In Mimer SQL, the term stored procedures refers to routines, i.e. functions and procedures.
Mimer SQL stored procedures conform to the SQL/PSM standard. The SQL/PSM standard consists of:
•syntax and semantics for variable and cursor declarations
•assignment of the results of expressions to variables and parameters
•conditional statements
•control statements for looping and branching
•condition and exception handling
•getting diagnostics for status information and routine invocations.
Modules can be used to collect a number of routines together as a group.
Mimer SQL PSM Debugger
You can debug routines and triggers using Mimer SQL’s Java-based graphic debugger for PSM routines. The debugger supports watching variables, step-wise execution and setting breakpoints. For more information, see The Mimer SQL PSM Debugger.
A routine is either defined as a function or as a procedure. Essentially the same constructs may be used in both functions and procedures.
A routine can be created by declaring it in a module definition, see Modules, or be created on its own by executing the CREATE FUNCTION or CREATE PROCEDURE statement. A routine created on its own cannot be subsequently added to a module.
A routine belongs to the schema in which it was created and the routine name may be qualified in the normal way with the name of the schema. Only the ident with the same name as the schema to which a routine belongs may refer to it by its unqualified name, all other idents must use the fully qualified routine name.
It is possible to have multiple functions and procedures with the same name within a schema as long as they differ with regard to either the number of parameters or the data type for the parameters. This is called parameter overloading.
To distinguish between routines with the same name it is possible to give a specific name when creating a routine. This specific name can used when granting or revoking execute privilege for the routine or when dropping the routine.
It is possible for a function to have the same qualified name as a procedure, because the invocation of a function is distinct from that of a procedure.
In order to invoke a routine, the ident invoking it must have been granted EXECUTE privilege on the routine. Routines may be recursively invoked.
Note:When routines and modules are created, the create statement must be executed as one single statement. For example, using BSQL, the create statement must be delimited by the @ character, see the Mimer SQL User's Manual, Creating Functions, Procedures, Triggers and Modules, for details and examples.
The following points should be noted for procedures:
•they are invoked by using the CALL statement.
•any result from a procedure must be returned via one of the output parameters, except in the special case of a result set procedure, which can return rows of a result set to a cursor, see Result Set Procedures.
The following points should be noted for functions:
•they are invoked from an SQL statement where a value is required. Certain restrictions apply, see Invoking Functions. For example:
SET :isbn = mimer_store_book.format_isbn('1558604618');
•the parameters of a function provide input only and the function result is returned as the value of the function invocation.
A routine essentially consists of static SQL source that is stored in the data dictionary and which may be invoked by name whenever it is to be executed.
The SQL source for a routine comprises a definition of various routine components, see Syntactic Components of a Routine Definition for details, followed by the routine body.
The routine body consists of a single executable SQL statement - typically a compound SQL statement, i.e. local declarations and a number of SQL statements delimited by a BEGIN and END. See Scope in Routines – the Compound SQL Statement.
Note:It is recommended that a compound SQL statement always be used for the body of a routine, as this offers the greatest flexibility and results in a consistent structure for all routines.
It is possible to declare exception handlers within a compound SQL statement to handle specific exceptions or classes of conditions, see Declaring Exception Handlers.
A function is invoked by specifying the function invocation where a value expression would normally be used. The parameters of a function are used to provide input only, values cannot be passed back to the calling environment through the parameters of a function.
A function always returns a single value and the data type of the return value is defined in the returns clause, which is specified after the parameter definition part of the function definition.
The function returns its value when a RETURN statement is executed within the body of the function. The data type of the value expression in the RETURN statement must be assignment-compatible with the data type specified in the returns clause of the function.
The SQL statements that apply to a function are:
|
Statement |
Description |
|---|---|
|
ALTER FUNCTION |
alters an already existing function, see Mimer SQL Reference Manual, ALTER FUNCTION |
|
CREATE FUNCTION |
creates a function that exists on its own, see the Mimer SQL Reference Manual, CREATE FUNCTION |
|
DROP FUNCTION |
drops a function that exists on its own, see the Mimer SQL Reference Manual, DROP |
|
GRANT EXECUTE |
grants the privilege to invoke a function, see the Mimer SQL Reference Manual, GRANT OBJECT PRIVILEGE |
|
REVOKE EXECUTE |
revokes the privilege to invoke a function, see the Mimer SQL Reference Manual, REVOKE OBJECT PRIVILEGE |
|
COMMENT ON FUNCTION |
defines a comment on a function, see the Mimer SQL Reference Manual, COMMENT. |
Example 1
CREATE FUNCTION SQUARE_INTEGER(p_root INTEGER) RETURNS INTEGER
CONTAINS SQL
BEGIN
RETURN p_root * p_root;
END
Example 2
CREATE FUNCTION mimer_store_web.session_expiration_period()
RETURNS INTERVAL HOUR TO MINUTE
-- Defines the period that a session can be unused
DETERMINISTIC
RETURN INTERVAL '10' MINUTE(3); -- Intentionally very short
Example 3
CREATE FUNCTION date_plus_time (d date, t time(6))
RETURNS timestamp
-- Create a timestamp, from a date plus time input
DETERMINISTIC
RETURN cast(d as timestamp) + (t - time '00:00:00') hour to second(6);
Example 4
CREATE FUNCTION mimer_store_book.keyword_id(p_keyword VARCHAR(48))
RETURNS INTEGER
-- Inserts a word in the KEYWORDS table
-- and returns the identifier with which the keyword is associated
MODIFIES SQL DATA
BEGIN
DECLARE v_keyword_id INTEGER;
DECLARE CONTINUE HANDLER FOR NOT FOUND
BEGIN
INSERT INTO mimer_store_book.keywords(keyword)
VALUES (UPPER(TRIM(p_keyword)));
SET v_keyword_id = CURRENT VALUE FOR mimer_store_book.keyword_id_seq;
END; -- of not found handler
SELECT keyword_id
INTO v_keyword_id
FROM mimer_store_book.keywords
WHERE keyword = TRIM(p_keyword);
RETURN v_keyword_id;
END -- of routine mimer_store_book.keyword_id
A procedure is normally invoked explicitly by executing the CALL statement and does not return a value. The parameters of a procedure can be used to provide input and may be used to pass values back to the calling environment.
There is a special type of procedure, called a result set procedure, which returns rows of a result set to a cursor when it is invoked by executing the FETCH statement in that context.
A result set procedure is distinguished from a normal procedure by having a returns clause specified after the parameter definition part of the procedure definition, see Result Set Procedures for a detailed description of result set procedures.
The SQL statements that apply to a procedure are:
|
Statement |
Description |
|---|---|
|
ALTER PROCEDURE |
alters an already existing procedure, see Mimer SQL Reference Manual, ALTER PROCEDURE |
|
CREATE PROCEDURE |
creates a procedure that exists on its own, see the Mimer SQL Reference Manual, CREATE PROCEDURE |
|
DROP PROCEDURE |
drops a procedure that exists on its own, see the Mimer SQL Reference Manual, DROP |
|
GRANT EXECUTE |
grants the privilege to invoke a procedure, see the Mimer SQL Reference Manual, GRANT OBJECT PRIVILEGE |
|
REVOKE EXECUTE |
revokes the privilege to invoke a procedure, see the Mimer SQL Reference Manual, REVOKE OBJECT PRIVILEGE |
|
CALL |
invokes a procedure, see the Mimer SQL Reference Manual, CALL |
|
COMMENT ON PROCEDURE |
defines a comment on a procedure, see the Mimer SQL Reference Manual, COMMENT. |
Example 1
CREATE PROCEDURE mimer_store_web.delete_basket(p_session_no VARCHAR(16))
-- Deletes expired baskets
MODIFIES SQL DATA
BEGIN
IF p_session_no = '*' THEN
-- '*' indicates that all expired sessions should be deleted
DELETE
FROM mimer_store.orders
WHERE order_id IN (SELECT order_id
FROM mimer_store_web.sessions
WHERE last_accessed < LOCALTIMESTAMP -
mimer_store_web.session_expiration_period());
ELSE
-- Delete the specified session
DELETE
FROM mimer_store.orders
WHERE order_id = (SELECT order_id
FROM mimer_store_web.sessions
WHERE session_no = p_session_no);
END IF;
END -- of routine mimer_store_web.delete_basket
CALL mimer_store_web.delete_basket( '*' );
COMMENT ON PROCEDURE mimer_store_web.delete_basket
IS 'Deletes expired baskets';
DROP PROCEDURE mimer_store_web.delete_basket;
Example 2
CREATE PROCEDURE mimer_store_book.catalogue_authors(IN p_item_id INTEGER,
IN p_authors_list VARCHAR(128))
-- Stores author names as keywords and forms a link between a book
-- and the keywords
MODIFIES SQL DATA
BEGIN
DECLARE v_author VARCHAR(50);
DECLARE v_authors VARCHAR(130);
DECLARE v_offset, v_length INTEGER;
SET v_authors = REPLACE(' ' || p_authors_list || ' ', ' and ', ';');
SET v_authors = REPLACE(v_authors, ' & ', ';');
SET v_authors = TRIM(v_authors);
extract_authors:
LOOP
IF v_authors = '' THEN LEAVE extract_authors; END IF;
SET v_offset = POSITION(';' IN v_authors);
IF v_offset <> 1 THEN
IF v_offset = 0
OR v_offset > 49 THEN
SET v_length = 48;
ELSE
SET v_length = v_offset - 1;
END IF;
SET v_author = mimer_store_book.authors_name(
SUBSTRING(v_authors FROM 1 FOR v_length));
BEGIN
DECLARE v_keyword_id INTEGER;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
-- Ignore all SQL errors
END; -- of sqlexception handler
SET v_keyword_id = mimer_store_book.keyword_id(v_author);
INSERT INTO mimer_store_book.authors(keyword_id, item_id)
VALUES (v_keyword_id, p_item_id);
END;
END IF;
IF v_offset = 0 THEN LEAVE extract_authors; END IF;
SET v_authors = TRIM(SUBSTRING(v_authors FROM v_offset+1));
END LOOP extract_authors;
END -- of routine mimer_store_book.catalogue_authors
Syntactic Components of a Routine Definition
The following sections discuss parameters, language indicators, clauses, scope, variables and data types when working with routines.
A routine may have zero or more parameters and each parameter must have a name and a data type specified.
Each parameter of a procedure can have an optional mode specification (IN, OUT or INOUT – see CREATE PROCEDURE in the Mimer SQL Reference Manual for details). When the mode is not explicitly specified, IN is assumed by default.
It is not possible to specify the mode for the parameters of a function (they always have the default mode, IN).
A parameter name must be unique within the routine. The parameter name can be up to 128 characters in length, see the Mimer SQL Reference Manual, Naming Objects, for further details about naming SQL objects.
The parameter data type can be any data type supported by Mimer SQL, except any of the large object types, see the Mimer SQL Reference Manual, Data Types in SQL Statements.
A parameter name may be referenced in an unqualified manner throughout a routine, at all scope levels – see Scope in Routines – the Compound SQL Statement for a discussion of scope in routines.
Examples:
CREATE FUNCTION onefunction(a INTEGER, b DECIMAL(5,2))
RETURNS DECIMAL(5,2)
BEGIN
...
END
CREATE PROCEDURE lookup(IN i INTEGER, OUT retval VARCHAR(20))
BEGIN
...
END
Mimer SQL supports the possibility to define multiple functions or procedures with the same name as long as they differ with regard to the number of parameters or the data type of the parameter. It is not possible to have multiple functions that only differ with regard to the return data type.
As an example, it is possible to create two functions like
SQL>create function f(c1 char) returns int return 1;
SQL>create function f(c1 integer) returns int return 2;
and these can be used as
SQL>set ? = f('1');
?
===========
1
SQL>set ? = f(1);
?
===========
2
In this case there is no problem deciding which routine that should be invoked in the two cases since there can be no implicit conversion from a character type to integer or vice versa. Some interesting cases arise when there are parameter overloading and where there are implicit conversions between the parameter types. For instance, if we have these functions
SQL>create function f(p char varying(2))
SQL& returns int return 1;
SQL>create function f(p nchar varying(2))
SQL& returns int return 2;
Given the statement
SQL>set ? = f('a');
which routine should be invoked? The data type of the actual argument is char and there is no routine with a parameter list that matches the invocation exactly. In this case a type precedence list is used to determine the proper subject routine. For CHAR the type precedence list is CHAR, CHARACTER VARYING, NCHAR and NCHAR VARYING which means that the function returning 1 will be chosen in this case. If there are multiple parameters, the subject routine is determined by evaluating the type precedence list for each parameter, going from left to right.
The type precedence lists are found in Mimer SQL Reference Manual, Type Precedence Lists.
Specific Names and Parameter List
When specifying a routine in a drop, grant or revoke statement the routine must be uniquely identifiable. This is no problem as long as parameter overloading is not used. If there are multiple functions or procedures with the same name there are two ways of specifying a unique routine. The first is by using the specific name for the routine. A specific name can be defined when the routine is created. If no specific name is given, a unique name is generated automatically. This name can be seen in the view INFORMATION_SCHEMA.ROUTINES. As an example:
CREATE PROCEDURE p(p1 INT, p2 CHAR(20))
SPECIFIC p_int_char
…
GRANT EXECUTE ON SPECIFIC PROCEDURE p_int_char
TO public WITH GRANT OPTION;
The other way to distinguish between overloaded routines in DDL statements is to use a data type list. Given the above procedure definition, the grant statement can be written as
GRANT EXECUTE ON PROCEDURE p(INT,CHAR) TO public WITH GRANT OPTION;
To specify a routine without parameters, the syntax is
GRANT EXECUTE ON PROCEDURE p() TO public WITH GRANT OPTION;
Routine Parameters and Null Values
All parameters accept null values. Use CAST to invoke a routine with a null value as a parameter, as follows:
CALL mimer_store_music.AddTrack(718751799622, CAST(NULL AS int), 'Null Set', '3:53')
Routine Language Indicator
The language indicator specifies the language of the routine. Currently, the only language name supported is SQL.
If no language indicator is specified, LANGUAGE SQL is assumed by default.
The deterministic clause for a routine can specify NOT DETERMINISTIC or DETERMINISTIC. If a deterministic clause is not specified, NOT DETERMINISTIC is assumed by default.
A DETERMINISTIC routine is one that is guaranteed to produce the same result every time it is invoked with the same set of input values.
Therefore, a DETERMINISTIC routine may not contain a reference to: CURRENT_DATE, LOCALTIME, LOCALTIMESTAMP or BUILTIN.UTC_TIMESTAMP.
Specifying a routine to be DETERMINISTIC allows repeated invocations of it to be optimized.
The access clause for a routine specifies which SQL statements are permitted within the routine.
The three different options for the routine access clause (CONTAINS SQL, READS SQL DATA and MODIFIES SQL DATA) are described under CREATE PROCEDURE in the Mimer SQL Reference Manual. If no routine access clause is specified, then CONTAINS SQL is assumed.
If the routine contains a SELECT statement, READS SQL DATA is required. (Or if a READS SQL DATA routine is called.)
If the routine contains a DELETE or an UPDATE statement, MODIFIES SQL DATA is required. (Or if a MODIFIES SQL DATA routine is called.)
Scope in Routines – the Compound SQL Statement
A compound SQL statement allows a sequence of procedural SQL statements to be considered as a single SQL statement, see COMPOUND STATEMENT in the Mimer SQL Reference Manual for a description of the syntax.
A routine body may contain only one executable SQL statement and the compound SQL statement allows a routine to be defined that can actually contain any number of SQL statements.
A compound SQL statement also defines a local scope in which variables, exception handlers, and cursors can be declared. Compound SQL statements may be nested, one within the other, and thus local scopes may be nested.
A compound SQL statement may be labeled, which effectively names the local scope defined by it. The label name can be used whenever the scope environment needs to be referred to explicitly, e.g. when qualifying the names of objects which have been declared in the compound SQL statement. The label name must not be the same as a routine name.
It is important to understand the effect of scoping on declared items, particularly with respect to: out-of-scope references to variables, see Declaring Variables, the scope within which an exception handler remains in effect and the flow of control effects following the use of different types of exception handler, see Declaring Exception Handlers.
The SQL statement LEAVE is specifically provided to give the programmer the ability to force the flow of control to exit from a labeled scope.
Example
CREATE PROCEDURE some_procedure(INOUT y INTEGER)
CONTAINS SQL
s0:
BEGIN
...
s1:
BEGIN
IF y < 0 THEN
SET y = 0;
LEAVE s0;
END IF;
...
END s1;
...
END s0
In the example above, the effect of the LEAVE statement is to pass flow of control to the statement END s0, i.e. flow of control exits from the scope labeled s0.
All open cursors declared in a compound SQL statement are closed whenever flow of control leaves the compound SQL statement for any reason.
Note:A compound SQL statement may be preceded by a label which names the scope delimited by the BEGIN and END (this is called the beginning label). Specifying the label next to the END is optional. However, if a label is specified next to the END, the beginning label must be specified.
The ATOMIC Compound SQL Statement
The execution of any SQL statement, other than a procedure-control-statement, is atomic. See the Mimer SQL Reference Manual, Procedural SQL Statements, for a definition of a procedure-control-statement.
The execution of a compound SQL statement defined as ATOMIC is also atomic.
When the execution of an SQL statement is atomic, an atomic execution context becomes active while the statement, or any contained subquery, is executing. While an atomic execution context is active, it is possible for another atomic execution context to become active within it.
While an atomic execution context is active the following is true:
•It is not possible to explicitly terminate a transaction, thus all changes made within the atomic execution context occur within the same transaction.
•If an exception occurs during the execution of a statement and there is an undo handler declared for this exception, then all delete, insert and update statements executed within the atomic compound statement are undone. If there is no undo handler, only the statement that caused the exception will be undone.
Note:If the atomic statement contains operations on tables located in a databank defined with work option, these operations will not be part of the atomic statement but will be executed immediately. If the atomic statement is terminated by an SQL exception, such operation will not be undone.
An atomic compound SQL statement is defined by specifying the keyword ATOMIC next to the BEGIN delimiter. The COMMIT and ROLLBACK statements cannot be used within an atomic compound SQL statement.
A compound SQL statement is explicitly defined as not being atomic by specifying NOT ATOMIC next to the BEGIN delimiter. If nothing is specified next to the BEGIN delimiter, NOT ATOMIC is assumed by default.
If the compound SQL statement contains a declaration for an UNDO exception handler, see Declaring Exception Handlers, the compound SQL statement must be ATOMIC.
Examples:
CREATE FUNCTION an_atomic_function(i INTEGER)
RETURNS INTEGER
BEGIN ATOMIC
...
-- All statements executed between this BEGIN
-- and END execute within the same active atomic
-- execution context.
-- UNDO exception handlers are permitted.
-- No COMMIT or ROLLBACK allowed!
...
END
CREATE PROCEDURE a_non_atomic_procedure(i INTEGER)
BEGIN NOT ATOMIC
...
-- This compound SQL statement is not atomic.
-- COMMIT and ROLLBACK statements are permitted.
-- No UNDO exception handlers allowed!
...
END
CREATE FUNCTION a_default_function(i INTEGER) RETURNS INTEGER
BEGIN
...
-- This compound SQL statement is not atomic, by default.
-- COMMIT and ROLLBACK statements are permitted.
-- No UNDO exception handlers allowed!
...
END
It is possible to declare variables, cursors, condition names and exception handlers at the beginning of a compound SQL statement. These items can, therefore, be declared in a routine when a compound SQL statement is used for the routine body.
This section discusses the declaration of variables. Discussions about declaring the other items mentioned above can be found in the following sections:
•cursors, see Using Cursors
•condition names, see Declaring Condition Names
•exception handlers, see Declaring Exception Handlers.
Variables of any data type supported by Mimer SQL may be declared. The name of a variable must be unique within the scope of its declaration and must not conflict with the name of any of the routine parameters.
Variable names can be a maximum of 128 characters in length and are case insensitive. See the Mimer SQL Reference Manual, Naming Objects, for further details.
More than one variable of the same type can be declared in a single variable declaration, see the examples below.
It is possible to specify an optional expression, which may be null, that defines the default value for a variable declaration. The variable(s) created by the variable declaration are given the initial value derived from the default expression. If a default expression is not specified, the value null is assumed.
Examples:
DECLARE z INTEGER;
DECLARE x, y INTEGER DEFAULT 9;
DECLARE abx VARCHAR(50);
DECLARE a INTEGER DEFAULT NULL;
Note:It is possible to declare a variable that has the same name as a column name in a table. All ambiguous references will be interpreted as a reference to a column name rather than a variable. It is therefore recommended that a suitable naming convention be adhered to that clearly distinguishes between the names of table columns and variables.
The name of a variable may be qualified in the normal way with the beginning label of the scope in which it has been declared.
Example
CREATE PROCEDURE some_procedure(IN x INTEGER)
s0:
BEGIN
DECLARE a, b INTEGER;
s1:
BEGIN
DECLARE b, c INTEGER;
...
END s1;
s2:
BEGIN
DECLARE y INTEGER;
...
END s2;
END s0
The qualified names for the variables in the preceding example are as follows:
s0.a, s0.b, s1.b, s1.c and s2.y.
Mimer SQL supports a data type called the ROW data type. It can be used in a compound SQL statement in place of the data type specified when a variable is declared.
A variable that is declared as having the ROW data type implicitly defines a row value, which is a single construct that has a value that effectively represents a table row.
A row value is composed of a number of named values, each of which has its own data type and represents a column value in the overall row value.
A ROW data type can be defined either by explicitly specifying a number of field-name/data-type pairs or by specifying a number of table columns from which the unqualified names and data types are inherited.
ROW Data Type Syntax
The syntax for defining a ROW data type is:
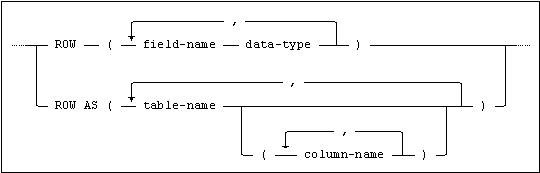
The following points apply to the specification of a ROW data type:
•A domain cannot be specified for data-type.
•The value specified for data-type can be a ROW data type specification.
•Two fields in the same ROW data type specification must not have the same name (this restriction applies equally to fields named by specifying a field-name value and those named by inheriting the unqualified name of a table column).
•If table-name is specified without a list of column names, all the columns in the table are used to define fields in the ROW data type.
Using the ROW Data Type
A ROW variable field is referenced like this: variable-name.field-name.
A value may be assigned to one of the fields in a ROW variable in the same way as a value would be assigned to a variable declared with the same data type as the field. The data type of the field must be assignment compatible with the value being assigned to it.
If the declaration of a ROW variable does not include a DEFAULT clause, each field in the ROW variable is set to null initially.
The value of a field in a ROW variable may be used in the same way as any value of that type.
When a ROW data type is defined by specifying table columns, the names and data types of its fields are inherited from the columns in the table(s). Subsequently assigning values to the ROW variable will not affect the table(s) used to define the ROW data type.
A row value, which may be the value of a ROW variable, may be assigned to a ROW variable. The row value and the ROW variable are assignment-compatible if, and only if, both contain the same number of values and each value in the row value is assignment-compatible with the corresponding field in the ROW variable.
Two row values, one or both of which may be the value of a ROW variable, may be compared. The row values are comparison-compatible if, and only if, both contain the same number of values and each value in one is comparison-compatible with the corresponding value in the other.
A ROW variable may be used within a compound SQL statement in the following contexts:
•As the only expression specified in a RETURN statement used in a result set procedure. The ROW variable must be assignment-compatible with the row value defined by the procedure VALUES clause.
•As the only target variable specified in the INTO clause of a SELECT INTO statement. The row value selected must be assignment-compatible with the ROW variable and will be assigned to it.
•As the only target variable specified in the INTO clause of a FETCH statement. The row value fetched must be assignment-compatible with the ROW variable and will be assigned to it.
•As the procedure-variable or expression in a SET assignment statement (see the description above of assignment-compatibility involving ROW variables).
•As an argument in a comparison (see the description above of comparison-compatibility involving ROW variables).
A row value expression is an expression that specifies a row value. The values that represent the column values of the row value expression are specified as value expressions in a comma-separated list that is delimited by parentheses.
A row value expression can be used in the following contexts:
•As the only expression in a RETURN statement used in a result set procedure.
•As the expression following the DEFAULT keyword in a DECLARE VARIABLE statement for a variable declared to have the ROW data type.
•As a row value in a comparison or assignment operation.
Examples:
RETURN (24, 16, 'xyz', 11.3, x+4/9);
DECLARE rc ROW (a INTEGER, b INTEGER, s VARCHAR(10))
DEFAULT (14, 27, 'hello');
IF rc = (14, 27, 'hello') THEN
SET rc.s = 'bye';
END IF;
SET rc = (99, 105, 'new value');
A module is a collection of routines. All the routines in a module are created by declaring them when the module is created. Routines cannot be added to or removed from a module after the module has been created.
A module belongs to the schema in which it is created and all the routines contained in a module must belong to the same schema as the module.
The name of a routine in a module may be qualified in the normal way by using the name of the schema to which the routine belongs. The module name is never used to qualify the name of a routine.
Note:It is not possible to grant EXECUTE privilege on a module. In order to allow an ident to invoke a routine, whether it exists on its own or in a module, EXECUTE privilege on the routine must be granted to the ident.
When a module is dropped, all the routines in the module will be dropped as well. See Using DROP and REVOKE for a discussion of CASCADE effects on modules and routines.
The operations that may be performed on a module are:
•CREATE MODULE
•DROP MODULE
•COMMENT ON MODULE
Refer to the Mimer SQL Reference Manual, SQL Statements for a description of the SQL statements mentioned above, brief examples follow.
Examples:
CREATE MODULE module_1
DECLARE PROCEDURE p1 ... ;
DECLARE PROCEDURE p2 ... ;
DECLARE FUNCTION f1 ... ;
...
END MODULE
COMMENT ON MODULE module_1 IS 'This is my example module';
DROP MODULE module_1 CASCADE;
The following SQL constructs are specifically provided for use in the body of a routine.
The SET statement is used to assign a value to a variable declared in a routine or an output parameter of a procedure (i.e. a parameter with mode OUT or INOUT).
Examples:
SET a = 5;
SET x = NULL;
SET y = 11 + a;
SET d = CURRENT_DATE;
SET z = NEXT VALUE FOR Z_SEQUENCE;
SET (x, y) = (CASE y WHEN 1 THEN y ELSE 0 END, 64);
Conditional Execution Using IF
The IF statement provides a mechanism for conditional execution of SQL statements based on the truth value of a conditional expression.
Note:If the conditional expression includes (or equals) null, the conditional expression evaluates to false. Testing for the null value must be done by using IS NULL, see the Mimer SQL Reference Manual, The NULL Predicate.
A basic IF statement consists of a conditional expression followed by a list of one or more SQL statements in a THEN clause, which are executed if the conditional expression evaluates to true and, optionally, a list of one or more SQL statements in an ELSE clause which are executed if the conditional expression evaluates to false.
All of the predicates supported by Mimer SQL are allowed in the conditional expression of an IF statement – see the Mimer SQL Reference Manual, Predicates.
One or more IF statements can be nested, one within the other, by using an ELSEIF clause in place of the ELSE clause in the IF statement containing another.
The IF statement does not in any sense define a local scope, it is simply a mechanism for conditionally executing a sequence of SQL statements.
Once the SQL statements to be executed have been selected, they execute in the same way as any ordinary sequence of SQL statements. This point is particularly important when considering exception condition handling behavior, see Managing Exception Conditions.
Examples:
IF x > 50 THEN
SET x = 50;
SET y = 1;
ELSE
SET y = 0;
END IF;
IF y IN (2,3,4) THEN
...
ELSE
...
END IF;
IF x > 50 THEN
SET x = 50;
SET y = 2;
ELSEIF x > 25 THEN
SET y = 1;
ELSE
SET y = 0;
END IF;
IF NOT EXISTS (SELECT *
FROM table_1) THEN
...
ELSE
...
END IF;
IF X > (SELECT c1
FROM t1
WHERE ... ) THEN
...
ELSE
...
END IF;
Conditional Execution – the CASE Statement
The CASE statement provides another mechanism for conditional execution of SQL statements. The CASE statement comes in two forms, a simple case and a searched case.
Simple Case
A simple case works by evaluating equality between one value expression and one or more alternatives of a second value expression. For example:
DECLARE y INTEGER;
CASE y
WHEN 1 THEN ...
WHEN 2 THEN ...
WHEN 3 THEN ...
ELSE ...
END CASE;
Searched Case
A searched case works by evaluating, for truth, a number of alternative search conditions. For example:
CASE
WHEN EXISTS (SELECT *
FROM BILL) THEN ...
WHEN x > 0 OR y = 1 THEN ...
ELSE ...
END CASE;
About Case Statements
For both forms of the CASE statement the following is true:
•A sequence of one or more SQL statements can follow the THEN clause for each of the conditional alternatives, in the same way as for an IF statement, even though only a single implied SQL statement is shown in the examples above.
•Each alternative sequence of SQL statements in a CASE statement is treated in the same way, with respect to the behavior of exception handlers etc., as has already been described for sequences of SQL statements in an IF statement, see Conditional Execution Using IF.
•Like the IF statement, the CASE statement simply provides a mechanism for selecting a sequence of SQL statements to execute. The CASE statement as a whole is not considered, in any sense, to be a single statement.
•The conditional part of each WHEN clause is evaluated, working from the top of the CASE statement down. The SQL statements that are actually executed are those following the THEN clause of the first WHEN condition to evaluate to true. If none of the WHEN conditions evaluate to true, the SQL statements following the CASE statement ELSE clause are executed.
The presence of an ELSE clause in the CASE statement is optional and if it is not present (and none of the WHEN conditions evaluate to true) an exception condition is raised to indicate that a case was not found for the CASE statement.
Note:If it is desired that there be no operation performed and no exception condition raised if none of the WHEN conditions evaluate to true, then an ELSE clause should be specified as an empty compound SQL statement.
Only the single selected sequence of SQL statements that follow a THEN or the ELSE is executed before the CASE statement terminates. There is no potential fall-through to subsequent THEN sequences as is found in case statements in some other programming environments.
Note:The CASE statement is distinct from the CASE expression – see the Mimer SQL Reference Manual, CASE and Mimer SQL Reference Manual, CASE Expression.
The following sections describe how you can use iteration.
Iterating through a result set - FOR loop
A for loop can be used to iterate through all records in a result set and perform some operations for each record. This is a vast simplification compared to using a cursor.
A simple example of a for loop is
FOR SELECT surname, forname FROM customers
WHERE customer_id IN
(SELECT customer_id FROM orders
WHERE datetime BETWEEN DATE '2006-01-01' AND DATE '2006-06-31') DO
CALL orderStat(surname,forname);
END FOR
I.e. call the orderStat routine for each record in the customers table that fulfil the where criteria. Within the body of the for statement it is possible to reference the column values as ordinary variables. This also means that each item in the select list must have a name and that name must be unique within the select list.
The body of the for statement is an atomic statement, which means that it cannot contain statements such as start, commit and rollback.
It is possible to use a result set procedure in a for loop
FOR CALL coming_soon('Blues') DO
IF producer IN ('Bill Vernon','Bill Ham') THEN
INSERT INTO stats(format,release_date,…)
VALUES (format,release_date,…);
END IF;
END FOR
In this case the correlation names in the returns clause of the result set procedure definition can be used as variable names in the body of the for loop.
The select or call statement in the for loop can be labelled and this label can be used to qualify variable references.
l1: BEGIN
DECLARE forname CHAR(12);
…
FOR l2 AS SELECT forname FROM customers DO
IF l1.forname <> l2.forname THEN
…
END IF;
END FOR;
END
The label used cannot be the same as any label of a compound statement enclosing the for loop.
The LOOP statement may be preceded by a label that can be used as an argument to LEAVE in order to terminate the loop. The LOOP statement can contain a sequence of one or more SQL statements that are executed, in order, repeatedly.
The iteration is terminated by executing the LEAVE statement, or if an exception condition is raised.
Example
s1:
LOOP
...
IF ecounter > 10000 THEN
LEAVE s1;
END IF;
END LOOP s1;
The WHILE statement may be preceded by a label that can be used as an argument to LEAVE in order to terminate the while loop. The WHILE statement can contain a sequence of one or more SQL statements that are executed, in order, repeatedly.
The WHILE statement includes a conditional expression and iteration continues as long as this expression evaluates to true. Iteration may also be terminated by executing the LEAVE statement, or if an exception condition is raised.
Example
SET i = 0;
s1:
WHILE i <= 10 DO
...
SET i = i + 1;
END WHILE s1;
The REPEAT statement may be preceded by a label that can be used as an argument to LEAVE in order to terminate the repeat loop. The REPEAT statement can contain a sequence of one or more SQL statements which are executed, in order, repeatedly.
The REPEAT statement includes an UNTIL clause, which specifies a conditional expression, and iteration continues until this expression evaluates to true. Iteration may also be terminated by executing the LEAVE statement, or if an exception condition is raised.
Example
SET i = 0;
s1:
REPEAT
...
SET i = i + 1;
UNTIL i > 10
END REPEAT s1;
Using ITERATE to Skip Statements
You can use an ITERATE statement to skip the remaining statements in an iteration as shown in the following examples:
SET x = 0:
s1:
REPEAT
SET x = x + 1;
...
IF x < 10 THEN
ITERATE s1; -- execution continues at the beginning
-- of the repeat statement
END IF;
...
UNTIL x = 20 END REPEAT s1;
Using ITERATE in all Iteration Statements
You can use ITERATE in all iteration statements in stored procedures. ITERATE is not restricted to the innermost statement. For example:
SET x = 0;
s1:
REPEAT
SET x = x + 1;
s2:
BEGIN
s3:
LOOP
...
IF x < 10 THEN
ITERATE s1;
ELSEIF x < 20 THEN
ITERATE s3;
END IF;
...
END LOOP s3;
END s2;
UNTIL x = 20
END REPEAT s1;
Note:The statement ITERATE s1 will cause an implicit leave of the compound statement labeled s2.
Invoking Procedures and Functions
The following sections discuss invoking procedures and functions.
The CALL statement is used to invoke a procedure. The name of the procedure may be qualified with the name of the schema to which it belongs. A value expression or target variable must be specified for each of the procedure’s parameters, see the Mimer SQL Reference Manual, Target Variables, for the definition.
If the procedure parameter has mode OUT or INOUT, a target variable must be specified. For procedure parameters with mode IN, a value expression may be specified.
SQL/PSM is not strongly typed, so the expression specified for each procedure parameter need not have exactly the same data type as the parameter, however the expression must be assignment-compatible with the procedure parameter for which it is supplied, see the Mimer SQL Reference Manual, Assignments, for a discussion of assignment and implicit data type conversions.
Examples:
CALL PROC1( );
CALL PROC2(x, y);
CALL IDENT1.PROC7(CURRENT_DATE, x+3, z);
Functions are not invoked by calling them explicitly. A function is invoked, and it returns its value, when it is used in a procedure-control-statement or in an assignment where a value-expression would normally be used.
The name of the function may be qualified with the name of the schema to which it belongs.
If MODIFIES SQL DATA has been specified for the access-clause of the function, it must not be used in the expression following the DEFAULT keyword in a DECLARE VARIABLE statement.
Examples:
IF fn(x) > 70 THEN
...
ELSE
...
END IF;
SET v_Artist = Mimer_Store_Music.ArtistName(p_RecordedBy) || '%';
IF Mimer_Store.Index_Text(Data.Title) LIKE v_Title THEN
...
END IF;
Any text that occurs after -- and before end-of-line in a routine is taken to be a comment.
Example
CREATE PROCEDURE tstproc(y INTEGER)
-- This is a comment: Note that Y has mode IN (default)
READS SQL DATA
BEGIN
DECLARE b INTEGER;
-- Here is another comment
SET b = y + 22; -- Y is input to the procedure
...
END
The following groups of SQL statements may not be used in a routine:
•Access Control statements
•Data Definition statements
•Connection statements
•ESQL Control statements
•Security Control statements
•Dynamic SQL statements
•System Administration statements.
Refer to the Mimer SQL Reference Manual, SQL Statements for a definition of the statement groups mentioned above.
Note:Any SQL statements used in a routine must be executable, so the usual restriction on the use of SELECT versus SELECT INTO applies (only the latter being considered executable - the former may, however, be used in a conditional expression, e.g. in an IF statement or a cursor declaration).
The following restrictions apply to result set procedures:
•A COMMIT or ROLLBACK statement must not be executed in a result set procedure because it will interfere with the open cursor that will exist in the context from where the result set procedure is called.
•A function or procedure that executes a COMMIT or ROLLBACK statement must not be invoked from within a result set procedure.
•A function or procedure that has MODIFIES SQL DATA specified for its access clause must not be invoked from within a result set procedure.
The following sections discuss how to use write operations, cursors and SELECT INTO when manipulating data.
You can use INSERT, UPDATE and DELETE statements in a function or procedure provided MODIFIES SQL DATA has been specified for the access clause, see Routine Access Clause.
You can use routine parameters and variables in these statements wherever an expression can normally be used, as shown in the examples below.
Example
CREATE PROCEDURE mimer_store_book.add_title(IN p_book_title VARCHAR(48),
IN p_authors VARCHAR(128),
IN p_published_by VARCHAR(48),
IN p_format VARCHAR(20),
IN p_isbn CHAR(18),
IN p_date_released CHAR(10),
IN p_price DECIMAL(7, 2),
IN p_stock SMALLINT,
IN p_reorder_level SMALLINT)
-- Add the details for a book entity; inserts against the join view which fires
-- the instead of trigger
MODIFIES SQL DATA
BEGIN
-- Insert into join view
INSERT INTO mimer_store_book.details(title, authors_list, publisher,
format,isbn, release_date,
price, stock, reorder_level)
VALUES (p_book_title, p_authors, p_published_by, p_format,
p_isbn, p_date_released, p_price, p_stock,
p_reorder_level);
END -- of routine mimer_store_book.add_title
You can use the ROW_COUNT option of the GET DIAGNOSTICS statement may be used immediately after an INSERT, UPDATE, DELETE, SELECT INTO or FETCH statement to determine the number of rows affected by the preceding statement.
Example
DECLARE v_rows INTEGER;
...
INSERT INTO mimer_store_book.details ...;
GET DIAGNOSTICS v_rows = ROW_COUNT;
IF v_rows > 0 THEN
Note:All SQL statements except GET DIAGNOSTICS will overwrite the information in the diagnostics area.
You can declare and use cursors in a compound SQL statement to receive a result set from a select-expression or from a result set procedure.
A cursor may not have the same name as another cursor declared in the same scope.
Cursors in a procedural usage context are used in much the same way, in terms of the SQL statements used, as cursors declared outside routines. It is possible to open cursors, fetch data into variables and use the statements UPDATE and DELETE WHERE CURRENT OF cursor.
Example 1
DECLARE NREC ROW AS (SOMETABLE);
DECLARE C CURSOR FOR SELECT * FROM SOMETABLE;
BEGIN
DECLARE EXIT HANDLER FOR NOT FOUND CLOSE C;
OPEN C;
LOOP
FETCH C INTO NREC;
...
END LOOP;
END;
Example 2
DECLARE D DATE DEFAULT CURRENT_DATE;
DECLARE C1,C2 CHAR(5);
DECLARE Z SCROLL CURSOR FOR CALL PROC(1,D);
DECLARE I INTEGER;
...
OPEN Z;
...
FETCH FIRST FROM Z INTO C1;
...
FETCH ABSOLUTE I FROM Z INTO C2;
FETCH ABSOLUTE I FROM Z INTO C2;
Example 1 demonstrates detection of the NOT FOUND exception as a method of detecting that a FETCH statement does not return any data. If a NOT FOUND exception occurs in the example, an exit handler is invoked. After the exit handler has finished, the flow of control leaves the compound SQL statement.
Alternatively, the GET DIAGNOSTICS statement can be used to retrieve the number of rows affected by the FETCH statement, as shown below.
Example
DECLARE ROWS INTEGER;
L1:
LOOP
FETCH X INTO I_CHARGE_CODE,I_AMOUNT;
GET DIAGNOSTICS ROWCNT = ROW_COUNT;
IF ROWCNT = 0 THEN
LEAVE L1;
END IF;
END LOOP;
CLOSE X;
The following specific restrictions apply to cursors used in routines:
•no dynamic functions can be used (i.e. extended cursor names and the use of SQL descriptors)
•REOPENABLE cursors are not allowed
•the use of the keyword RELEASE with the CLOSE statement is not permitted.
Using FETCH to get result set data from a result set procedure may cause parts of the result set procedure to execute, see Result Set Procedures. The result set procedure will be in use until the associated cursor is closed.
Another way of fetching data is by using a SELECT INTO statement. This can only be used when one single row is fetched from the database. If more than one row fulfills the search criteria, an exception condition is raised. If no data is found, a not found condition is raised.
Example
SELECT currency, v_price * exchange_rate
INTO p_local_currency, p_local_price
FROM mimer_store.customers
JOIN mimer_store.countries AS cnt ON cnt.code = country_code
JOIN mimer_store.currencies AS crn ON crn.code = currency_code
FETCH 1;
Transactions
It is possible to start and end transactions within a routine. A transaction is implicitly started when a routine that accesses the database is invoked.
It is also possible to explicitly start a transaction by using the START statement. When a transaction is ended, either by a COMMIT or ROLLBACK statement, all open cursors are closed.
Example
START;
UPDATE table
SET ...
WHERE col = v_str, ...
...
COMMIT;
It is possible to affect the behavior of transactions by using the SET TRANSACTION and SET SESSION statements.
Note:If a compound SQL statement is defined as ATOMIC, a transaction cannot be terminated within it because execution of the COMMIT or ROLLBACK statements is not permitted.
A result set procedure is a special type of procedure that allows a result set to be returned.
A result set procedure is called by specifying it in a cursor declaration and then using FETCH to get the result set data.
In interactive SQL, a result set procedure is called by using the CALL statement and the result set data is dealt with in the same way as a select.
Example (ESQL):
EXEC SQL DECLARE c_1 CURSOR FOR CALL result_proc(1, 5);
A result set procedure is distinguished when it is created or declared by a RETURNS clause which follows the parameter part of the procedure definition.
The RETURNS clause defines the data types of the columns in the result set and may contain an AS clause which names the columns.
Example
CREATE PROCEDURE barcode(IN p_ean BIGINT)
-- result set procedure that returns book or music details for the given EAN
RETURNS TABLE(title VARCHAR(48), creator VARCHAR(48), format VARCHAR(20), priced decimal(7,2), item_id INTEGER)
READS SQL DATA
BEGIN
...
END
All result set procedure parameters have mode IN, therefore, any data returned from a result set procedure is returned via the procedure’s result set.
The option MODIFIES SQL DATA must not be specified for the access clause of a result set procedure, see Routine Access Clause.
Note:A function or procedure that has MODIFIES SQL DATA specified for its access clause must not be invoked from within a result set procedure.
A result set procedure must not execute a COMMIT or ROLLBACK statement, because this would close the cursor that is used in order to call the result set procedure.
Note:A function or procedure that executes a COMMIT or ROLLBACK statement must not be invoked from within a result set procedure.
A row in the result set of a result set procedure is returned by executing the RETURN statement. The arguments to a RETURN statement can be null, an expression or a variable which has the ROW data type.
When a FETCH is executed, the SQL statements in the body of the result set procedure are executed until a RETURN statement is executed.
The execution of the result set procedure is then suspended until the next FETCH statement is executed for the calling cursor, then flow of control within the result set procedure continues until the next RETURN statement is encountered, or until the end of the procedure is reached.
After flow of control has exited from the scope of a result set procedure the next attempt to FETCH more data into the calling cursor will flag end-of-set.
Thus, a result set procedure call can be used in place of the usual SELECT when declaring a cursor.
The following example, using ESQL, is intended to demonstrate how execution within the result set procedure proceeds, and is suspended, in response to FETCH statements being executed for the calling cursor:
EXEC SQL
CREATE PROCEDURE result_proc(x INTEGER)
RETURNS TABLE (txt VARCHAR(10), xp INTEGER)
CONTAINS SQL
BEGIN
DECLARE xp INTEGER DEFAULT x;
RETURN ('FIRST ROW', xp);
SET xp = x * 2;
RETURN ('SECOND ROW', xp);
SET xp = x * 3;
RETURN ('THIRD ROW', XP);
END;
EXEC SQL DECLARE c_1 CURSOR FOR CALL result_proc(3);
EXEC SQL OPEN c_1;
EXEC SQL WHENEVER NOT FOUND GOTO done;
EXEC SQL FETCH c_1
INTO :T, :X;
(This will fetch 'FIRST ROW', 3)
Result set procedure flow of control suspended at XP=X*2
EXEC SQL FETCH c_1
INTO :T, :X;
(This will fetch 'SECOND ROW', 6)
Result set procedure flow of control suspended at XP=X*3
EXEC SQL FETCH c_1
INTO :T, :X;
(This will fetch 'THIRD ROW', 9)
Result set procedure flow of control suspended at END;
EXEC SQL FETCH c_1
INTO :T, :X;
Flow of control exits from procedure scope and the NOT FOUND exception is raised.
done:
EXEC SQL CLOSE c_1;
More typically, a loop construct would be used in the result set procedure to deal with RETURN statements. It is also permissible to use a cursor within the result set procedure to get data to be returned via a SELECT.
Closing the cursor for a result set procedure will close any open cursors declared within it and no further execution of the procedure will occur.
Reopening the cursor will start execution of the result set procedure afresh from the beginning (i.e. no state information is saved between a close and reopen).
An exception is raised if an error occurs when executing an SQL statement. Every exception is identified by an exception condition, expressed in terms of its SQLSTATE value.
About SQLSTATES
An SQLSTATE value is represented by the keyword SQLSTATE followed by a 5-character string containing only uppercase alphanumeric characters. The first two characters of the string identify the exception class and the last three the exception sub-class.
In Mimer SQL, the range of possible SQLSTATE values is divided into standard values and implementation-defined values. The implementation-defined values are those beginning with the characters J-R, T-Z, 5-6 and 8-9. For a list of the values, see Mimer SQL Reference Manual, SQLSTATE Return Codes.
Whenever an exception is raised, the exception condition is placed in the diagnostics area and the SQLSTATE value can be retrieved by using the RETURNED_SQLSTATE option of the GET DIAGNOSTICS statement.
Condition Names
In addition to expressing an exception condition in terms of its SQLSTATE value, it is possible (within a compound SQL statement) to declare a condition name to represent it.
Whenever a condition name is used, it is immediately translated into the SQLSTATE value it represents. For more information, see Declaring Condition Names.
It is possible to raise an exception without an error occurring by using the SIGNAL statement. When the SIGNAL statement is used, the specified exception condition is placed in the cleared diagnostics area, expressed as its SQLSTATE value, and control proceeds as if an error had just occurred.
It possible to return specific error messages with the SIGNAL statement by using the optional SET clause.
Example
SIGNAL SQLSTATE 'UE456'
SET message_text = 'The specified horse, ' || horse ||
' does not exist in the database';
Exception Handlers and Actions
It is possible to declare exception handlers in a compound SQL statement that perform some action when exceptions are raised. The action defined by the exception handler is associated with one or more specific exception conditions, or one or more exception class groups, specified when the exception handler is declared. For more information, see Declaring Exception Handlers.
If there is an exception handler action defined for an exception condition that is raised, the exception handler action is performed and execution continues in the manner defined by the type of the exception handler.
If no exception handler action has been defined for an exception condition that is raised, the default error handling mechanism is invoked (which usually makes the exception condition visible to the calling environment).
If the exception NOT FOUND or an SQLWARNING is raised in an unhandled situation, execution will continue and the exception will be cleared by execution of the next statement in the procedure. The GET DIAGNOSTICS statement can be used to test for the NOT FOUND exception and an SQLWARNING.
It may be necessary for an exception handler action to re-raise the current exception condition or to raise an alternative exception condition. The RESIGNAL statement is provided for this purpose and it may only be executed from within an exception handler.
If RESIGNAL is executed without specifying an exception condition, the current exception condition remains in the diagnostics area and the error handling mechanism proceeds to deal with the error as if the current exception handler action had not been found.
If an exception condition is specified (in the same way as for SIGNAL), this is pushed onto the top of the stack of exceptions in the diagnostics area, becoming the current SQLSTATE value, and the error handling mechanism proceeds as just described.
The size of the exceptions stack in the diagnostics area is set by using the SET TRANSACTION DIAGNOSTICS SIZE statement, see Exception Diagnostics Within Transactions.
Use of RESIGNAL is useful in situations where there are nested exception handler actions defined and it is required that an enclosing exception handler action be invoked from an inner one, or where the default error handling mechanism is to be allowed to proceed from some point within a defined exception handler action. As with the SIGNAL statement it is possible to supply a specific message text.
Example
RESIGNAL;
RESIGNAL SQLSTATE 'UE456'
SET message_text = 'The horse ' || horse || ' does not exist';
As discussed in the previous section, exception conditions are identified by an SQLSTATE value. Whenever an exception is raised, the exception condition that identifies it is stored in the diagnostics area in the form of its SQLSTATE value.
It is always possible to specify an exception condition by using its SQLSTATE value, e.g. SQLSTATE VALUE 'S0700', however it is often desirable to declare a condition name that represents the SQLSTATE value in a way that more meaningfully describes the exception.
Condition names may be declared in a compound SQL statement, see the Mimer SQL Reference Manual, COMPOUND STATEMENT, for a detailed description.
Example
DECLARE invalid_parameter CONDITION FOR SQLSTATE 'UE456';
...
SIGNAL invalid_parameter;
Following this declaration, the condition name INVALID_PARAMETER can be used instead of the SQLSTATE value SQLSTATE VALUE 'UE456' whenever there is a need to refer to this exception condition.
If a condition name is used in a signal statement the associated SQLSTATE value and the condition name is placed in the diagnostics area. If the condition does not have an associated SQLSTATE value, the SQLSTATE value 45000 is used. A condition is always local to a routine, i.e. consider the following example:
create procedure p2()
begin
declare condition c1;
...
signal c1;
end
create procedure p1()
begin
declare condition c1;
declare exit handler for c1
begin
...
call p2();
...
end
end
In this case the exit handler in the procedure p1 will not be invoked when the statement signal c1 is executed.In order to catch a signaled condition the associated SQLSTATE must be used. The condition identifier can be propagated by using a RESIGNAL statement.
All SQLSTATE values in Mimer SQL that lie outside the range of standard values are treated as implementation-defined, so all SQLSTATE values are handled in the same way and may be specified explicitly in all situations.
Exception handlers may be declared in a compound SQL statement in order to define an action which will be executed if specified exceptions are raised within the scope of the exception handler.
The structure of the handler action is the same as the body of a routine, i.e. a single executable procedural SQL statement. The exceptions to which the handler action will respond may be specified as a list of exception conditions or by specifying one or more exception class groups.
The exception class groups are:
•SQLWARNING covers SQLSTATE values beginning with 01.
•NOT FOUND covers SQLSTATE values beginning with 02.
•SQLEXCEPTION covers all other SQLSTATE values (including those in the implementation defined range), excluding those beginning with 00.
An exception handler that is declared to respond to one or more exception class groups is referred to as a general exception handler.
An exception condition may be specified by its SQLSTATE value or a condition name declared to represent it. An exception handler which is declared to respond to one or more specific exception conditions is referred to as a specific exception handler.
The same exception condition must not be specified more than once in the same exception handler declaration.
An exception handler can either be a general exception handler or a specific exception handler, i.e. an exception handler declaration cannot contain both exception class groups and specific exception conditions.
Exception handlers are declared in the local handler declaration list of a compound SQL statement and the scope of an exception handler is that compound SQL statement plus all the SQL statements contained within it except when another routine is invoked. When a user defined routine is invoked all exception handlers in the calling routine will get out of scope and they will get into scope again when the invoked routine has finished executing, e.g:
CREATE PROCEDURE innerMost(INT x)
BEGIN
-- no handlers in this routine
IF x > 0 THEN
SIGNAL SQLSTATE 'UE345';
ELSE
SIGNAL SQLSTATE 'UE543';
END IF;
END
CREATE PROCEDURE outerMost()
BEGIN
DECLARE EXIT HANDLER FOR SQLSTATE 'UE345' BEGIN END;
DECLARE CONTINUE HANDLER FOR SQLSTATE 'UE543' BEGIN END;
CALL innerMost(0);
CALL innerMost(1);
CALL innerMost(2);
END
When the signal statement with exception UE543 in the innerMost routine is executed, the execution of this routine will be stopped as there is no handlers declared. The exception will the be propagated to the outerMost routine which has a continue handler for this exception. This means that the execution will proceed with the next call statement. This will cause a new exception (UE345) being signaled. Again this exception will be propagated to the calling routine and the first exception handler will be invoked. As this is an exit handler the execution will continue after the end of the compound statement in the outerMost routine, i.e. the statement call innerMost(2) will never be executed.
The exception handler will be executed if one of the exceptions it is declared to respond to is raised within the scope of the handler.
A local handler declaration list can only contain one exception handler declared to respond to a particular exception condition or exception class group.
It is possible to declare a general and a specific exception handler, both of which cover the same scope, where an exception condition specified for the specific handler is in one of the exception class groups specified for the general handler. If the exception condition is raised in this situation, the specific handler is executed in preference to the general handler.
It is possible for the scope of two specific exception handlers, which respond to the same exception condition, to overlap. This will be the case if there are two nested compound SQL statements and each declares a specific exception handler for the same exception condition (this is permitted, provided the two exception handlers are not declared in the same local handler declaration list). In this situation the innermost exception handler action will be executed.
The same is true for two general exception handlers in this situation.
The RESIGNAL statement can be used in situations like this, in the inner exception handler action, to get the outer exception handler action to execute by propagating the exception out from the exception handler action which is currently executing.
Exception handlers fall into the following types:
•Exit Handler
This type of exception handler will execute when the exception condition(s) that apply to it are raised. After the handler has executed, flow of control exits the scope of the compound SQL statement containing the exception handler declaration, by effectively performing a LEAVE, see Scope in Routines – the Compound SQL Statement.
•Continue Handler
This type of exception handler will execute when the exception condition(s) that apply to it are raised. After the handler has executed, flow of control continues by executing the SQL statement immediately following the SQL statement that raised the exception.
•Undo Handler
The execution of this type of handler will be initiated when the exception condition(s) that apply to it are raised. Before the handler action executes, all changes made by the executed SQL statements in the compound SQL statement, or by any SQL statements triggered by them, are canceled. The handler action is then executed and flow of control exits the scope of the compound SQL statement containing the exception handler declaration, by effectively performing a LEAVE, see Scope in Routines – the Compound SQL Statement.
Note:An UNDO exception handler can only be declared in a compound SQL statement that has been defined as ATOMIC, see The ATOMIC Compound SQL Statement.
Examples of Exception Handlers
s1:
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
...
END;
...
END s1;
s2:
BEGIN
DECLARE CONTINUE HANDLER FOR SQLSTATE 'S0700'
BEGIN
...
END;
...
END s2;
s3:
BEGIN
DECLARE EXIT HANDLER FOR SQLSTATE 'S0700'
BEGIN
...
END;
...
s4:
BEGIN ATOMIC
DECLARE UNDO HANDLER FOR SQLSTATE 'S0700'
BEGIN
...
END;
...
END s4;
...
END s3;
Create a function iadd that adds two integer values, in an overflow and underflow safe way, using an exit handler. The SQLSTATE value 22003 means “numeric value out of range”:
create function iadd(p1 int, p2 int) returns int
begin
declare exit handler for sqlstate value '22003'
return case when p1 < 0 and p2 < 0 then -2147483648
else 2147483647
end;
return p1 + p2;
end
Using the GET DIAGNOSTICS Statement
The GET DIAGNOSTICS statement can be used in an exception handler to get the specific SQLSTATE value that provoked execution of the exception handler.
Example
Create a function iadd that adds two integer values, in an overflow and underflow safe way, using an exit handler. The SQLSTATE value 22003 means “numeric value out of range”, the native error -10302 means overflow, and the native error -10303 means underflow:
create function iadd(p1 int,p2 int) returns int
begin
declare exit handler for sqlstate value '22003'
begin
declare a int;
get diagnostics exception 1 a = native_error;
return case when a = -10303 then -2147483648
when a = -10302 then 2147483647
end;
end;
return p1 + p2;
end
Example
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
DECLARE v_state CHAR(5) DEFAULT '?????';
GET DIAGNOSTICS EXCEPTION 1 v_state = RETURNED_SQLSTATE;
CASE v_state
WHEN '22003' THEN ...
WHEN '20000' THEN ...
ELSE RESIGNAL;
END CASE;
END; -- of sqlexception handler
Note that GET DIAGNOSTICS must be the first statement in the exception handler as the diagnostics area always contains information about the latest statement.
The GET DIAGNOSTICS statement can also be used to get information about warnings and not found exceptions.
Example
SELECT format into v_format FROM formats where category_id = v_category_id;
GET DIAGNOSTICS EXCEPTION 1 v_state = RETURNED_SQLSTATE;
IF v_state = '02000' THEN
-- not found
ELSE
-- found
END IF;
As mentioned, to describe an error always use GET DIAGNOSTICS in an exception handler. I.e. it is not meaningful to place GET DIAGNOSTICS after a statement to check for errors. Example:
BEGIN
DECLARE v_state CHAR(5);
DECLARE EXIT HANDLER FOR sqlexception
BEGIN
...
END;
INSERT INTO format(format,category_id) VALUES (v_format,v_category_id);
GET DIAGNOSTICS EXCEPTION 1 v_state = RETURNED_SQLSTATE;
END
If an exception occurs in the INSERT statement this will be catched by the exception handler and as this is an exit handler the execution will resume after the compound statement. Thus, the diagnostics statements will never be invoked in this case. Even if it is a continue handler the GET DIAGNOSTICS statement is superfluous as the handler would clear the diagnostics information.
The ident creating a routine must, as is usual, have the appropriate access rights on the tables and other database objects referenced from the SQL statements in the routine. The creating ident must also have the right to create objects in the schema to which the routine is to belong (i.e. the ident must be the creator of the schema).
The right of the creator to access referenced database objects is verified when the CREATE FUNCTION, CREATE MODULE or the CREATE PROCEDURE statement is executed.
If an ident wishes to invoke a routine, that ident must have EXECUTE privilege on the routine.
Note:In order for the creator of a routine to grant EXECUTE privilege on the routine to another ident, the creator must have the WITH GRANT option in affect for all the access rights held on all the database objects referenced within the routine.
The above note is an important security point, because granting EXECUTE privilege on a routine is effectively granting appropriate access rights to the given ident on all the database objects referenced in the routine, therefore all those access rights must be held by the grantor with the WITH GRANT option.
An ident may be granted EXECUTE privilege on a routine with the WITH GRANT option and if this option is in affect, the ident may grant EXECUTE privilege on that routine to other idents.
Routines can be used as a security layer in the database. By having EXECUTE privilege on a routine granted, an ident only gets the right to perform the specific operations specified in the routine and not general access to the referenced database objects.
Note:It is not possible to grant EXECUTE privilege on a module, only on routines.
Care must be taken if database objects are dropped with the CASCADE option, and when REVOKE is performed, particularly with respect to routines and modules.
It is important to bear in mind the following points in connection with modules and routines:
•Dropping an object referenced by an SQL statement in a routine will cause the routine to be dropped.
•If the access rights on a database object are revoked from the creator of a routine that contains an SQL statement referencing the object, the routine will be dropped.
•If a routine belonging to a module is dropped because of the effects of a cascade, the routine is effectively removed from the module (i.e. the module is not dropped).
If an ident attempts to drop a routine for which there is a compiled version currently being held by another ident, the DROP operation will fail because the routine is in use.
When a routine is invoked, it is compiled and the compiled version of the routine is held by the invoking ident. Any other idents invoking a routine while a compiled version of it exists will use the existing compiled version and this will be held by them as well.
A compiled version of a routine will generally be held by an ident until the ident disconnects. If the routine invocation is contained in a dynamic SQL statement, deallocating the statement will release the compiled version of the routine immediately without the need for a disconnect.
Using Mimer SQL’s Java-based graphic PSM Debugger, you can select and run a stored function or stored procedure in an environment that enables you to:
•view the stored source of the routine
•watch the values of the input parameters and declared variables
•observe the results of executing the routine.
You can interactively set breakpoints in the routine being debugged or in other routines or triggers invoked by this routine. When a breakpoint is set the execution will halt at this line, if encountered in the flow of execution.
You can execute a routine in step-wise fashion from the beginning or from the point at which a breakpoint halts execution.
When execution of a routine is interrupted or when a routine is executed in a step-wise fashion, an indicator next to the source line will show the current flow of control position.
The PSM Debugger requires a Java 2 (version 1.2 or later) compatible Java runtime environment.
|
Linux:The PSM Debugger is a Java-based program and must be used in an X-Windows environment. |
|
Win:You can download the Java runtime environment files from: https://www.java.com |
To start the PSM Debugger:
|
Linux:Enter the following command: java -jar /usr/lib/psmdebug.jar
or, use the psmdbg command. On Linux and macOS, the PSM Debugger can also be started from the Start Menu. |
|
VMS:The PSM debugger is not included in the VMS distribution. PSM procedures can be debugged remotely from a workstation using another graphical operating system. |
|
Win:Click Start, navigate to where you installed Mimer SQL and select SQL-PSM Debugger. |
The PSM Debugger window opens and the log in dialog box is displayed.
Logging in to the Mimer SQL PSM Debugger establishes a connection to a database server and enables you to access the routines stored in the database.
To log in:
1In the login dialog box, enter the following details:
|
Database |
The name of a database that is accessible from the node you are running on. The syntax for the database URL in the login dialog box is: hostname[:port]/database
If the database resides on your local machine, specify localhost as the host name. For example: localhost/testdb |
|
Username |
The name of the ident you wish to use to access the database. |
|
Password |
The password to be used for the specified ident. |
2Click OK to connect to the database, or Cancel to quit the Mimer SQL PSM Debugger.
Once you have logged in to the Mimer SQL PSM Debugger, you will be accessing the database as the ident you specified in the log in dialog box and you can choose a routine to debug by selecting it from the Choose a procedure drop-down list.
Choose a stored function or stored procedure to debug by selecting it from the drop-down list.
The list displays the routines for which you hold EXECUTE privilege. When you have selected a routine, you must specify values for all the input parameters.
Specifying the Input Parameters
When you select a routine with input parameters, a dialog box will list the name and data type of each input parameter and you must specify values for them.
When you have specified values for all the input parameters, click OK to view the source for the routine, or click Cancel to go back to selecting a routine from the drop-down list.
Viewing the Source Code for a Routine
When you have selected a routine and specified the input parameter values, the routine source is displayed.
It is possible to watch the values of declared variables and routine parameters declared as input or input/output by selecting them from the Variable details drop-down list.
You can set a breakpoint on a line of the routine source by clicking on the indicator to the left of the source line in the source window.
Watching Variables and Input Parameters
Once you have selected a variable or parameter from the drop-down list, its name and current value (when defined) are shown in the table below the list.
The watched values are updated in the table as the routine executes.
To set a breakpoint in a routine or trigger invoked by the current routine, you can choose a routine or a trigger from the list in the Breakpoints menu.
When you click on the indicator to left of a source line in the source window, the indicator will change color.
If the indicator is red, there is a breakpoint set on that source line which will halt execution of the routine when it is encountered.
If the indicator next to a source line is white, then no breakpoint is set on that line.
To execute a routine:
•Click Go to execute the routine to the end or to the next breakpoint.
•Click Step Into to execute the next line. If this line contains a call statement or a function invocation, the execution will halt at the first line in the invoked routine.
•Click Step Over to execute the next line. This mode will not stop the execution if there is a routine invocation, unless there is a breakpoint set.
•Click Cancel to force continuous routine execution to stop.
Whenever the value of a watched variable or parameter changes, the value shown for it in the table will be updated and will be displayed in red. Unchanged values will be displayed in black.
When execution of a routine is halted by a breakpoint, flow of control is positioned just before execution of the source line on which the breakpoint is set. An arrow to the left of the source line shows where execution has been halted.
To continue executing a routine that has been halted at a breakpoint, click Go, Step Into or Step Over.
Whenever execution of a routine is halted, because a breakpoint was encountered or during step-wise execution, the source line at which the routine is halted appears with an arrow to the left of it. The current flow of control position is just prior to execution of that source line.
The results of executing the routine are shown in the window below the routine selection drop-down list. The Mimer SQL PSM Debugger gives the same results feedback during execution of a routine as Mimer BSQL.