conform with the specified column length.
Note:If you define a data type as CHARACTER or CHAR, that is, without specifying a length, the length of the data type is 1.
CHARACTER VARYING or CHAR VARYING or VARCHAR
The CHARACTER VARYING, abbreviated CHAR VARYING or VARCHAR, data type stores strings of varying length.
You specify the maximum length of the VARCHAR data type as the length of the column when you create a table. You can specify the length to be between 1 and 15 000.
CHARACTER LARGE OBJECT or CLOB
The CHARACTER LARGE OBJECT (CLOB) data type stores character string values of varying length up to the maximum specified as the large object length (n[K|M|G]).
The large object length is n, optionally multiplied by K|M|G.
You can specify the maximum length of the CLOB data type as the length of the column when you create the table.
If you specify <n>K (kilo), the length (in characters) is <n> multiplied by 1 024.
If you specify <n>M (mega), the length is <n> multiplied by 1 048 576.
If you specify <n>G (giga), the length is <n> multiplied by 1 073 741 824.
If you do not specify large object length, Mimer SQL assumes that the length of the data type is 1M.
The maximum length of a CLOB is determined by the amount of disk space available for its storage.
You can work with CLOBs as follows:
•Retrieving CLOBs with simple column references in the SELECT clause of a SELECT statement
•Assigning CLOBs using INSERT statements with a VALUES clause
•Assigning CLOBs using UPDATE statements
•Adding CLOB columns using CREATE TABLE or ALTER TABLE
•Dropping CLOB columns using ALTER TABLE
•Altering CLOB column data types using ALTER TABLE
There are some restrictions associated with using CLOBs. The only comparisons supported for CLOB values are using the NULL predicate and using the LIKE predicate.
The only scalar functions which can be used on CLOB columns are SUBSTRING, CHAR_LENGTH and OCTET_LENGTH.
A CLOB column may not be part of any primary key constraint, index, or unique constraint.
The comparison restrictions also prevent CLOB columns from being used in DISTINCT, GROUP BY and ORDER BY clauses, and UNION, INTERSECT and EXCEPT operations.
When defining a stored procedure or trigger it is not allowed to use a CLOB type for a parameter or a variable. It is allowed to create triggers for tables with CLOB columns with one exception, in an instead of trigger it is not possible to reference CLOB columns in the new table.
Collations
All character strings have a collation attribute. A collation determines the order for ordering and comparisons, see the Mimer SQL User's Manual, Collations, for a detailed description of collations.
Mimer SQL implements Unicode using the data type NCHAR (i.e. NATIONAL CHARACTER data type). The NCHAR data type is logically UTF-32, however, it is stored in a compressed form. Application host variables may use any of the three encoding forms UTF-8, UTF-16, or UTF-32 when storing NCHAR data in the database. The encoding forms are fully transparent; you may e.g. use UTF-16 to store data, and you can use UTF-8 for fetching data.
The CHAR data type is based on ISO 8859-1 (Latin1), which is a true subset of Unicode, and therefore CHAR and NCHAR are fully compatible.
Normalization
A Unicode character can have several equivalent representations. There are precomposed characters and there are combining characters that can be used together with base characters to form a specific character. Consider the letter E with circumflex and dot below, a letter that occurs in Vietnamese. This letter has five possible representations in Unicode:
•U+0045 LATIN CAPITAL LETTER E
U+0302 COMBINING CIRCUMFLEX ACCENT
U+0323 COMBINING DOT BELOW
•U+0045 LATIN CAPITAL LETTER E
U+0323 COMBINING DOT BELOW
U+0302 COMBINING CIRCUMFLEX ACCENT
•U+00CA LATIN CAPITAL LETTER E WITH CIRCUMFLEX
U+0323 COMBINING DOT BELOW
•U+1EB8 LATIN CAPITAL LETTER E WITH DOT BELOW
U+0302 COMBINING CIRCUMFLEX ACCENT
•U+1EC6 LATIN CAPITAL LETTER E WITH CIRCUMFLEX AND DOT BELOW
Any two of these sequences should compare equal. The Normalization Form C (NFC) of all five sequences is U+1EC6.
In Mimer SQL, Unicode data (NCHAR) is automatically transformed to NFC. When needed, literals and variables are implicitly normalized. The result of a concatenation will always be normalized, and string functions, like UPPER and LOWER, will always return a normalized result string. This will assert that all Unicode data will be in NFC, thus giving the expected result in search operations.
Example
SQL>create table t(c nchar(1));
SQL>insert into t values(u&'E\0302\0323');
SQL>insert into t values(u&'E\0323\0302');
SQL>insert into t values(u&'\00CA\0323');
SQL>insert into t values(u&'\1EB8\0302');
SQL>insert into t values(u&'\1EC6');
SQL>select count(c) as equal from t where c = u&'\1EC6';
EQUAL
=====
5
The normalization forms are fully described in the Unicode standard annex #15, Unicode Normalization Forms (https://www.unicode.org/reports/tr15).
When converting between upper and lower case most Unicode characters follow a one-to-one case mapping. However, a few characters expand to two or three characters in folding operations.
Folding operations do not always preserve normalization form. In a few instances, the casing operators must normalize after performing their core function.
Consider the following NFC string:
U+01F0 LATIN SMALL LETTER J WITH CARON,
U+0323 COMBINING DOT BELOW
Its upper case form is:
U+004A LATIN CAPITAL LETTER J,
U+030C COMBINING CARON,
U+0323 COMBINING DOT BELOW
However, the upper case normalized form (NFC) is:
U+004A LATIN CAPITAL LETTER J,
U+0323 COMBINING DOT BELOW,
U+030C COMBINING CARON
The Unicode definitions for one-to-one mappings are found here https://www.unicode.org/Public/6.1.0/ucd/UnicodeData.txt, and the expanding definitions are found here https://www.unicode.org/Public/6.1.0/ucd/SpecialCasing.txt.
National Character Data Types
The national character string data type category contains the following data types:
|
Data Type |
Abbreviations |
Description |
Range |
|---|---|---|---|
|
NATIONAL CHAR(n) |
National character string, fixed length n. |
1 <= n <= 5 000 |
|
|
NATIONAL CHAR VARYING(n) |
Variable length, national character string, maximum length n. |
1 <= n <= 5 000 |
|
|
NATIONAL CHAR LARGE OBJECT(n[K|M|G]) |
Variable length national character string measured in characters. |
For information on the object length, see Specifying the NCLOB Length. |
NATIONAL CHARACTER or NATIONAL CHAR or NCHAR
The NATIONAL CHARACTER (NCHAR) data type stores string values of fixed length in a column. You specify the length of the NATIONAL CHARACTER data type as the length of the column when you create a table. You can specify the length to be any value between 1 and 5 000.
When Mimer SQL stores values in a column defined as NATIONAL CHARACTER, it right-pads the values with spaces to conform with the specified column length.
Note:If you define a data type as NATIONAL CHARACTER or NCHAR, that is, without specifying a length, the length of the data type is 1.
NATIONAL CHARACTER VARYING or NATIONAL CHAR VARYING or NCHAR VARYING or NVARCHAR
The NATIONAL CHARACTER VARYING, abbreviated NVARCHAR, NATIONAL CHAR VARYING or NCHAR VARYING, data type stores strings of varying length.
You specify the maximum length of the NATIONAL CHARACTER VARYING data type as the length of the column when you create a table. You can specify the length to be between 1 and 5 000.
NATIONAL CHARACTER LARGE OBJECT or NCLOB
The NATIONAL CHARACTER LARGE OBJECT (NCLOB) data type stores national character string values of varying length up to the maximum specified as the large object length (n[K|M|G]).
The large object length is n, optionally multiplied by K|M|G.
You can specify the maximum length of the NCLOB data type as the length of the column when you create the table.
If you specify <n>K (kilo), the length (in characters) is <n> multiplied by 1 024.
If you specify <n>M (mega), the length is <n> multiplied by 1 048 576.
If you specify <n>G (giga), the length is <n> multiplied by 1 073 741 824.
If you do not specify large object length, Mimer SQL assumes that the length of the data type is 1M.
Maximum NCLOB Length
The maximum length of an NCLOB is determined by the amount of disk space available for its storage.
Using NCLOBs
You can work with NCLOBs as follows:
•Retrieving NCLOBs with simple column references in the SELECT clause of a SELECT statement
•Assigning NCLOBs using INSERT statements with a VALUES clause
•Assigning NCLOBs using UPDATE statements
•Adding NCLOB columns using CREATE TABLE or ALTER TABLE
•Dropping NCLOB columns using ALTER TABLE
•Altering NCLOB column data types using ALTER TABLE
There are some restrictions associated with using NCLOBs. The only comparison supported for NCLOB values are using the NULL predicate and using the LIKE predicate.
The only scalar functions which can be used on NCLOB columns are SUBSTRING, CHAR_LENGTH and OCTET_LENGTH.
An NCLOB column may not be part of any primary key constraint, index, or unique constraint.
The comparison restrictions also prevent NCLOB columns from being used in DISTINCT, GROUP BY and ORDER BY clauses, and UNION, EXCEPT and INTERSECT operations.
When defining a stored procedure or trigger it is not allowed to use a NCLOB type for a parameter or a variable. It is allowed to create triggers for tables with NCLOB columns with one exception, in an instead of trigger it is not possible to reference NCLOB columns in the new table.
Collations
All national character strings have a collation attribute. A collation determines the order for ordering and comparisons, see Mimer SQL User's Manual, Collations for a detailed description of collations.
The binary data type stores a sequence of bytes.
The binary data type category contains the following data types:
|
Data Type |
Abbreviation |
Description |
Range |
|---|---|---|---|
|
N/A |
Fixed length binary string, maximum length n. |
1 <= n <= 15 000 |
|
|
Variable length binary string, maximum length n. |
1 <= n <= 15 000 |
||
|
Variable length binary string measured in octets. |
For information on the object length, see Specifying the BLOB Length. |
Note:How binary data is displayed depends on the SQL tool used. For example, Mimer BSQL displays binary data as its hexadecimal value.
The BINARY LARGE OBJECT or BLOB data type stores binary string values of varying length up to the maximum specified as the large object length (n[K|M|G]).
The large object length is n, optionally multiplied by K|M|G.
Data stored in BLOB’s may only be stored in the database and retrieved again, it cannot be used in arithmetical operations.
If you specify <n>K, the length is <n> multiplied by 1 024.
If you specify <n>M, the length is <n> multiplied by 1 048 576.
If you specify <n>G, the length is <n> multiplied by 1 073 741 824.
If you do not specify large object length, Mimer SQL assumes that the length of the data type is 1M.
The maximum length of a BLOB is determined by the amount of disk space available for its storage.
Using BLOBs
You can work with BLOB’s as follows:
•Retrieving BLOB’s with simple column references in the SELECT clause of a SELECT statement
•Assigning BLOB’s using INSERT statements with a VALUES clause
•Assigning BLOB’s using UPDATE statements
•Adding BLOB columns using CREATE TABLE or ALTER TABLE
•Dropping BLOB columns using ALTER TABLE
•Altering BLOB column data types using ALTER TABLE
There are some restrictions associated with using BLOB’s. The only comparison supported for BLOB values is using the NULL predicate and using the LIKE predicate.
The only scalar functions which can be used on BLOB columns are SUBSTRING, CHAR_LENGTH and OCTET_LENGTH.
A BLOB column may not be part of any primary key constraint, index, or unique constraint.
The comparison restrictions also prevent BLOB columns from being used in DISTINCT, GROUP BY and ORDER BY clauses and UNION, EXCEPT and INTERSECT statements.
When defining a stored procedure or trigger it is not allowed to use a BLOB type for a parameter or a variable. It is allowed to create triggers for tables with BLOB columns with one exception, in an instead of trigger it is not possible to reference BLOB columns in the new table.
The numerical data type category contains the following data types:
|
Data type |
Abbreviation |
Description |
Range |
|---|---|---|---|
|
N/A |
Integer numerical, precision 5. |
-32 768 through 32 767 Corresponds to a 2 bytes, signed int. |
|
|
INT |
Integer numerical, precision 10. |
-2 147 483 648 through 2 147 483 647 Corresponds to a 4 bytes, signed int. |
|
|
N/A |
Integer numerical, precision 19. |
-9 223 372 036 854 775 808 through 9 223 372 036 854 775 807 Corresponds to an 8 bytes, signed int. |
|
|
INTEGER(p) |
INT(p) |
Integer numerical, precision p. |
1 <= p <= 45 |
|
DEC(p,s) |
Exact numerical, |
1 <= p <= 45 |
|
|
N/A |
Floating point value with 24-bit binary mantissa. |
Zero or absolute value from 1.40129846-45 to 3.40282347+38 Corresponds to single precision float. |
|
|
N/A |
Floating point value with 53-bit binary mantissa. |
Zero or absolute value from 4.9406564584124654-324 to 1.7976931348623157+308 Corresponds to double precision float. |
|
|
N/A |
Floating point value with 53-bit binary mantissa. |
Zero or absolute value from 4.9406564584124654-324 to 1.7976931348623157+308 Corresponds to double precision float. Same as DOUBLE PRECISION. |
|
|
FLOAT(p) |
N/A |
Floating point value with p digits in the decimal mantissa. |
1 <= p <= 45 |
All numerical data may be signed.
For all numerical data, the precision p indicates the maximum number of decimal digits the number may contain, excluding any sign or decimal point.
For decimal data, the scale s indicates the fixed number of digits following the decimal point.
Note:The decimal data with scale zero DECIMAL(p,0) is not the same as integer INTEGER(p).
For FLOAT(p), floating point (approximate numerical) data is stored in exponential form. The precision is specified for the mantissa only. The permissible range of the exponent is -999 to +999.
Specifying Data Type Precision and Scale
In the following cases, the omission of scale, or the omission of both precision and scale, is allowed (scale may not be specified without precision):
|
Data Type |
Abbreviation |
|
|---|---|---|
|
DECIMAL |
DEC |
is equivalent to DECIMAL(15,0) |
|
DECIMAL(5) |
DEC(5) |
is equivalent to DECIMAL(5,0) |
Note:The data type INTEGER is distinct from INTEGER(10). (INTEGER(10) may store values between -9 999 999 999 and 9 999 999 999, but INTEGER may only store values between -2 147 483 648 and 2 147 483 647.)
DATETIME is a term used to collectively refer to the data types DATE, TIME(s) and TIMESTAMP(s).
|
Data type |
Description |
|---|---|
|
TIME(s) TIMESTAMP(s) |
Composed of a number of integer fields, represents an absolute point in time, depending on sub-type. Default s value is 0 for TIME and 6 for TIMESTAMP. |
DATE
DATE describes a date using the fields YEAR, MONTH and DAY in the format YYYY-MM-DD. It represents an absolute position on the timeline.
TIME(s)
TIME(s) describes a time in an unspecified day, with seconds precision s, using the fields HOUR, MINUTE and SECOND in the format HH:MM:SS[.sF] where F is the fractional part of the SECOND value. It represents an absolute time of day.
TIMESTAMP(s)
TIMESTAMP(s) describes both a date and time, with seconds precision s, using the fields YEAR, MONTH, DAY, HOUR, MINUTE and SECOND in the format YYYY-MM-DD HH:MM:SS[.sF] where F is the fractional part of the SECOND value. It represents an absolute position on the timeline.
A DATETIME contains some or all of the fields YEAR, MONTH, DAY, HOUR, MINUTE and SECOND. These fields always occur in the order listed, which is from the most significant to least significant. Year is the most significant.
Each of the fields is an integer value, except that the SECOND field may have an additional integer component to represent the fractional seconds.
For a DATETIME value with a SECOND component, it is possible to specify an optional seconds precision which is the number of significant digits in the fractional part of the SECOND value. This must be a value between 0 and 9. If a SECOND’s precision is not specified, the default is 0 for TIME and 6 for TIMESTAMP.
Calendar and Clock
DATE values are represented according to the Gregorian calendar. TIME values are represented according to the 24 hour clock.
Inclusive Value Limits for DATETIME
The inclusive value limits for the DATETIME fields are as follows:
|
Field |
Inclusive value limit |
|---|---|
|
YEAR |
0001 to 9999 |
|
MONTH |
01 to 12 |
|
DAY |
01 to 31 (upper limit further constrained by MONTH and YEAR) |
|
HOUR |
00 to 23 |
|
MINUTE |
00 to 59 |
|
SECOND |
00 to 59.999999999 |
An INTERVAL is a period of time, such as: 3 years, 90 days or 5 minutes and 45 seconds.
|
Data Type |
Description |
|---|---|
|
Composed of a number of integer fields, represents a period of time, depending on the type of interval. |
There are effectively two kinds of INTERVAL:
•YEAR-MONTH
containing one or both of the fields YEAR and MONTH. (Also known as long interval.)
•DAY-TIME
containing one or more consecutive fields from the set DAY, HOUR, MINUTE and SECOND. (Also known as short interval.)
The distinction is made between the two interval types in order to avoid the ambiguity that would arise if a MONTH value was combined with a field of lower significance, e.g. DAY, given that different months contain differing numbers of days.
For example, the hypothetical interval 2 months and 10 days could vary between 69 and 72 days in length, depending on the months involved. Therefore, to avoid unwanted variations in the downstream arithmetic etc. the variable length MONTH component may only exist at the lowest significance level in an INTERVAL.
The SECOND field may also only exist at the lowest significance level in an INTERVAL, simply because it is the least significant of all the fields.
An INTERVAL data type is a signed numeric quantity (i.e. negative INTERVALs are allowed) comprising a specific set of fields. The list of fields in an INTERVAL is called the interval precision.
The fields in an INTERVAL are exactly the same as those previously described for DATETIME except that the value constraints imposed on the most significant field are determined by the leading precision (p in Interval Qualifiers) for the INTERVAL type and not by the Gregorian calendar and 24 hour clock.
A leading precision value between 1 and the maximum allowed for the field type may be specified for an INTERVAL. If none is specified, the default is 2.
Value Constraints for Fields in an Interval
The table below shows the maximum permitted leading precision values for each field type in an INTERVAL:
|
Field |
Maximum leading precision |
|---|---|
|
YEAR |
7 |
|
MONTH |
7 |
|
DAY |
7 |
|
HOUR |
8 |
|
MINUTE |
10 |
|
SECOND |
12 |
The value of a MONTH field, which is not in the leading field position, is constrained between 0 and 11, inclusive, in an INTERVAL (and not between 1 and 12 as in a DATETIME).
Where the SECOND field is involved, seconds precision (s in Interval Qualifiers) can be specified for it in the same way as for DATETIME.
Note that in the INTERVAL consisting only of a SECOND field (INTERVAL SECOND), the SECOND field will have both a leading precision and a seconds precision, specified together.
A seconds precision value between 0 and 9 may be specified for an INTERVAL. If the seconds precision is not specified, a default value of 6 is implied.
A syntactic element, the interval qualifier, is used to specify the interval precision, leading precision and (where appropriate) the seconds precision.
The interval qualifier follows the keyword INTERVAL when specifying an INTERVAL data type.
The following table lists the valid interval qualifiers for YEAR-MONTH intervals:
The following table lists the valid interval qualifiers for DAY-TIME intervals:
Length of an Interval Data Type
The length of an INTERVAL data type is the same as the number of characters required to represent it as a string and is determined by the interval precision, leading precision and the seconds precision (where it applies).
The maximum length of an INTERVAL data type can be computed according to the following rules:
•The length of the most significant field is the leading precision value (p).
•Allow a length of 2 for each field following the most significant field.
•Allow a length of 1 for each separator between fields. Separators occur between YEAR and MONTH, DAY and HOUR, HOUR and MINUTE, and MINUTE and SECOND.
•If seconds precision applies, and is non-zero, allow a length equal to the seconds precision value, plus 1 for the decimal point preceding the fractional part of the seconds value.
BOOLEAN describes a truth value. It can have the values TRUE or FALSE.
The spatial data types can be used for geographical data (longitude, latitude and location), and for coordinate system data (x, y, coordinate).
The following user-defined types are used to store spatial data:
|
Type |
SQL type |
Description |
|---|---|---|
|
BUILTIN.GIS_LATITUDE |
BINARY(4) |
A distinct user-defined type that stores latitude values. |
|
BUILTIN.GIS_LONGITUDE |
BINARY(4) |
A distinct user-defined type that stores longitude values. |
|
BUILTIN.GIS_LOCATION |
BINARY(8) |
A distinct user-defined type that is used to store a location on Earth. It has a latitude and a longitude component. |
|
BUILTIN.GIS_COORDINATE |
BINARY(8) |
This type has an x and a y component in a flat coordinate system. |
See Mimer SQL Programmer's Manual, Spatial Data for a description of the GIS (Geographic information system) functionality.
Universally Unique Identifier (UUID)
The following type can be used for storing universally unique identifier (UUID) data:
|
Type |
SQL type |
Description |
|---|---|---|
|
BUILTIN.UUID |
BINARY(16) |
See Mimer SQL Programmer's Manual, Universally Unique Identifier - UUID for more information.
There is an additional data type supported by Mimer SQL, called the ROW data type, which is used in stored procedures only.
A variable which is declared as having the ROW data type implicitly defines a row value, which is a single construct that has a value which effectively represents a table row.
A row value is composed of a number of named values, each of which has its own data type and represents a column value in the overall row value.
A ROW data type can be defined either by explicitly specifying a number of field-name/data-type pairs or by specifying a number of table columns from which the unqualified names and data types are inherited.
A ROW data type definition can be specified where one of the above data types would normally be used in a variable declaration in a compound statement, see the Mimer SQL Programmer's Manual, The ROW Data Type, for details.
ROW Data Type Syntax
The syntax for defining a ROW data type is:
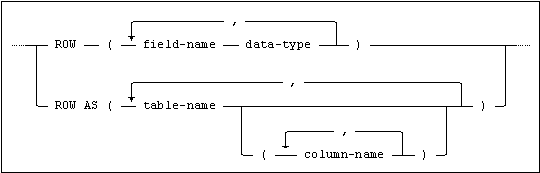
The following points apply to the specification of a ROW data type:
•The value specified for data-type can be a ROW data type specification.
•Two fields in the same ROW data type specification must not have the same name (this restriction applies equally to fields named by specifying a field-name value and those named by inheriting the unqualified name of a table column).
•If table-name is specified without a list of column names, all the columns in the table are used to define fields in the ROW data type.
Note:If a row specification uses the AS clause, any check constraints for the table will not be validated. If a field is declared as using a domain, the same behavior as for a single variable will occur.
Columns which contain an undefined value are assigned a null value.
Depending on the context, this is represented in SQL statements either by the keyword NULL or by a host variable associated with an indicator variable whose value is minus one, see the Mimer SQL Programmer's Manual, Indicator Variables.
The null value is generally never equal to any value, not even to itself. All comparisons involving null evaluate to unknown, see Comparisons.
Note:Null values are treated as equal to each other for the purposes of DISTINCT, GROUP BY, ORDER BY, UNION, INTERSECT, EXCEPT and IS [NOT] DISTINCT FROM.
Null values are sorted at the end of ascending sequences and at the beginning of descending sequences.
Assignment and comparison operations generally require that the data types of the items involved (literals, variables or column values) are compatible but not necessarily exactly equivalent.
Any exceptions to this rule are specified in the detailed syntax descriptions in SQL Statements.
All character data is compatible with all other character data.
Numerical data is compatible with other numerical data regardless of specific data type (integer, decimal or float). Rules for operations involving mixed numerical data types are described in Comparisons.
Datetime and interval data types can be combined in arithmetic operations, for details, see Datetime and Interval Arithmetic.
Values stored in host variables (but not literals or column values) may be converted between character and numerical data types if required by the operation using the variable. The declared type of the variable itself is not altered.
Similarly, character columns may be assigned to numerical variables and vice versa. The rules for data type conversion are given below.
Variables may be converted between different data types by using the CAST function.
Datetime and Interval Arithmetic
The following table lists the arithmetic operations that are permitted involving DATE, TIME, TIMESTAMP (DATETIME) or INTERVAL values:
|
Operand 1 |
Operator |
Operand 2 |
Result Type |
|---|---|---|---|
|
DATETIME |
- |
DATETIME |
(See discussion below) |
|
DATETIME |
+ or - |
INTERVAL |
DATETIME |
|
INTERVAL |
+ |
DATETIME |
DATETIME |
|
INTERVAL |
+ or - |
INTERVAL |
INTERVAL |
|
INTERVAL |
* or / |
NUMERIC |
INTERVAL |
|
NUMERIC |
* |
INTERVAL |
INTERVAL |
Operands can not be combined arithmetically unless their data types are comparable, see Comparisons. If either operand is the null value, then the result will always be the null value.
If an arithmetic operation involves two DATETIME or INTERVAL values with a defined scale, the scale of the result will be the larger of the scales of the two operands.
When an INTERVAL value is multiplied by a numeric value, the scale of the result is equal to that of the INTERVAL and the precision of the result is the leading precision of the INTERVAL increased by 1. In the case of division, the same is true except that the precision of the result is equal to the leading precision of the INTERVAL (i.e. it is not increased by 1).
When two INTERVAL values are added or subtracted, the scale (s) and precision (p) of the result are described by the following rule:
p = min(MLP, max(p'-s', p"-s") + max(s', s") + 1)
s = max(s', s")
where MLP is the maximum permitted leading precision for the INTERVAL type of the result, refer to the table in Interval for these values.
The interval precision of the result is the combined interval precision of the two operands, e.g.
DAY TO HOUR + MINUTE TO SECOND
will produce a DAY TO SECOND result.
One DATETIME value may be subtracted from another to produce an INTERVAL that is the signed difference between the stated dates or times.
The application must, however, specify an INTERVAL date type for the result by using an interval-qualifier.
Thus, the syntax is:
(DATETIME1 - DATETIME2) interval-qualifier
Example:
(DATE '2016-01-09' - DATE '2016-01-01') DAY
This, therefore, evaluates to INTERVAL '8' DAY.
Host Variable Data Type Conversion
When a host variable is used in assignments, comparisons or expressions where the data type of the variable is different from the data type of literals or column declarations, an attempt is made internally to convert the value of the variable to the appropriate type.
Character and Character
Conversion between a character variable and a character value is always allowed. The conversion follows these rules:
•When assigning a character value to a character variable, where the variable is longer than the character value, the variable is padded with trailing blanks.
•When assigning a character value to a character variable, where the value is longer than the variable, the value is truncated and a warning status is returned. If only blanks are truncated, no warning is returned.
•When assigning a variable length character, i.e. a VARCHAR or NCHAR VARYING, column from a character variable, the column is padded with blanks up to the length of the character variable if the column is longer than the variable.
•When assigning a variable length character column from a character variable, where the column is shorter than the variable (except for trailing spaces), the assignment will fail and an error message is returned.
National Character and Character
•When assigning a national character column to a character variable, characters outside the Latin1 character set may occur.
•When assigning a character column to a wide character variable, all characters will be converted to the wide character format.
•When assigning a character column a national character value where characters outside the Latin1 character set occur, the assignment will fail and an error message is returned.
•When assigning a character value to a national character column, the value will be converted to the national character data type.
Numerical and Character
Numerical values may always be converted to character strings, provided that the character string variable is sufficiently long enough. The resulting string format is illustrated below, using n to represent the appropriate number of digits and s to represent the sign position (a minus sign for negative values).
Two digits are always used for the exponent derived from REAL numbers, and three digits are used for all other floating point numbers, regardless of the value of the exponent. The sign of the exponent is always given explicitly (+ or -).
|
Numerical data |
String length |
String format |
|---|---|---|
|
Integer numerical precision p |
p+1 |
'sn' |
|
Exact numerical precision p, scale s |
p+2 |
'sn.n' |
|
REAL |
15 |
'sn.nnnnnnnnEsnn' |
|
DOUBLE PRECISION |
24 |
'sn.nnnnnnnnnnnnnnnnEsnnn' |
|
FLOAT |
24 |
'sn.nnnnnnnnnnnnnnnnEsnnn' |
|
FLOAT(p) |
p+7 |
'sn.nEsnnn' |
Note:Decimal values with scale 0 are converted to strings with the format 'sn.'. Decimal values where the scale is equal to the precision result in strings with the format 's.n'.
Examples of Assignment Results
|
Value |
Type |
Character value |
|---|---|---|
|
1342 |
INTEGER |
'1342' |
|
-15 |
INTEGER |
'-15' |
|
13.42 |
DECIMAL(6,4) |
'13.4200' |
|
-13. |
DECIMAL(5,0) |
'-13.' |
|
.13 |
DECIMAL(2,2) |
'.13' |
|
-1.3E56 |
DOUBLE PRECISION |
'-1.30000000000000E+056' |
Only numerical character strings can be converted to numerical data.
Numerical strings are defined as follows:
•Integer
One optional sign character (+ or -) followed by at least one digit (0-9). Leading and trailing blanks are ignored. No other character is allowed.
•Decimal
As integer, but with one decimal point (.) placed immediately before or after a digit.
•Float
As decimal, but followed directly by an uppercase or lowercase letter E and an exponent written as an integer (optionally signed).
The precision and scale of a number derived from a numerical character string follows the format of the string.
Leading and trailing zeros are significant for assigning precision.
Thus:
|
Numerical value |
Type |
|---|---|
|
3 |
INTEGER(1) |
|
003 |
INTEGER(3) |
|
0.3 |
DECIMAL(2,1) |
|
00.30 |
DECIMAL(4,2) |
|
.3 |
DECIMAL(1,1) |
|
-33 |
INTEGER(2) |
|
-33. |
DECIMAL(2,0) |
|
003.3E14 |
FLOAT(4) |
Standard Compliance
This section summarizes standard compliance concerning data types.
|
Standard |
Compliance |
Comments |
|---|---|---|
|
SQL-2016 |
Core |
Fully compliant. |
|
SQL-2016 |
Features outside core |
Feature F052, “Intervals and datetime arithmetic” support for interval data type. Feature F421, “National character” support for national character data type NCHAR and NCHAR VARYING. Feature F555, “Enhanced seconds precision” support for time and timestamps with fraction of seconds. Feature T021, “BINARY and VARBINARY data types”. Feature T031, “Boolean data type” Feature T041, “Basic LOB data type support” Feature T071, “Bigint data type” |
|
|
Mimer SQL extension |
Conversion between character and numeric when storing values from or retrieving values into host variables is a Mimer SQL extension. Support for the abbreviation NVARCHAR is a Mimer SQL extension. Specifying a precision for INTEGER is a Mimer SQL extension. |
Literal, i.e. fixed data, values may be given for any of the data types supported in SQL statements, wherever the term literal appears in the syntax diagrams.
A string literal may be represented as a character-string-literal, a national-character-string-literal, or a unicode-character-string-literal.
A character-string-literal consists of a sequence of characters enclosed in string delimiters. The standard string delimiter is the single quotation mark: '. Two consecutive single quotation marks within a string are interpreted as a single quotation mark.
If characters outside the ISO 8859-1 character set (Latin1) is included in a character-string-literal, the literal will be considered as a national-character-string-literal.
Note:An empty string (i.e. '') is a defined value. (It is not a null value.)
•National-character-string-literal
A national-character-string-literal consists of a sequence of Unicode characters enclosed in string delimiters and preceded by the optional letter N. (I.e. if the N letter is missing, and the string literal still contains non Latin1 characters, the literal is a national-character-string-literal.)
The standard string delimiter is the single quotation mark: '. Two consecutive single quotation marks within a string are interpreted as a single quotation mark. The case of the preceding N is irrelevant.
Note:An empty string (i.e. N'') is a defined value. (It is not a null value.)
A unicode-string-literal is used in order to facilitate the specification of Unicode characters in an ASCII environment. It consists of a sequence of Unicode characters enclosed in string delimiters and preceded by the letter U and an ampersand, i.e. U&. The standard string delimiter is the single quotation mark: '. Two consecutive single quotation marks within a string are interpreted as a single quotation mark. Unicode characters are given by four hexadecimal digits preceded by a backslash character (\) or, by six hexadecimal digits preceded with a backslash character and a plus character. Two consecutive backslash characters within a string are interpreted as a single backslash character. The case of the preceding U is irrelevant.
Note:An empty string (i.e. U&'') is a defined value. (It is not a null value.)
Character Separators
For character, national-character, unicode and hexadecimal-string-literals, you can use a separator within the literal to join two or more substrings. Separators are described in Special Characters.
This is particularly useful when a string literal extends over more than one physical line, or when control codes are to be combined with character sequences.
Examples
|
String |
Value |
|---|---|
|
'ABCD' |
ABCD |
|
'Mimer''s' |
Mimer's |
|
'data'<LF>'base' |
database |
|
U&'Malm\00F6' |
Malmö |
|
U&'\+01D11E' |
(Musical Symbol G Clef) |
Numerical Integer Literals
A numerical integer literal is a signed or unsigned number that does not include a decimal point. The sign is a plus (+) or minus (-) sign preceding the first digit.
In determining the precision of an integer literal, leading zeros are significant (i.e. the literal 007 has precision 3).
Examples:
47
-125
+006
0
Numerical Decimal Literals
A numerical decimal literal is a signed or unsigned number containing exactly one decimal point.
In determining the precision and scale of a decimal literal, both leading and trailing zeros are significant (i.e. the literal 003.1400 has precision 7, scale 4).
Examples:
4.7
-3.
+012.067
0.0
.370
Numerical Floating Point Literals
Floating point literals are represented in exponential notation, with a signed or unsigned integer or decimal mantissa, followed by an letter E, followed in turn by a signed or unsigned integer exponent.
The base for the exponent is always 10. The exponent zero may be used. The case of the letter E is irrelevant.
In determining the precision of a floating point literal, leading zeros in the mantissa are significant (i.e. the literal 007E4 has precision 3).
Examples:
1.3E5 means 130000
-4e-2 means -0.04
+03.3E2 means 330
0E+45 means 0
1.53E00 means 1.53
REAL, DOUBLE PRECISION and FLOAT Literals
There is no syntax for specifying a REAL, DOUBLE PRECISION or FLOAT literal directly.
Instead use a numerical literal specifying an integer, decimal or floating point value. This value can be cast explicitly to REAL, DOUBLE PRECISION or FLOAT by using a CAST construct. If the literal is used in a position where a REAL, DOUBLE PRECISION or FLOAT value is expected, an implicit CAST is used.
Examples:
INSERT INTO TAB(REALCOL) VALUES (20000001); -- Implicit cast
SET ? = CAST(0.1 as DOUBLE PRECISION); -- Explicit cast
Note that values of type REAL, DOUBLE PRECISION or FLOAT have a binary mantissa. It is not always possible to store the exact decimal value in those types. In such cases the nearest value will be used. In both cases above, the literal value will be silently rounded.
DATE, TIME and TIMESTAMP Literals
A literal that represents a DATE, TIME or TIMESTAMP value consists of the corresponding keyword shown below, followed by text enclosed in single quotes ('').
The following formats are allowed:
DATE 'date-value'
TIME 'time-value'
TIMESTAMP 'date-value <space> time-value'
A date-value has the following format:
year-value – month-value – day-value
A time-value has the following format:
hour-value : minute-value : second-value
where second-value has the following format:
whole-seconds-value [. fractional-seconds-value]
The year-value, month-value, day-value, hour-value, minute-value, whole-seconds-value and fractional-seconds-value are all unsigned integers.
A year-value contains exactly 4 digits, a fractional-seconds-value may contain up to 9 digits and all the other components each contain exactly 2 digits.
Examples:
DATE '2017-02-19'
TIME '10:59:23'
TIMESTAMP '2018-11-05 19:20:23.4567'
TIMESTAMP '2021-12-31 23:59:30'
An interval literal represents an interval value and consists of the keyword INTERVAL followed by text enclosed in single quotes, in the following format:
INTERVAL '[+|-]interval-value' interval-qualifier
The interval-value text must be a valid representation of a value compatible with the INTERVAL data type specified by the interval-qualifier, see Interval Qualifiers.
•If the interval precision includes the YEAR and MONTH fields, the values of these fields should be separated by a minus sign.
•If the interval precision includes the DAY and HOUR fields, the values of these fields should be separated by a space.
•If the interval precision includes the HOUR fields and another field of lower significance (MINUTE and/or SECOND), the values of these fields should be separated by a colon.
•All fields may contain up to 2 digits except that:
•The number of digits in the most significant field must not exceed the leading precision explicitly defined by the interval-qualifier. If a leading precision is not explicitly specified in the interval-qualifier, the default (2) applies.
•The SECOND field may have a fractional part, whose maximum length is defined by the interval-qualifier.
Examples:
INTERVAL '1:30' HOUR TO MINUTE
INTERVAL '1-6' YEAR TO MONTH
INTERVAL '1000 10:20:30.123' DAY(4) TO SECOND(3)
INTERVAL '-199' YEAR(3) **evaluates to -199
INTERVAL '199' YEAR(2) **Invalid : leading precision is 2
INTERVAL '5.555' SECOND(1,2) **evaluates to 5.55
INTERVAL '-5.555' SECOND(1,2) **evaluates to -5.55
INTERVAL '19 23' DAY TO MINUTE **Invalid : no minutes in literal
Binary Literals
A binary literal represents an binary value, and is specified as a hexadecimal string.
A hexadecimal-string-literal is a string specified as a sequence of hexadecimal characters, enclosed in single quotation marks and preceded by the letter X. The sequence must contain an even number of hexadecimal characters (every binary byte is represented by two hexadecimal characters), and may not contain any characters other than the digits 0-9 and the letters A-F. The case of letters (and of the preceding X) is irrelevant.
Note:An empty string (i.e. X'') is a defined value. (It is not a null value.)
Examples:
X'5A65794B697A' -- a binary(6) value
x'f66c' -- a binary(2) value
Boolean literals
A boolean literal represents a truth value. There are two boolean literals, TRUE and FALSE.
Boolean literals can be used when assigning values and making comparisons, e.g.
UPDATE methods SET isConstructor = TRUE WHERE methodName = 'PERSON'
DECLARE v_amountPaid,v_amountDue DECIMAL(10,2);
DECLARE v_isPaid BOOLEAN DEFAULT FALSE;
SET v_isPaid = v_amountPaid >= v_amountDue;
IF v_isPaid IS TRUE THEN
In the last example the comparison with TRUE is not needed. The statement can be written as:
IF v_isPaid THEN
Note:Do not enclose boolean literals in string delimiters. 'TRUE' is a string literal, not a boolean literal.
Spatial literals
The spatial data types are implemented as user-defined types, with functions to create instances, and methods to return the values in different formats. For more information, see Mimer SQL Programmer's Manual, Spatial Data.
Standard Compliance
This section summarizes standard compliance concerning literals.
|
Standard |
Compliance |
Comments |
|---|---|---|
|
SQL-2016 |
Core |
Fully compliant. |
|
SQL-2016 |
Features outside core SQL |
Feature T021, “BINARY and VARBINARY data types”. Feature T031, “BOOLEAN data type”. |
|
|
Mimer SQL extension |
The presence of a newline character (<LF>) between substrings in a character- or hexadecimal-string-literal is not mandatory in Mimer SQL. |
|
|
Mimer SQL extension |
The use of characters outside ISO 8859-1 in a character-string-literal cause them to be considered as a national-character-string-literal. |